 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonte-Carlo Search for an Equilibrium in Dec-POMDPs
May 19, 2023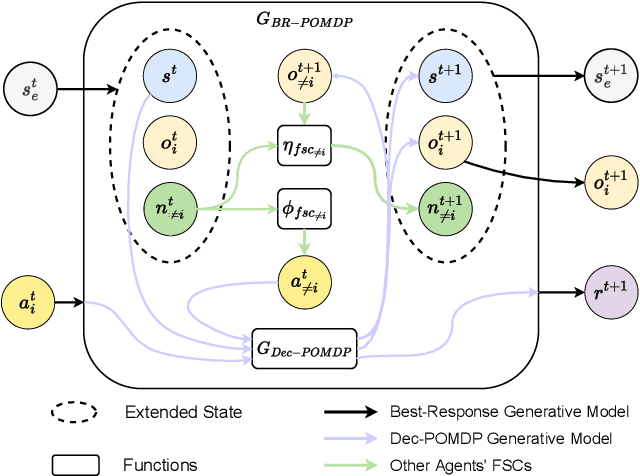
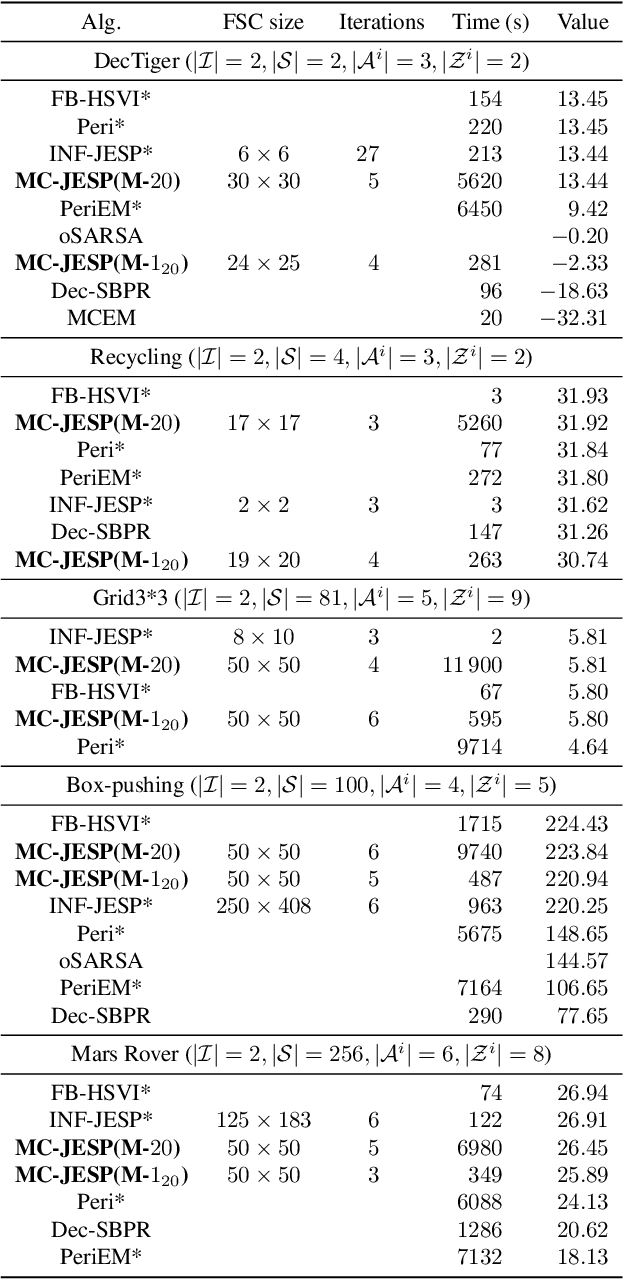
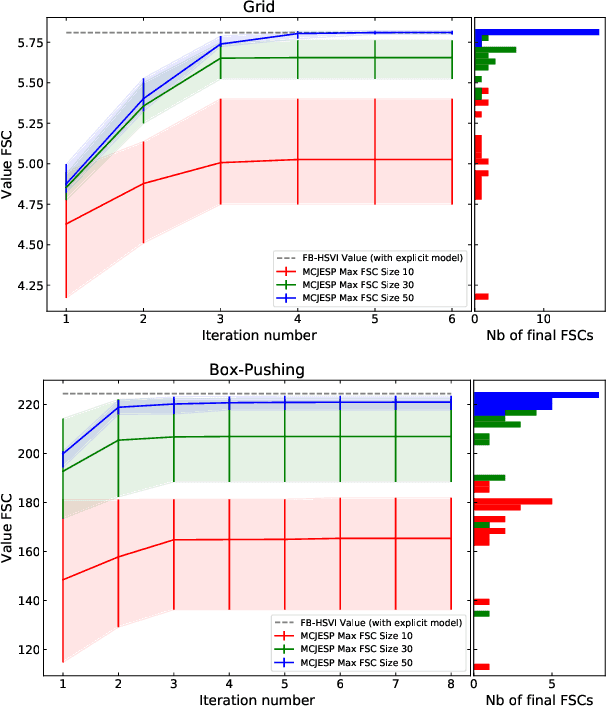
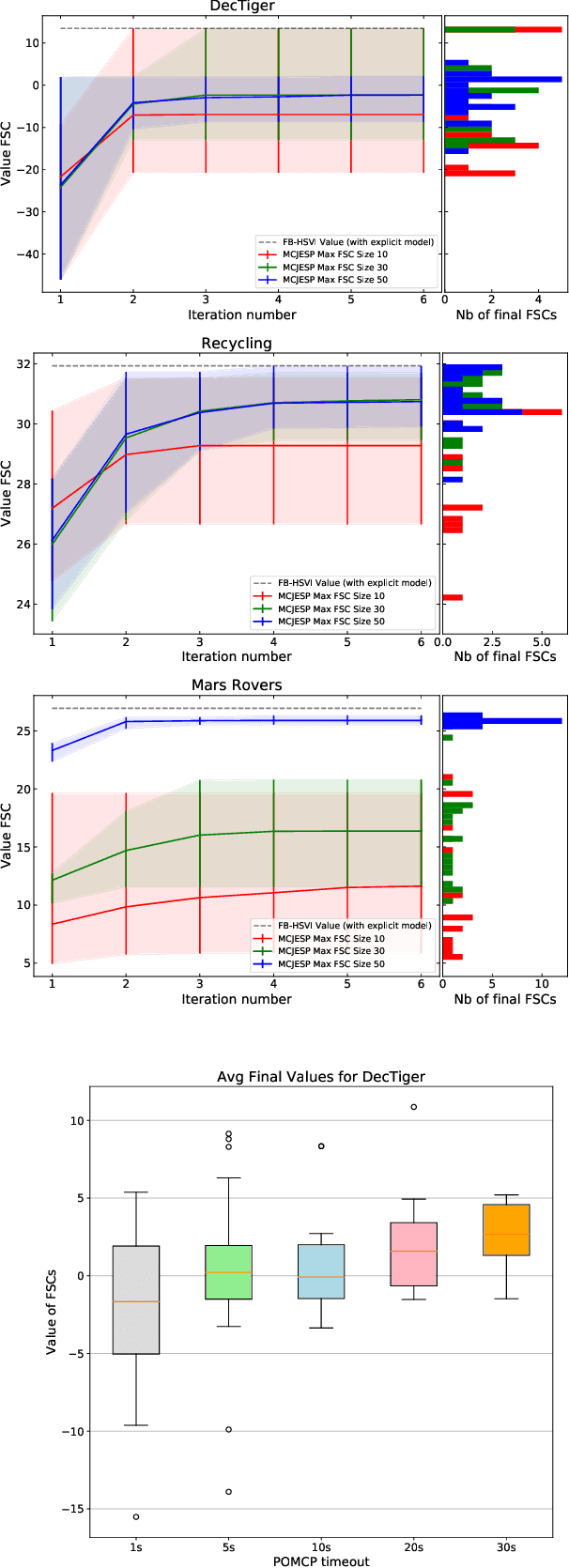
Decentralized partially observable Markov decision processes (Dec-POMDPs) formalize the problem of designing individual controllers for a group of collaborative agents under stochastic dynamics and partial observability. Seeking a global optimum is difficult (NEXP complete), but seeking a Nash equilibrium -- each agent policy being a best response to the other agents -- is more accessible, and allowed addressing infinite-horizon problems with solutions in the form of finite state controllers. In this paper, we show that this approach can be adapted to cases where only a generative model (a simulator) of the Dec-POMDP is available. This requires relying on a simulation-based POMDP solver to construct an agent's FSC node by node. A related process is used to heuristically derive initial FSCs. Experiment with benchmarks shows that MC-JESP is competitive with exisiting Dec-POMDP solvers, even better than many offline methods using explicit models.
