 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDCL: Deep Dual Competitive Learning: A Differentiable End-to-End Framework for Unsupervised Prototype-Based Representation Learning
Apr 02, 2026A persistent structural weakness in deep clustering is the disconnect between feature learning and cluster assignment. Most architectures invoke an external clustering step, typically k-means, to produce pseudo-labels that guide training, preventing the backbone from directly optimising for cluster quality. This paper introduces Deep Dual Competitive Learning (DDCL), the first fully differentiable end-to-end framework for unsupervised prototype-based representation learning. The core contribution is architectural: the external k-means is replaced by an internal Dual Competitive Layer (DCL) that generates prototypes as native differentiable outputs of the network. This single inversion makes the complete pipeline, from backbone feature extraction through prototype generation to soft cluster assignment, trainable by backpropagation through a single unified loss, with no Lloyd iterations, no pseudo-label discretisation, and no external clustering step. To ground the framework theoretically, the paper derives an exact algebraic decomposition of the soft quantisation loss into a simplex-constrained reconstruction error and a non-negative weighted prototype variance term. This identity reveals a self-regulating mechanism built into the loss geometry: the gradient of the variance term acts as an implicit separation force that resists prototype collapse without any auxiliary objective, and leads to a global Lyapunov stability theorem for the reduced frozen-encoder system. Six blocks of controlled experiments validate each structural prediction. The decomposition identity holds with zero violations across more than one hundred thousand training epochs; the negative feedback cycle is confirmed with Pearson -0.98; with a jointly trained backbone, DDCL outperforms its non-differentiable ablation by 65% in clustering accuracy and DeepCluster end-to-end by 122%.
DDCL-INCRT: A Self-Organising Transformer with Hierarchical Prototype Structure (Theoretical Foundations)
Apr 02, 2026Modern neural networks of the transformer family require the practitioner to decide, before training begins, how many attention heads to use, how deep the network should be, and how wide each component should be. These decisions are made without knowledge of the task, producing architectures that are systematically larger than necessary: empirical studies find that a substantial fraction of heads and layers can be removed after training without performance loss. This paper introduces DDCL-INCRT, an architecture that determines its own structure during training. Two complementary ideas are combined. The first, DDCL (Deep Dual Competitive Learning), replaces the feedforward block with a dictionary of learned prototype vectors representing the most informative directions in the data. The prototypes spread apart automatically, driven by the training objective, without explicit regularisation. The second, INCRT (Incremental Transformer), controls the number of heads: starting from one, it adds a new head only when the directional information uncaptured by existing heads exceeds a threshold. The main theoretical finding is that these two mechanisms reinforce each other: each new head amplifies prototype separation, which in turn raises the signal triggering the next addition. At convergence, the network self-organises into a hierarchy of heads ordered by representational granularity. This hierarchical structure is proved to be unique and minimal, the smallest architecture sufficient for the task, under the stated conditions. Formal guarantees of stability, convergence, and pruning safety are established throughout. The architecture is not something one designs. It is something one derives.
The geometry of BERT
Feb 17, 2025Transformer neural networks, particularly Bidirectional Encoder Representations from Transformers (BERT), have shown remarkable performance across various tasks such as classification, text summarization, and question answering. However, their internal mechanisms remain mathematically obscure, highlighting the need for greater explainability and interpretability. In this direction, this paper investigates the internal mechanisms of BERT proposing a novel perspective on the attention mechanism of BERT from a theoretical perspective. The analysis encompasses both local and global network behavior. At the local level, the concept of directionality of subspace selection as well as a comprehensive study of the patterns emerging from the self-attention matrix are presented. Additionally, this work explores the semantic content of the information stream through data distribution analysis and global statistical measures including the novel concept of cone index. A case study on the classification of SARS-CoV-2 variants using RNA which resulted in a very high accuracy has been selected in order to observe these concepts in an application. The insights gained from this analysis contribute to a deeper understanding of BERT's classification process, offering potential avenues for future architectural improvements in Transformer models and further analysis in the training process.
