 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Superclasses for Learning from Hierarchical Databases
Nov 25, 2024In many large-scale classification problems, classes are organized in a known hierarchy, typically represented as a tree expressing the inclusion of classes in superclasses. We introduce a loss for this type of supervised hierarchical classification. It utilizes the knowledge of the hierarchy to assign each example not only to a class but also to all encompassing superclasses. Applicable to any feedforward architecture with a softmax output layer, this loss is a proper scoring rule, in that its expectation is minimized by the true posterior class probabilities. This property allows us to simultaneously pursue consistent classification objectives between superclasses and fine-grained classes, and eliminates the need for a performance trade-off between different granularities. We conduct an experimental study on three reference benchmarks, in which we vary the size of the training sets to cover a diverse set of learning scenarios. Our approach does not entail any significant additional computational cost compared with the loss of cross-entropy. It improves accuracy and reduces the number of coarse errors, with predicted labels that are distant from ground-truth labels in the tree.
Vision Transformers for femur fracture classification
Aug 07, 2021


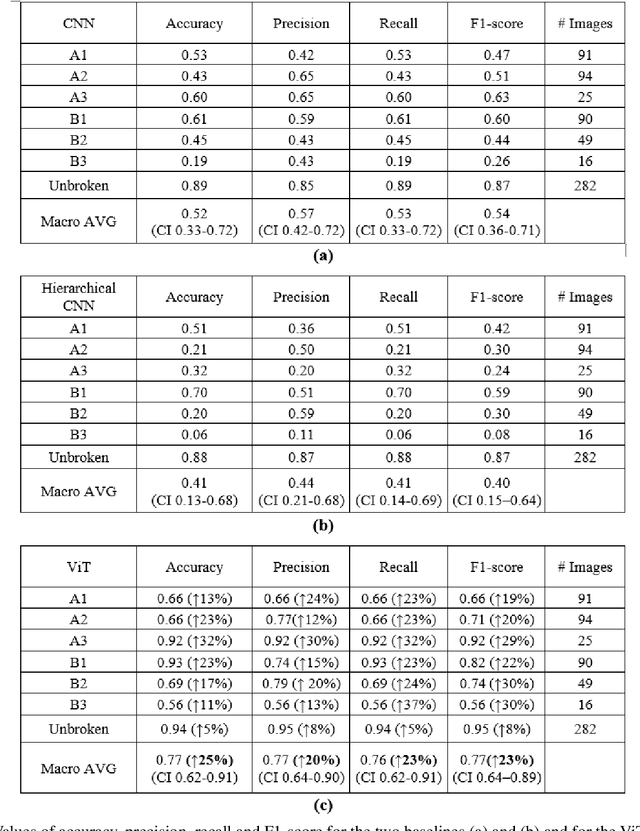
Objectives: In recent years, the scientific community has focused on the development of Computer-Aided Diagnosis (CAD) tools that could improve bone fractures' classification. However, the results of the classification of fractures in subtypes with the proposed datasets were far from optimal. This paper proposes a very recent and outperforming deep learning technique, the Vision Transformer (ViT), in order to improve the fracture classification, by exploiting its self-attention mechanism. Methods: 4207 manually annotated images were used and distributed, by following the AO/OTA classification, in different fracture types, the largest labeled dataset of proximal femur fractures used in literature. The ViT architecture was used and compared with a classic Convolutional Neural Network (CNN) and a multistage architecture composed by successive CNNs in cascade. To demonstrate the reliability of this approach, 1) the attention maps were used to visualize the most relevant areas of the images, 2) the performance of a generic CNN and ViT was also compared through unsupervised learning techniques, and 3) 11 specialists were asked to evaluate and classify 150 proximal femur fractures' images with and without the help of the ViT. Results: The ViT was able to correctly predict 83% of the test images. Precision, recall and F1-score were 0.77 (CI 0.64-0.90), 0.76 (CI 0.62-0.91) and 0.77 (CI 0.64-0.89), respectively. The average specialists' diagnostic improvement was 29%. Conclusions: This paper showed the potential of Transformers in bone fracture classification. For the first time, good results were obtained in sub-fractures with the largest and richest dataset ever.