 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent LLMs for Adaptive Acquisition in Bayesian Optimization
Mar 30, 2026The exploration-exploitation trade-off is central to sequential decision-making and black-box optimization, yet how Large Language Models (LLMs) reason about and manage this trade-off remains poorly understood. Unlike Bayesian Optimization, where exploration and exploitation are explicitly encoded through acquisition functions, LLM-based optimization relies on implicit, prompt-based reasoning over historical evaluations, making search behavior difficult to analyze or control. In this work, we present a metric-level study of LLM-mediated search policy learning, studying how LLMs construct and adapt exploration-exploitation strategies under multiple operational definitions of exploration, including informativeness, diversity, and representativeness. We show that single-agent LLM approaches, which jointly perform strategy selection and candidate generation within a single prompt, suffer from cognitive overload, leading to unstable search dynamics and premature convergence. To address this limitation, we propose a multi-agent framework that decomposes exploration-exploitation control into strategic policy mediation and tactical candidate generation. A strategy agent assigns interpretable weights to multiple search criteria, while a generation agent produces candidates conditioned on the resulting search policy defined as weights. This decomposition renders exploration-exploitation decisions explicit, observable, and adjustable. Empirical results across various continuous optimization benchmarks indicate that separating strategic control from candidate generation substantially improves the effectiveness of LLM-mediated search.
Resolving Predictive Multiplicity for the Rashomon Set
Jan 14, 2026The existence of multiple, equally accurate models for a given predictive task leads to predictive multiplicity, where a ``Rashomon set'' of models achieve similar accuracy but diverges in their individual predictions. This inconsistency undermines trust in high-stakes applications where we want consistent predictions. We propose three approaches to reduce inconsistency among predictions for the members of the Rashomon set. The first approach is \textbf{outlier correction}. An outlier has a label that none of the good models are capable of predicting correctly. Outliers can cause the Rashomon set to have high variance predictions in a local area, so fixing them can lower variance. Our second approach is local patching. In a local region around a test point, models may disagree with each other because some of them are biased. We can detect and fix such biases using a validation set, which also reduces multiplicity. Our third approach is pairwise reconciliation, where we find pairs of models that disagree on a region around the test point. We modify predictions that disagree, making them less biased. These three approaches can be used together or separately, and they each have distinct advantages. The reconciled predictions can then be distilled into a single interpretable model for real-world deployment. In experiments across multiple datasets, our methods reduce disagreement metrics while maintaining competitive accuracy.
Bi-Level Contextual Bandits for Individualized Resource Allocation under Delayed Feedback
Nov 14, 2025Equitably allocating limited resources in high-stakes domains-such as education, employment, and healthcare-requires balancing short-term utility with long-term impact, while accounting for delayed outcomes, hidden heterogeneity, and ethical constraints. However, most learning-based allocation frameworks either assume immediate feedback or ignore the complex interplay between individual characteristics and intervention dynamics. We propose a novel bi-level contextual bandit framework for individualized resource allocation under delayed feedback, designed to operate in real-world settings with dynamic populations, capacity constraints, and time-sensitive impact. At the meta level, the model optimizes subgroup-level budget allocations to satisfy fairness and operational constraints. At the base level, it identifies the most responsive individuals within each group using a neural network trained on observational data, while respecting cooldown windows and delayed treatment effects modeled via resource-specific delay kernels. By explicitly modeling temporal dynamics and feedback delays, the algorithm continually refines its policy as new data arrive, enabling more responsive and adaptive decision-making. We validate our approach on two real-world datasets from education and workforce development, showing that it achieves higher cumulative outcomes, better adapts to delay structures, and ensures equitable distribution across subgroups. Our results highlight the potential of delay-aware, data-driven decision-making systems to improve institutional policy and social welfare.
Building Trust in Black-box Optimization: A Comprehensive Framework for Explainability
Oct 18, 2024