Robust Robot Planning for Human-Robot Collaboration
Feb 27, 2023
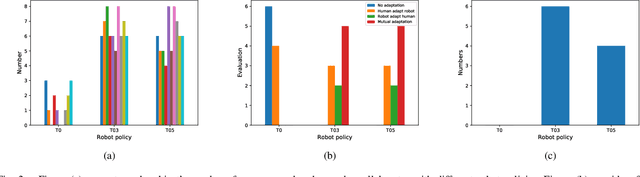
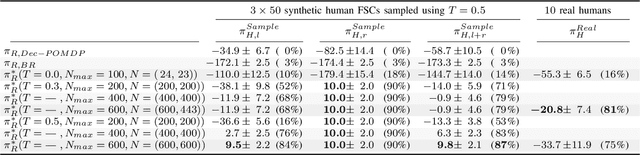
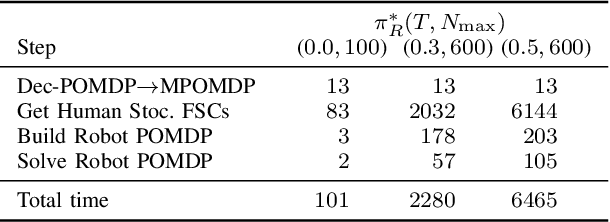
In human-robot collaboration, the objectives of the human are often unknown to the robot. Moreover, even assuming a known objective, the human behavior is also uncertain. In order to plan a robust robot behavior, a key preliminary question is then: How to derive realistic human behaviors given a known objective? A major issue is that such a human behavior should itself account for the robot behavior, otherwise collaboration cannot happen. In this paper, we rely on Markov decision models, representing the uncertainty over the human objective as a probability distribution over a finite set of objective functions (inducing a distribution over human behaviors). Based on this, we propose two contributions: 1) an approach to automatically generate an uncertain human behavior (a policy) for each given objective function while accounting for possible robot behaviors; and 2) a robot planning algorithm that is robust to the above-mentioned uncertainties and relies on solving a partially observable Markov decision process (POMDP) obtained by reasoning on a distribution over human behaviors. A co-working scenario allows conducting experiments and presenting qualitative and quantitative results to evaluate our approach.
