 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformed Low-Rank Parameterization Can Help Robust Generalization for Tensor Neural Networks
Mar 01, 2023
Achieving efficient and robust multi-channel data learning is a challenging task in data science. By exploiting low-rankness in the transformed domain, i.e., transformed low-rankness, tensor Singular Value Decomposition (t-SVD) has achieved extensive success in multi-channel data representation and has recently been extended to function representation such as Neural Networks with t-product layers (t-NNs). However, it still remains unclear how t-SVD theoretically affects the learning behavior of t-NNs. This paper is the first to answer this question by deriving the upper bounds of the generalization error of both standard and adversarially trained t-NNs. It reveals that the t-NNs compressed by exact transformed low-rank parameterization can achieve a sharper adversarial generalization bound. In practice, although t-NNs rarely have exactly transformed low-rank weights, our analysis further shows that by adversarial training with gradient flow (GF), the over-parameterized t-NNs with ReLU activations are trained with implicit regularization towards transformed low-rank parameterization under certain conditions. We also establish adversarial generalization bounds for t-NNs with approximately transformed low-rank weights. Our analysis indicates that the transformed low-rank parameterization can promisingly enhance robust generalization for t-NNs.
Continuous Conditional Random Field Convolution for Point Cloud Segmentation
Oct 12, 2021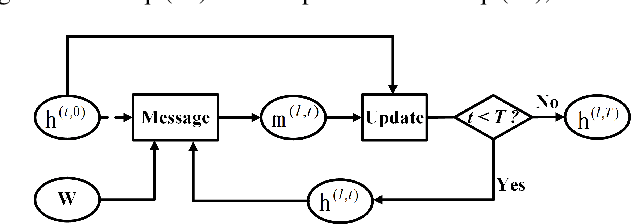
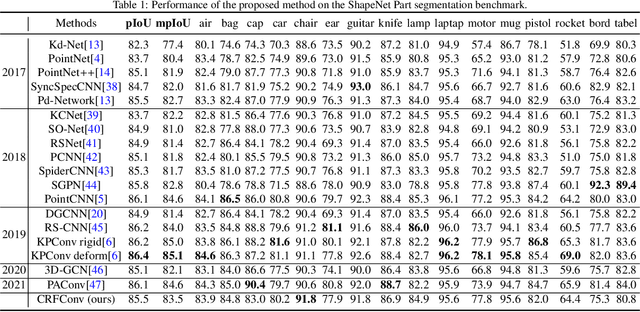
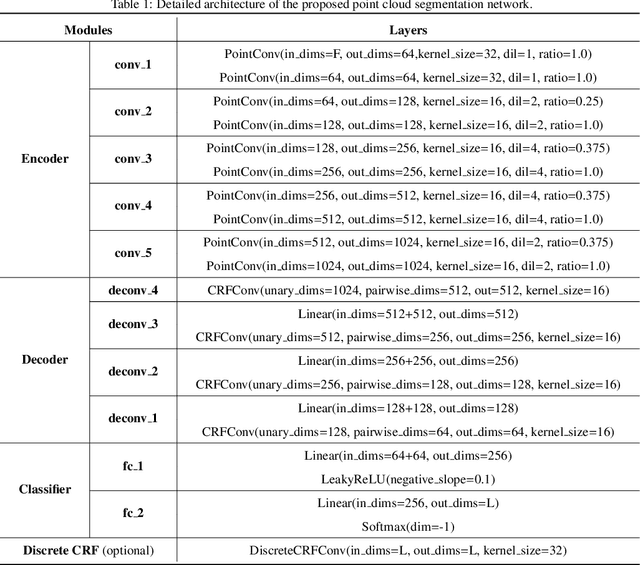