Optimizing costly black-box functions within a constrained evaluation budget presents significant challenges in many real-world applications. Surrogate Optimization (SO) is a common resolution, yet its proprietary nature introduced by the complexity of surrogate models and the sampling core (e.g., acquisition functions) often leads to a lack of explainability and transparency. While existing literature has primarily concentrated on enhancing convergence to global optima, the practical interpretation of newly proposed strategies remains underexplored, especially in batch evaluation settings. In this paper, we propose \emph{Inclusive} Explainability Metrics for Surrogate Optimization (IEMSO), a comprehensive set of model-agnostic metrics designed to enhance the transparency, trustworthiness, and explainability of the SO approaches. Through these metrics, we provide both intermediate and post-hoc explanations to practitioners before and after performing expensive evaluations to gain trust. We consider four primary categories of metrics, each targeting a specific aspect of the SO process: Sampling Core Metrics, Batch Properties Metrics, Optimization Process Metrics, and Feature Importance. Our experimental evaluations demonstrate the significant potential of the proposed metrics across different benchmarks.
Fair Multivariate Adaptive Regression Splines for Ensuring Equity and Transparency
Feb 23, 2024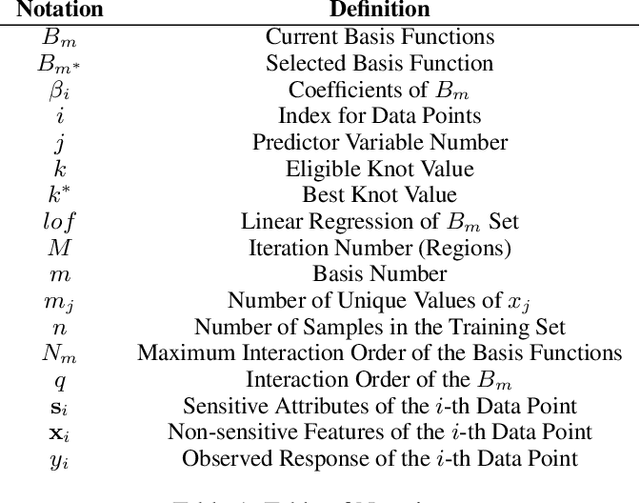



Predictive analytics is widely used in various domains, including education, to inform decision-making and improve outcomes. However, many predictive models are proprietary and inaccessible for evaluation or modification by researchers and practitioners, limiting their accountability and ethical design. Moreover, predictive models are often opaque and incomprehensible to the officials who use them, reducing their trust and utility. Furthermore, predictive models may introduce or exacerbate bias and inequity, as they have done in many sectors of society. Therefore, there is a need for transparent, interpretable, and fair predictive models that can be easily adopted and adapted by different stakeholders. In this paper, we propose a fair predictive model based on multivariate adaptive regression splines(MARS) that incorporates fairness measures in the learning process. MARS is a non-parametric regression model that performs feature selection, handles non-linear relationships, generates interpretable decision rules, and derives optimal splitting criteria on the variables. Specifically, we integrate fairness into the knot optimization algorithm and provide theoretical and empirical evidence of how it results in a fair knot placement. We apply our fairMARS model to real-world data and demonstrate its effectiveness in terms of accuracy and equity. Our paper contributes to the advancement of responsible and ethical predictive analytics for social good.
Hyperparameter Adaptive Search for Surrogate Optimization: A Self-Adjusting Approach
Oct 12, 2023



Surrogate Optimization (SO) algorithms have shown promise for optimizing expensive black-box functions. However, their performance is heavily influenced by hyperparameters related to sampling and surrogate fitting, which poses a challenge to their widespread adoption. We investigate the impact of hyperparameters on various SO algorithms and propose a Hyperparameter Adaptive Search for SO (HASSO) approach. HASSO is not a hyperparameter tuning algorithm, but a generic self-adjusting SO algorithm that dynamically tunes its own hyperparameters while concurrently optimizing the primary objective function, without requiring additional evaluations. The aim is to improve the accessibility, effectiveness, and convergence speed of SO algorithms for practitioners. Our approach identifies and modifies the most influential hyperparameters specific to each problem and SO approach, reducing the need for manual tuning without significantly increasing the computational burden. Experimental results demonstrate the effectiveness of HASSO in enhancing the performance of various SO algorithms across different global optimization test problems.
Fairness and Bias in Truth Discovery Algorithms: An Experimental Analysis
Apr 25, 2023



Machine learning (ML) based approaches are increasingly being used in a number of applications with societal impact. Training ML models often require vast amounts of labeled data, and crowdsourcing is a dominant paradigm for obtaining labels from multiple workers. Crowd workers may sometimes provide unreliable labels, and to address this, truth discovery (TD) algorithms such as majority voting are applied to determine the consensus labels from conflicting worker responses. However, it is important to note that these consensus labels may still be biased based on sensitive attributes such as gender, race, or political affiliation. Even when sensitive attributes are not involved, the labels can be biased due to different perspectives of subjective aspects such as toxicity. In this paper, we conduct a systematic study of the bias and fairness of TD algorithms. Our findings using two existing crowd-labeled datasets, reveal that a non-trivial proportion of workers provide biased results, and using simple approaches for TD is sub-optimal. Our study also demonstrates that popular TD algorithms are not a panacea. Additionally, we quantify the impact of these unfair workers on downstream ML tasks and show that conventional methods for achieving fairness and correcting label biases are ineffective in this setting. We end the paper with a plea for the design of novel bias-aware truth discovery algorithms that can ameliorate these issues.
FairPilot: An Explorative System for Hyperparameter Tuning through the Lens of Fairness
Apr 10, 2023



