 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Trust in Black-box Optimization: A Comprehensive Framework for Explainability
Oct 18, 2024

Optimizing costly black-box functions within a constrained evaluation budget presents significant challenges in many real-world applications. Surrogate Optimization (SO) is a common resolution, yet its proprietary nature introduced by the complexity of surrogate models and the sampling core (e.g., acquisition functions) often leads to a lack of explainability and transparency. While existing literature has primarily concentrated on enhancing convergence to global optima, the practical interpretation of newly proposed strategies remains underexplored, especially in batch evaluation settings. In this paper, we propose \emph{Inclusive} Explainability Metrics for Surrogate Optimization (IEMSO), a comprehensive set of model-agnostic metrics designed to enhance the transparency, trustworthiness, and explainability of the SO approaches. Through these metrics, we provide both intermediate and post-hoc explanations to practitioners before and after performing expensive evaluations to gain trust. We consider four primary categories of metrics, each targeting a specific aspect of the SO process: Sampling Core Metrics, Batch Properties Metrics, Optimization Process Metrics, and Feature Importance. Our experimental evaluations demonstrate the significant potential of the proposed metrics across different benchmarks.
Hyperparameter Adaptive Search for Surrogate Optimization: A Self-Adjusting Approach
Oct 12, 2023



Surrogate Optimization (SO) algorithms have shown promise for optimizing expensive black-box functions. However, their performance is heavily influenced by hyperparameters related to sampling and surrogate fitting, which poses a challenge to their widespread adoption. We investigate the impact of hyperparameters on various SO algorithms and propose a Hyperparameter Adaptive Search for SO (HASSO) approach. HASSO is not a hyperparameter tuning algorithm, but a generic self-adjusting SO algorithm that dynamically tunes its own hyperparameters while concurrently optimizing the primary objective function, without requiring additional evaluations. The aim is to improve the accessibility, effectiveness, and convergence speed of SO algorithms for practitioners. Our approach identifies and modifies the most influential hyperparameters specific to each problem and SO approach, reducing the need for manual tuning without significantly increasing the computational burden. Experimental results demonstrate the effectiveness of HASSO in enhancing the performance of various SO algorithms across different global optimization test problems.
FairPilot: An Explorative System for Hyperparameter Tuning through the Lens of Fairness
Apr 10, 2023



Despite the potential benefits of machine learning (ML) in high-risk decision-making domains, the deployment of ML is not accessible to practitioners, and there is a risk of discrimination. To establish trust and acceptance of ML in such domains, democratizing ML tools and fairness consideration are crucial. In this paper, we introduce FairPilot, an interactive system designed to promote the responsible development of ML models by exploring a combination of various models, different hyperparameters, and a wide range of fairness definitions. We emphasize the challenge of selecting the ``best" ML model and demonstrate how FairPilot allows users to select a set of evaluation criteria and then displays the Pareto frontier of models and hyperparameters as an interactive map. FairPilot is the first system to combine these features, offering a unique opportunity for users to responsibly choose their model.
Auditing Fairness and Imputation Impact in Predictive Analytics for Higher Education
Sep 13, 2021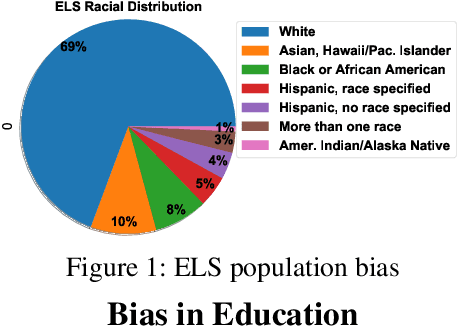