Vision Transformers for femur fracture classification
Aug 07, 2021


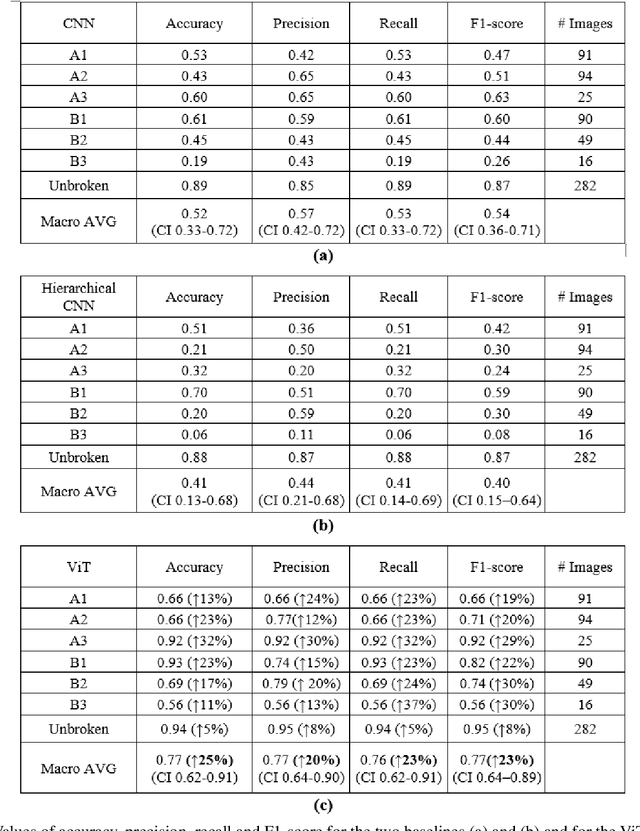
Objectives: In recent years, the scientific community has focused on the development of Computer-Aided Diagnosis (CAD) tools that could improve bone fractures' classification. However, the results of the classification of fractures in subtypes with the proposed datasets were far from optimal. This paper proposes a very recent and outperforming deep learning technique, the Vision Transformer (ViT), in order to improve the fracture classification, by exploiting its self-attention mechanism. Methods: 4207 manually annotated images were used and distributed, by following the AO/OTA classification, in different fracture types, the largest labeled dataset of proximal femur fractures used in literature. The ViT architecture was used and compared with a classic Convolutional Neural Network (CNN) and a multistage architecture composed by successive CNNs in cascade. To demonstrate the reliability of this approach, 1) the attention maps were used to visualize the most relevant areas of the images, 2) the performance of a generic CNN and ViT was also compared through unsupervised learning techniques, and 3) 11 specialists were asked to evaluate and classify 150 proximal femur fractures' images with and without the help of the ViT. Results: The ViT was able to correctly predict 83% of the test images. Precision, recall and F1-score were 0.77 (CI 0.64-0.90), 0.76 (CI 0.62-0.91) and 0.77 (CI 0.64-0.89), respectively. The average specialists' diagnostic improvement was 29%. Conclusions: This paper showed the potential of Transformers in bone fracture classification. For the first time, good results were obtained in sub-fractures with the largest and richest dataset ever.
Gradient-based Competitive Learning: Theory
Sep 06, 2020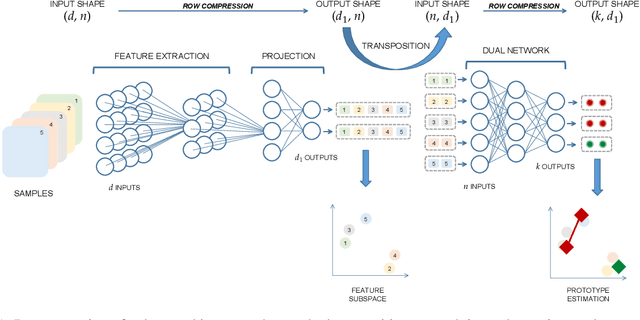
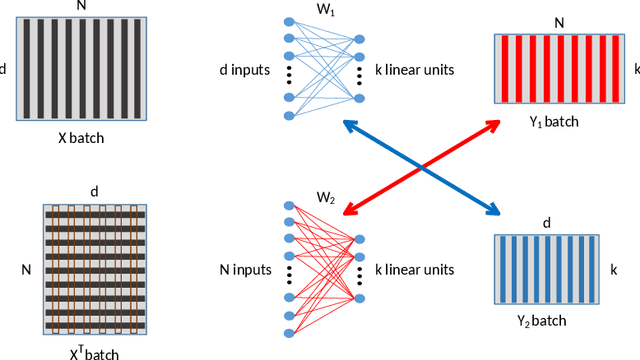
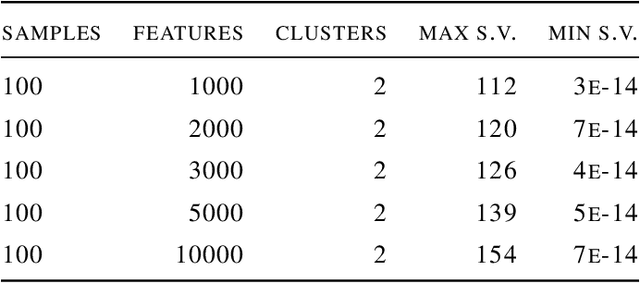
Deep learning has been widely used for supervised learning and classification/regression problems. Recently, a novel area of research has applied this paradigm to unsupervised tasks; indeed, a gradient-based approach extracts, efficiently and autonomously, the relevant features for handling input data. However, state-of-the-art techniques focus mostly on algorithmic efficiency and accuracy rather than mimic the input manifold. On the contrary, competitive learning is a powerful tool for replicating the input distribution topology. This paper introduces a novel perspective in this area by combining these two techniques: unsupervised gradient-based and competitive learning. The theory is based on the intuition that neural networks are able to learn topological structures by working directly on the transpose of the input matrix. At this purpose, the vanilla competitive layer and its dual are presented. The former is just an adaptation of a standard competitive layer for deep clustering, while the latter is trained on the transposed matrix. Their equivalence is extensively proven both theoretically and experimentally. However, the dual layer is better suited for handling very high-dimensional datasets. The proposed approach has a great potential as it can be generalized to a vast selection of topological learning tasks, such as non-stationary and hierarchical clustering; furthermore, it can also be integrated within more complex architectures such as autoencoders and generative adversarial networks.