Solving infinite-horizon Dec-POMDPs using Finite State Controllers within JESP
Sep 17, 2021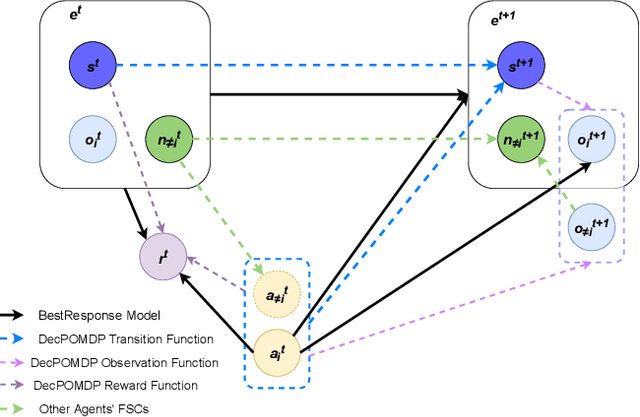
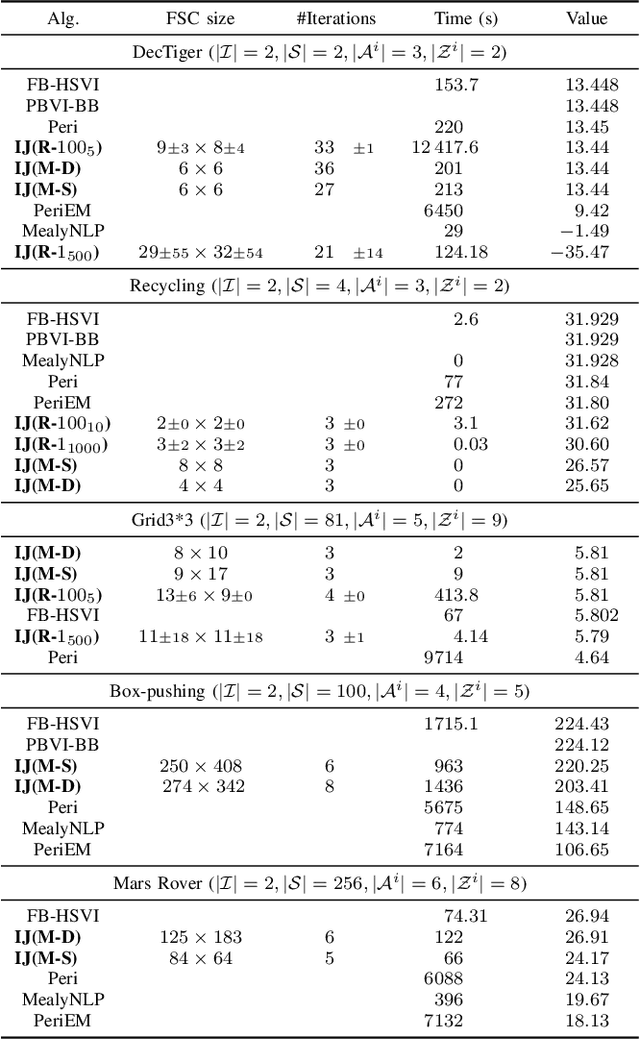
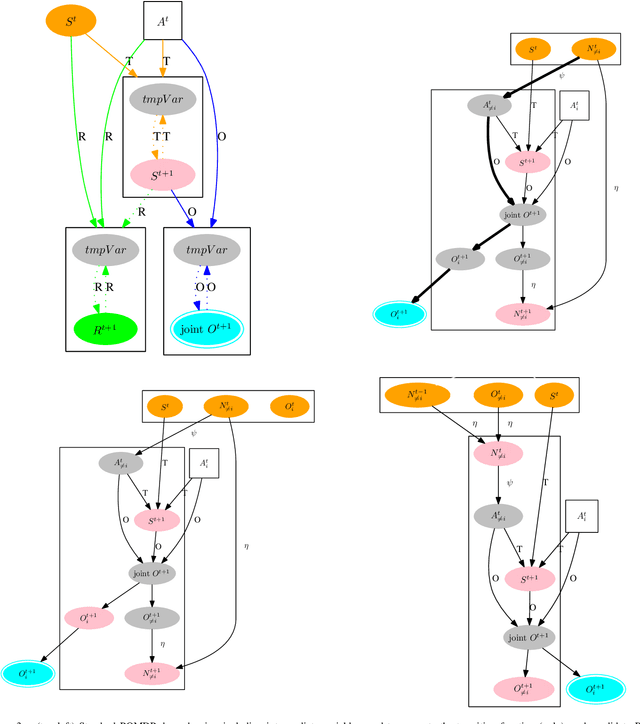
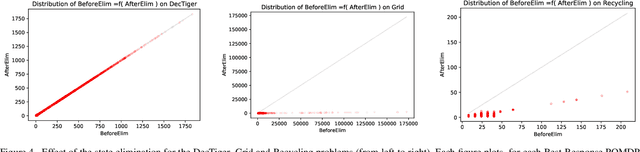
This paper looks at solving collaborative planning problems formalized as Decentralized POMDPs (Dec-POMDPs) by searching for Nash equilibria, i.e., situations where each agent's policy is a best response to the other agents' (fixed) policies. While the Joint Equilibrium-based Search for Policies (JESP) algorithm does this in the finite-horizon setting relying on policy trees, we propose here to adapt it to infinite-horizon Dec-POMDPs by using finite state controller (FSC) policy representations. In this article, we (1) explain how to turn a Dec-POMDP with $N-1$ fixed FSCs into an infinite-horizon POMDP whose solution is an $N^\text{th}$ agent best response; (2) propose a JESP variant, called \infJESP, using this to solve infinite-horizon Dec-POMDPs; (3) introduce heuristic initializations for JESP aiming at leading to good solutions; and (4) conduct experiments on state-of-the-art benchmark problems to evaluate our approach.