Despite the potential benefits of machine learning (ML) in high-risk decision-making domains, the deployment of ML is not accessible to practitioners, and there is a risk of discrimination. To establish trust and acceptance of ML in such domains, democratizing ML tools and fairness consideration are crucial. In this paper, we introduce FairPilot, an interactive system designed to promote the responsible development of ML models by exploring a combination of various models, different hyperparameters, and a wide range of fairness definitions. We emphasize the challenge of selecting the ``best" ML model and demonstrate how FairPilot allows users to select a set of evaluation criteria and then displays the Pareto frontier of models and hyperparameters as an interactive map. FairPilot is the first system to combine these features, offering a unique opportunity for users to responsibly choose their model.
Explainable Predictive Modeling for Limited Spectral Data
Feb 09, 2022
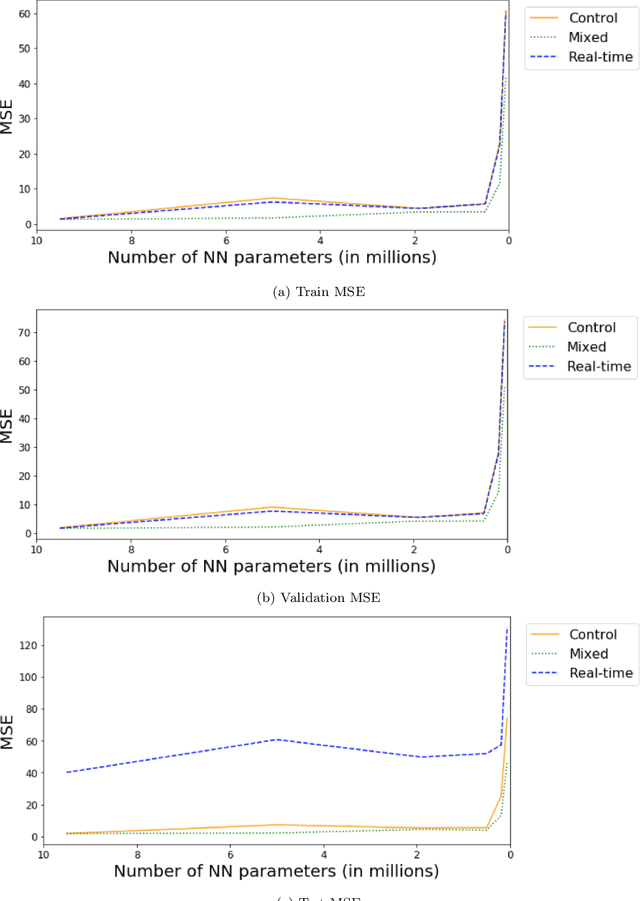

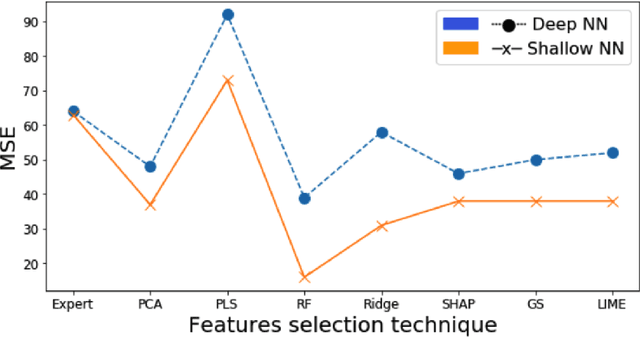
Feature selection of high-dimensional labeled data with limited observations is critical for making powerful predictive modeling accessible, scalable, and interpretable for domain experts. Spectroscopy data, which records the interaction between matter and electromagnetic radiation, particularly holds a lot of information in a single sample. Since acquiring such high-dimensional data is a complex task, it is crucial to exploit the best analytical tools to extract necessary information. In this paper, we investigate the most commonly used feature selection techniques and introduce applying recent explainable AI techniques to interpret the prediction outcomes of high-dimensional and limited spectral data. Interpretation of the prediction outcome is beneficial for the domain experts as it ensures the transparency and faithfulness of the ML models to the domain knowledge. Due to the instrument resolution limitations, pinpointing important regions of the spectroscopy data creates a pathway to optimize the data collection process through the miniaturization of the spectrometer device. Reducing the device size and power and therefore cost is a requirement for the real-world deployment of such a sensor-to-prediction system as a whole. We specifically design three different scenarios to ensure that the evaluation of ML models is robust for the real-time practice of the developed methodologies and to uncover the hidden effect of noise sources on the final outcome.
Auditing Fairness and Imputation Impact in Predictive Analytics for Higher Education
Sep 13, 2021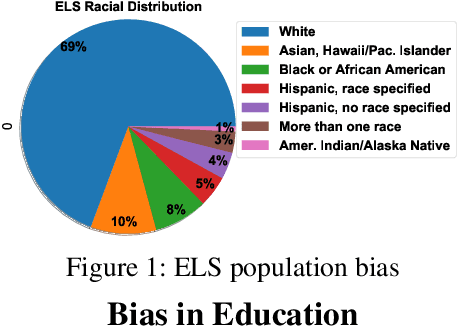

