 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Adversary-Resistant Multi-Agent LLM System via Credibility Scoring
May 30, 2025While multi-agent LLM systems show strong capabilities in various domains, they are highly vulnerable to adversarial and low-performing agents. To resolve this issue, in this paper, we introduce a general and adversary-resistant multi-agent LLM framework based on credibility scoring. We model the collaborative query-answering process as an iterative game, where the agents communicate and contribute to a final system output. Our system associates a credibility score that is used when aggregating the team outputs. The credibility scores are learned gradually based on the past contributions of each agent in query answering. Our experiments across multiple tasks and settings demonstrate our system's effectiveness in mitigating adversarial influence and enhancing the resilience of multi-agent cooperation, even in the adversary-majority settings.
REQUAL-LM: Reliability and Equity through Aggregation in Large Language Models
Apr 17, 2024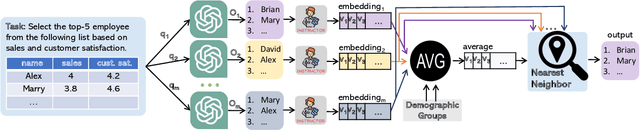
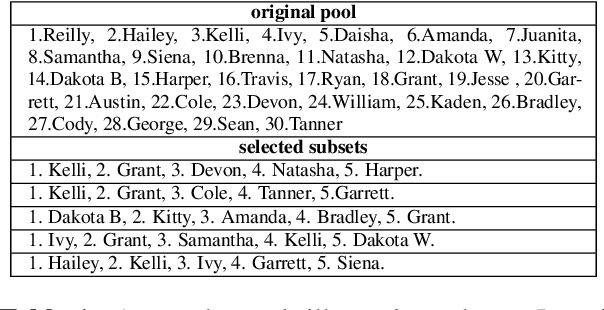
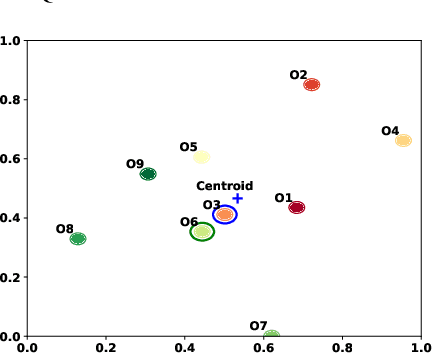
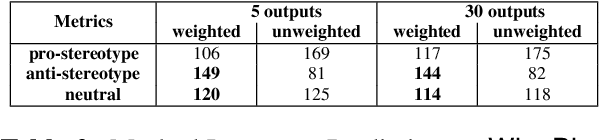
The extensive scope of large language models (LLMs) across various domains underscores the critical importance of responsibility in their application, beyond natural language processing. In particular, the randomized nature of LLMs, coupled with inherent biases and historical stereotypes in data, raises critical concerns regarding reliability and equity. Addressing these challenges are necessary before using LLMs for applications with societal impact. Towards addressing this gap, we introduce REQUAL-LM, a novel method for finding reliable and equitable LLM outputs through aggregation. Specifically, we develop a Monte Carlo method based on repeated sampling to find a reliable output close to the mean of the underlying distribution of possible outputs. We formally define the terms such as reliability and bias, and design an equity-aware aggregation to minimize harmful bias while finding a highly reliable output. REQUAL-LM does not require specialized hardware, does not impose a significant computing load, and uses LLMs as a blackbox. This design choice enables seamless scalability alongside the rapid advancement of LLM technologies. Our system does not require retraining the LLMs, which makes it deployment ready and easy to adapt. Our comprehensive experiments using various tasks and datasets demonstrate that REQUAL- LM effectively mitigates bias and selects a more equitable response, specifically the outputs that properly represents minority groups.
AXOLOTL: Fairness through Assisted Self-Debiasing of Large Language Model Outputs
Mar 01, 2024



Pre-trained Large Language Models (LLMs) have significantly advanced natural language processing capabilities but are susceptible to biases present in their training data, leading to unfair outcomes in various applications. While numerous strategies have been proposed to mitigate bias, they often require extensive computational resources and may compromise model performance. In this work, we introduce AXOLOTL, a novel post-processing framework, which operates agnostically across tasks and models, leveraging public APIs to interact with LLMs without direct access to internal parameters. Through a three-step process resembling zero-shot learning, AXOLOTL identifies biases, proposes resolutions, and guides the model to self-debias its outputs. This approach minimizes computational costs and preserves model performance, making AXOLOTL a promising tool for debiasing LLM outputs with broad applicability and ease of use.
Sampling-Based Techniques for Training Deep Neural Networks with Limited Computational Resources: A Scalability Evaluation
Jun 15, 2023



Deep neural networks are superior to shallow networks in learning complex representations. As such, there is a fast-growing interest in utilizing them in large-scale settings. The training process of neural networks is already known to be time-consuming, and having a deep architecture only aggravates the issue. This process consists mostly of matrix operations, among which matrix multiplication is the bottleneck. Several sampling-based techniques have been proposed for speeding up the training time of deep neural networks by approximating the matrix products. These techniques fall under two categories: (i) sampling a subset of nodes in every hidden layer as active at every iteration and (ii) sampling a subset of nodes from the previous layer to approximate the current layer's activations using the edges from the sampled nodes. In both cases, the matrix products are computed using only the selected samples. In this paper, we evaluate the scalability of these approaches on CPU machines with limited computational resources. Making a connection between the two research directions as special cases of approximating matrix multiplications in the context of neural networks, we provide a negative theoretical analysis that shows feedforward approximation is an obstacle against scalability. We conduct comprehensive experimental evaluations that demonstrate the most pressing challenges and limitations associated with the studied approaches. We observe that the hashing-based node selection method is not scalable to a large number of layers, confirming our theoretical analysis. Finally, we identify directions for future research.