A Variational Time Series Feature Extractor for Action Prediction
Sep 26, 2018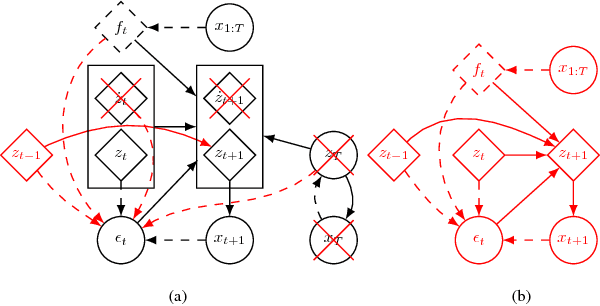

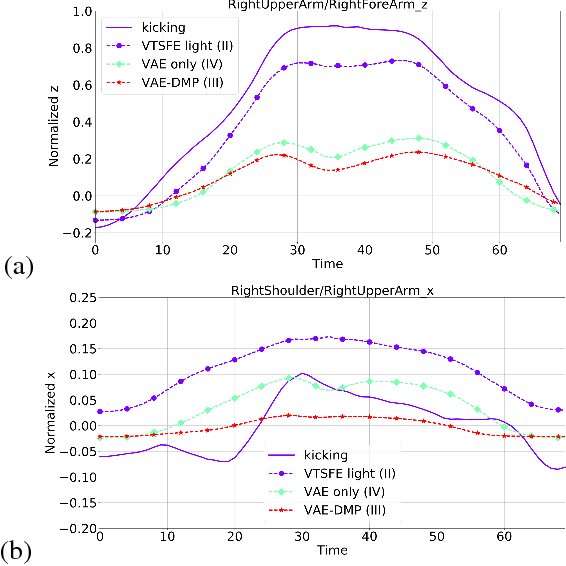
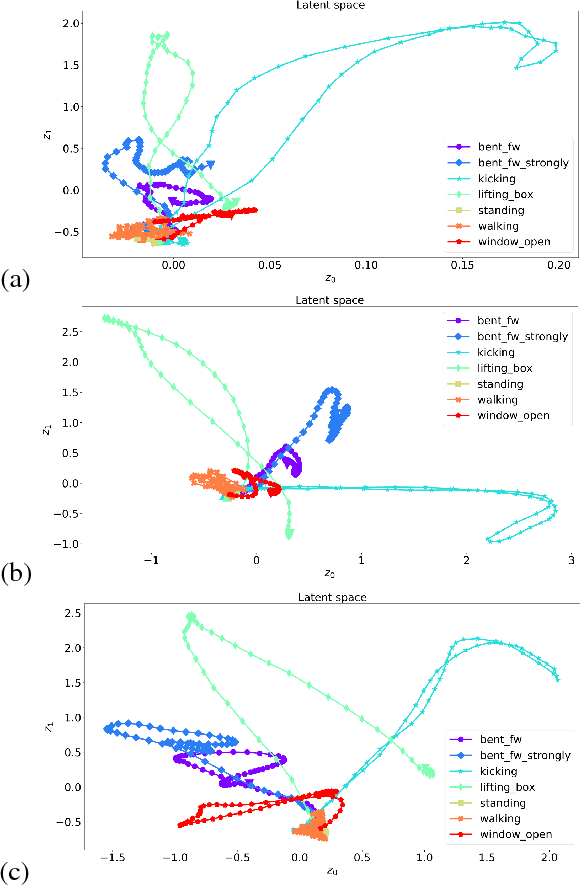
We propose a Variational Time Series Feature Extractor (VTSFE), inspired by the VAE-DMP model of Chen et al., to be used for action recognition and prediction. Our method is based on variational autoencoders. It improves VAE-DMP in that it has a better noise inference model, a simpler transition model constraining the acceleration in the trajectories of the latent space, and a tighter lower bound for the variational inference. We apply the method for classification and prediction of whole-body movements on a dataset with 7 tasks and 10 demonstrations per task, recorded with a wearable motion capture suit. The comparison with VAE and VAE-DMP suggests the better performance of our method for feature extraction. An open-source software implementation of each method with TensorFlow is also provided. In addition, a more detailed version of this work can be found in the indicated code repository. Although it was meant to, the VTSFE hasn't been tested for action prediction, due to a lack of time in the context of Maxime Chaveroche's Master thesis at INRIA.