Topological Gradient-based Competitive Learning
Aug 21, 2020

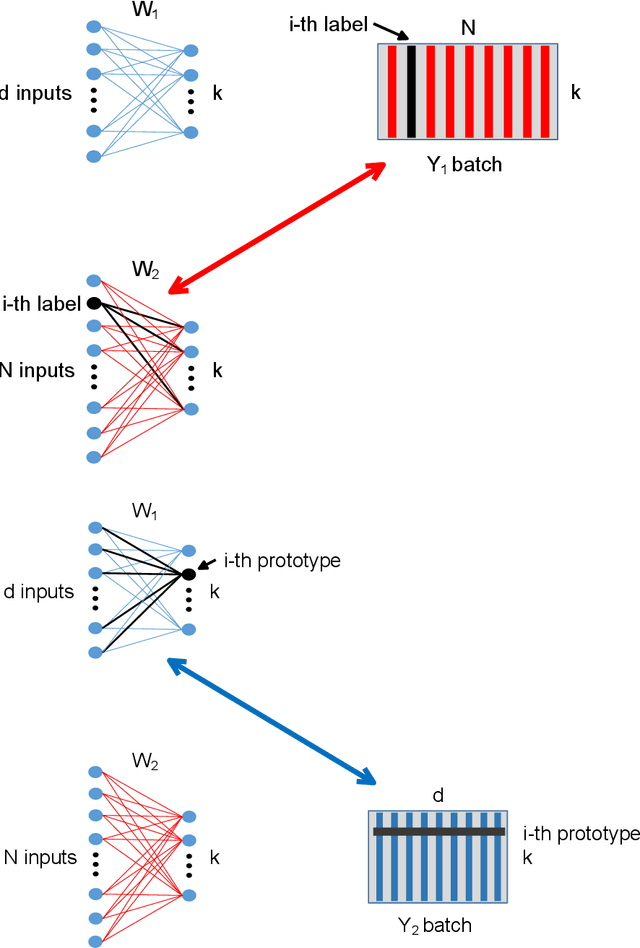
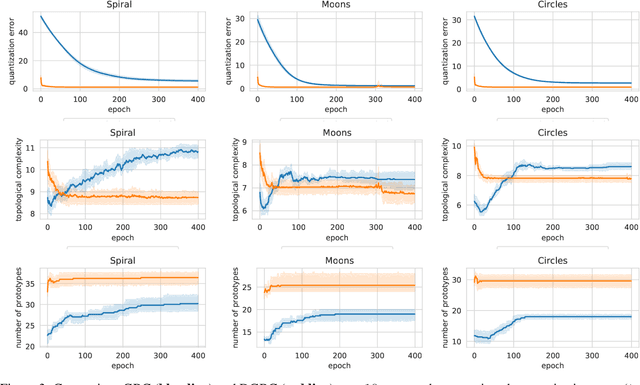
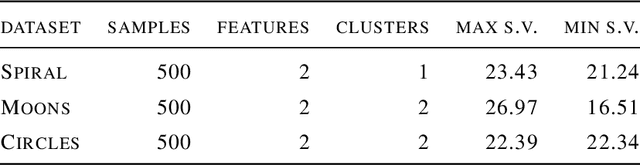
Topological learning is a wide research area aiming at uncovering the mutual spatial relationships between the elements of a set. Some of the most common and oldest approaches involve the use of unsupervised competitive neural networks. However, these methods are not based on gradient optimization which has been proven to provide striking results in feature extraction also in unsupervised learning. Unfortunately, by focusing mostly on algorithmic efficiency and accuracy, deep clustering techniques are composed of overly complex feature extractors, while using trivial algorithms in their top layer. The aim of this work is to present a novel comprehensive theory aspiring at bridging competitive learning with gradient-based learning, thus allowing the use of extremely powerful deep neural networks for feature extraction and projection combined with the remarkable flexibility and expressiveness of competitive learning. In this paper we fully demonstrate the theoretical equivalence of two novel gradient-based competitive layers. Preliminary experiments show how the dual approach, trained on the transpose of the input matrix i.e. $X^T$, lead to faster convergence rate and higher training accuracy both in low and high-dimensional scenarios.