Point cloud segmentation is the foundation of 3D environmental perception for modern intelligent systems. To solve this problem and image segmentation, conditional random fields (CRFs) are usually formulated as discrete models in label space to encourage label consistency, which is actually a kind of postprocessing. In this paper, we reconsider the CRF in feature space for point cloud segmentation because it can capture the structure of features well to improve the representation ability of features rather than simply smoothing. Therefore, we first model the point cloud features with a continuous quadratic energy model and formulate its solution process as a message-passing graph convolution, by which it can be easily integrated into a deep network. We theoretically demonstrate that the message passing in the graph convolution is equivalent to the mean-field approximation of a continuous CRF model. Furthermore, we build an encoder-decoder network based on the proposed continuous CRF graph convolution (CRFConv), in which the CRFConv embedded in the decoding layers can restore the details of high-level features that were lost in the encoding stage to enhance the location ability of the network, thereby benefiting segmentation. Analogous to the CRFConv, we show that the classical discrete CRF can also work collaboratively with the proposed network via another graph convolution to further improve the segmentation results. Experiments on various point cloud benchmarks demonstrate the effectiveness and robustness of the proposed method. Compared with the state-of-the-art methods, the proposed method can also achieve competitive segmentation performance.
* 20 pages + 8 pages (supplemental material)
WakaVT: A Sequential Variational Transformer for Waka Generation
Apr 01, 2021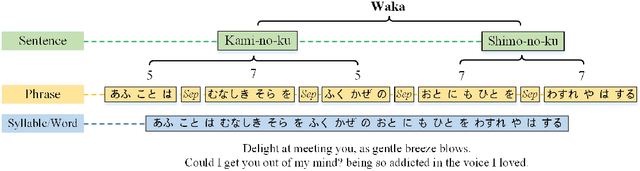

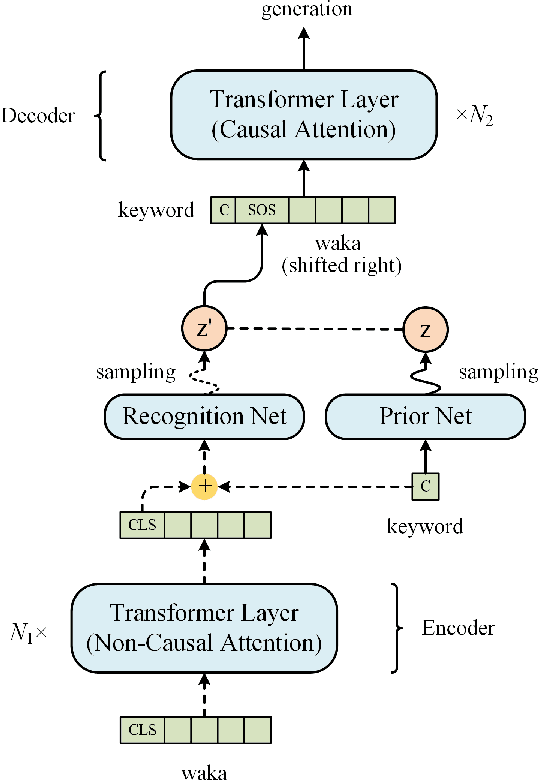

Poetry generation has long been a challenge for artificial intelligence. In the scope of Japanese poetry generation, many researchers have paid attention to Haiku generation, but few have focused on Waka generation. To further explore the creative potential of natural language generation systems in Japanese poetry creation, we propose a novel Waka generation model, WakaVT, which automatically produces Waka poems given user-specified keywords. Firstly, an additive mask-based approach is presented to satisfy the form constraint. Secondly, the structures of Transformer and variational autoencoder are integrated to enhance the quality of generated content. Specifically, to obtain novelty and diversity, WakaVT employs a sequence of latent variables, which effectively captures word-level variability in Waka data. To improve linguistic quality in terms of fluency, coherence, and meaningfulness, we further propose the fused multilevel self-attention mechanism, which properly models the hierarchical linguistic structure of Waka. To the best of our knowledge, we are the first to investigate Waka generation with models based on Transformer and/or variational autoencoder. Both objective and subjective evaluation results demonstrate that our model outperforms baselines significantly.