 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Attribute Selectivity Estimation Using Deep Learning
Mar 24, 2019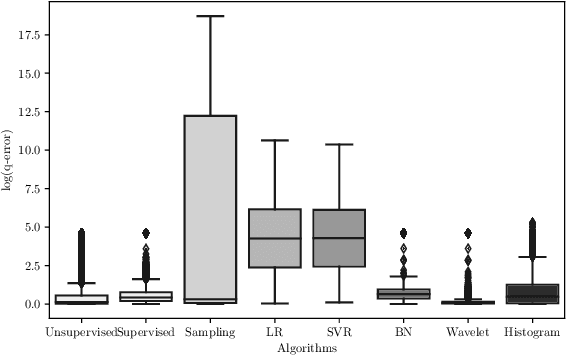
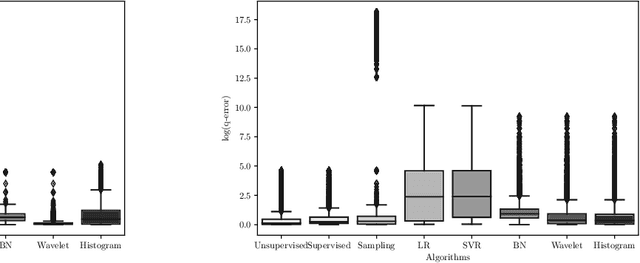
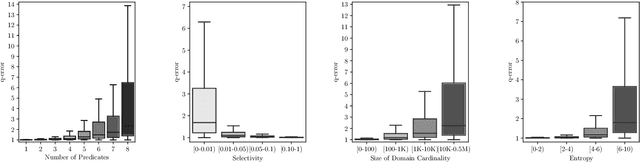
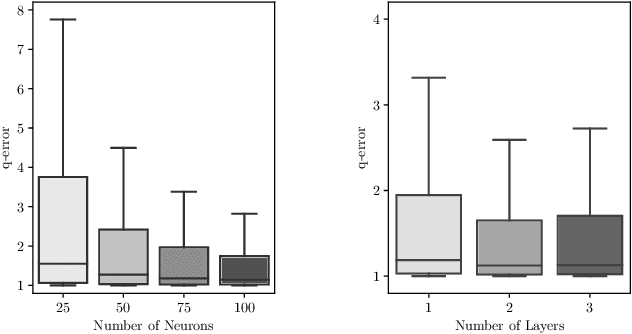
Selectivity estimation - the problem of estimating the result size of queries - is a fundamental yet challenging problem in databases. Accurate estimation of query selectivity involving multiple correlated attributes is especially challenging. Poor cardinality estimates could result in the selection of bad plans by the query optimizer. In this paper, we investigate the feasibility of using deep learning based approaches for challenging scenarios such as queries involving multiple predicates and/or low selectivity. Specifically, we propose two complementary approaches. Our first approach considers selectivity as an unsupervised deep density estimation problem. We successfully introduce techniques from neural density estimation for this purpose. The key idea is to decompose the joint distribution into a set of tractable conditional probability distributions such that they satisfy the autoregressive property. Our second approach formulates selectivity estimation as a supervised deep learning problem that predicts the selectivity of a given query. We also introduce and address a number of practical challenges arising when adapting deep learning for relational data. These include query/data featurization, incorporating query workload information in a deep learning framework and the dynamic scenario where both data and workload queries could be updated. Our extensive experiments with a special emphasis on queries with a large number of predicates and/or small result sizes demonstrates that deep learning based techniques are a promising research avenue for selectivity estimation worthy of further investigation.