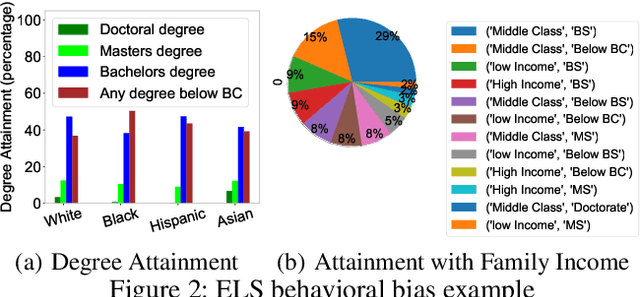
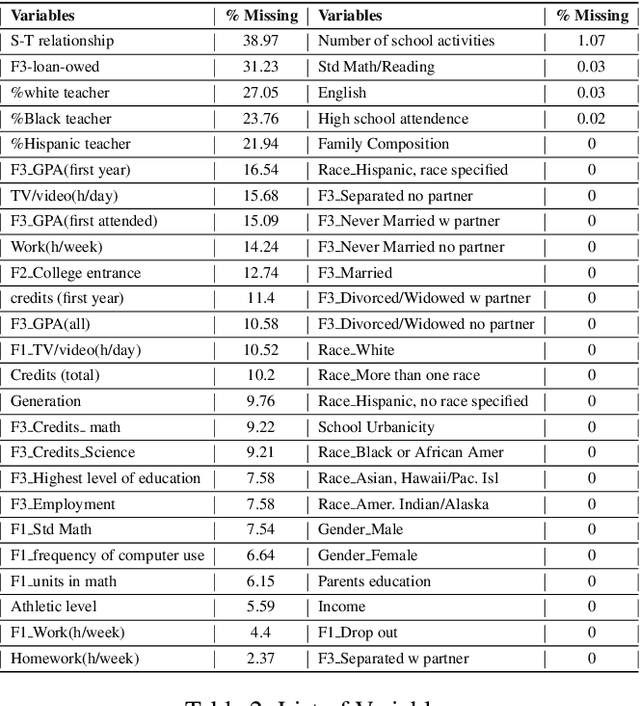
Nowadays, colleges and universities use predictive analytics in a variety of ways to increase student success rates. Despite the potentials for predictive analytics, there exist two major barriers to their adoption in higher education: (a) the lack of democratization in deployment, and (b) the potential to exacerbate inequalities. Education researchers and policymakers encounter numerous challenges in deploying predictive modeling in practice. These challenges present in different steps of modeling including data preparation, model development, and evaluation. Nevertheless, each of these steps can introduce additional bias to the system if not appropriately performed. Most large-scale and nationally representative education data sets suffer from a significant number of incomplete responses from the research participants. Missing Values are the frequent latent causes behind many data analysis challenges. While many education-related studies addressed the challenges of missing data, little is known about the impact of handling missing values on the fairness of predictive outcomes in practice. In this paper, we set out to first assess the disparities in predictive modeling outcome for college-student success, then investigate the impact of imputation techniques on the model performance and fairness using a comprehensive set of common metrics. The comprehensive analysis of a real large-scale education dataset reveals key insights on the modeling disparity and how different imputation techniques fundamentally compare to one another in terms of their impact on the fairness of the student-success predictive outcome.