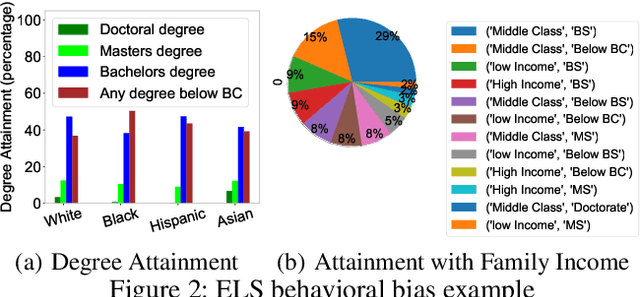
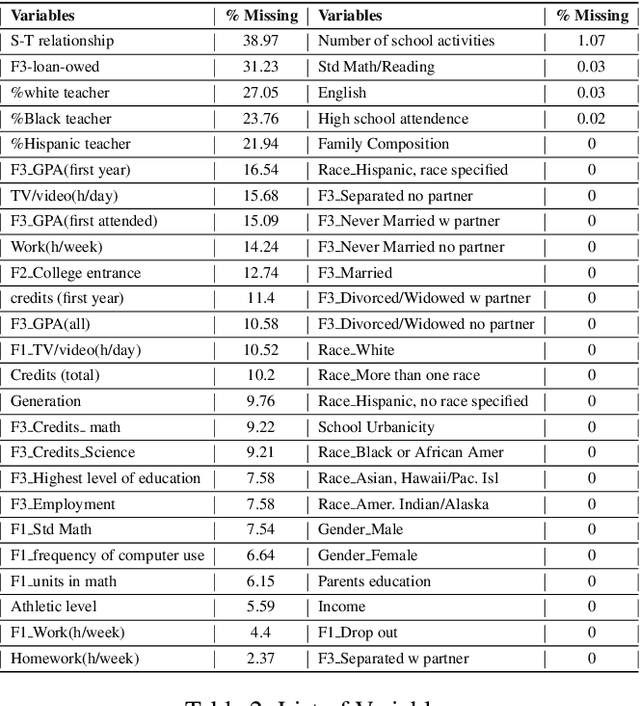
Nowadays, colleges and universities use predictive analytics in a variety of ways to increase student success rates. Despite the potentials for predictive analytics, there exist two major barriers to their adoption in higher education: (a) the lack of democratization in deployment, and (b) the potential to exacerbate inequalities. Education researchers and policymakers encounter numerous challenges in deploying predictive modeling in practice. These challenges present in different steps of modeling including data preparation, model development, and evaluation. Nevertheless, each of these steps can introduce additional bias to the system if not appropriately performed. Most large-scale and nationally representative education data sets suffer from a significant number of incomplete responses from the research participants. Missing Values are the frequent latent causes behind many data analysis challenges. While many education-related studies addressed the challenges of missing data, little is known about the impact of handling missing values on the fairness of predictive outcomes in practice. In this paper, we set out to first assess the disparities in predictive modeling outcome for college-student success, then investigate the impact of imputation techniques on the model performance and fairness using a comprehensive set of common metrics. The comprehensive analysis of a real large-scale education dataset reveals key insights on the modeling disparity and how different imputation techniques fundamentally compare to one another in terms of their impact on the fairness of the student-success predictive outcome.
On the Choice of Fairness: Finding Representative Fairness Metrics for a Given Context
Sep 13, 2021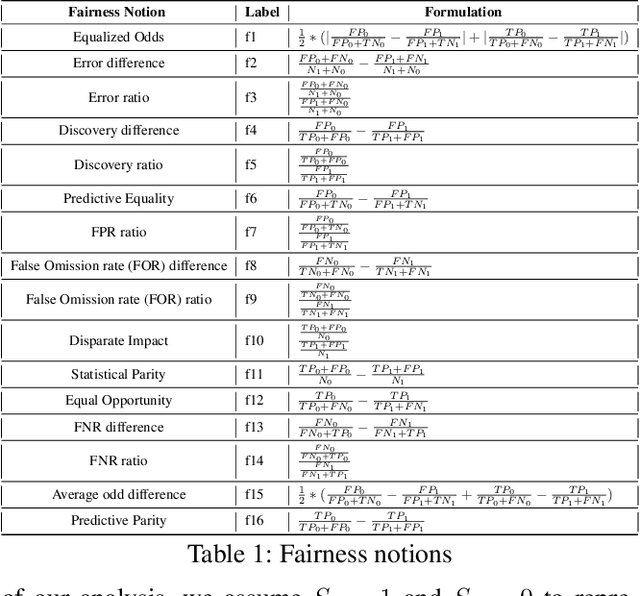
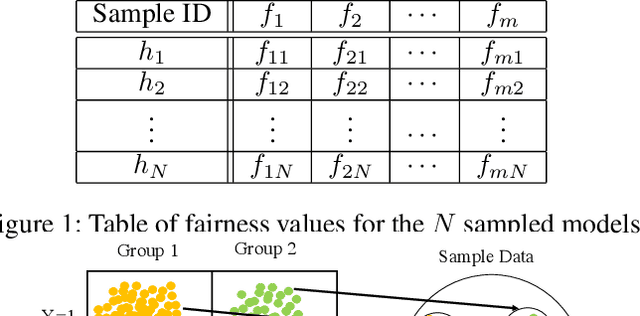
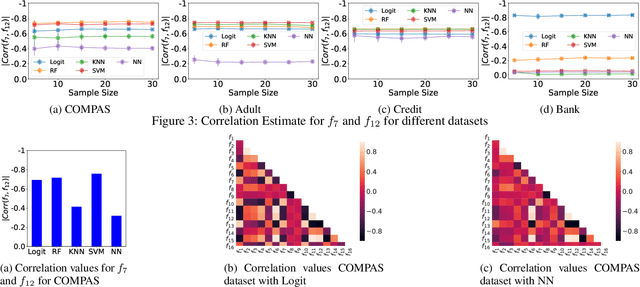
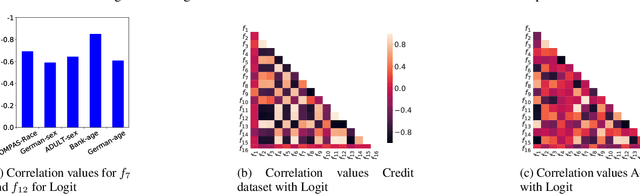
It is of critical importance to be aware of the historical discrimination embedded in the data and to consider a fairness measure to reduce bias throughout the predictive modeling pipeline. Various notions of fairness have been defined, though choosing an appropriate metric is cumbersome. Trade-offs and impossibility theorems make such selection even more complicated and controversial. In practice, users (perhaps regular data scientists) should understand each of the measures and (if possible) manually explore the combinatorial space of different measures before they can decide which combination is preferred based on the context, the use case, and regulations. To alleviate the burden of selecting fairness notions for consideration, we propose a framework that automatically discovers the correlations and trade-offs between different pairs of measures for a given context. Our framework dramatically reduces the exploration space by finding a small subset of measures that represent others and highlighting the trade-offs between them. This allows users to view unfairness from various perspectives that might otherwise be ignored due to the sheer size of the exploration space. We showcase the validity of the proposal using comprehensive experiments on real-world benchmark data sets.