 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSR-core: A High-Performance Engine for Low-Bit Matrix-Vector Multiplication
Mar 29, 2026Matrix-vector multiplication is a fundamental building block in neural networks, vector databases, and large language models, particularly during inference. As a result, efficient matrix-vector multiplication engines directly translate into more efficient inference. Recent work has explored low-bit quantization of model weights, where matrices are represented using binary (1-bit) or ternary (1.58-bit) values while activation is kept in higher precision. These representations enable efficient hardware-level computation. In parallel, algorithms such as Redundant Segment Reduction (RSR) provide theoretical guarantees for accelerating low-bit matrix-vector multiplication. However, existing implementations operate at the application level and cannot be efficiently integrated into hardware kernels, limiting practical performance. To bridge this gap, we present RSR-core, a high-performance engine that implements the RSR algorithm as optimized low-level kernels for both CPU and CUDA environments. RSR-core supports efficient matrix-vector multiplication for binary and ternary weight matrices and general vectors while enabling practical deployment of RSR algorithm in real inference pipelines. RSR-core is provided as a production-ready engine with HuggingFace integration for preprocessing low-bit models and running accelerated inference. Experimental results demonstrate significant performance improvements over baseline HuggingFace PyTorch multiplication, achieving up to 62x speedup on CPU and up to 1.9x speedup for token generation on CUDA for popular ternary LLMs. The source code is publicly available at https://github.com/UIC-InDeXLab/RSR-core.
An Adversary-Resistant Multi-Agent LLM System via Credibility Scoring
May 30, 2025While multi-agent LLM systems show strong capabilities in various domains, they are highly vulnerable to adversarial and low-performing agents. To resolve this issue, in this paper, we introduce a general and adversary-resistant multi-agent LLM framework based on credibility scoring. We model the collaborative query-answering process as an iterative game, where the agents communicate and contribute to a final system output. Our system associates a credibility score that is used when aggregating the team outputs. The credibility scores are learned gradually based on the past contributions of each agent in query answering. Our experiments across multiple tasks and settings demonstrate our system's effectiveness in mitigating adversarial influence and enhancing the resilience of multi-agent cooperation, even in the adversary-majority settings.
Needle: A Generative-AI Powered Monte Carlo Method for Answering Complex Natural Language Queries on Multi-modal Data
Dec 01, 2024Multi-modal data, such as image data sets, often miss the detailed descriptions that properly capture the rich information encoded in them. This makes answering complex natural language queries a major challenge in these domains. In particular, unlike the traditional nearest-neighbor search, where the tuples and the query are modeled as points in a data cube, the query and the tuples are of different natures, making the traditional query answering solutions not directly applicable for such settings. Existing literature addresses this challenge for image data through vector representations jointly trained on natural language and images. This technique, however, underperforms for complex queries due to various reasons. This paper takes a step towards addressing this challenge by introducing a Generative-AI (GenAI) powered Monte Carlo method that utilizes foundation models to generate synthetic samples that capture the complexity of the natural language query and transform it to the same space of the multi-modal data. Following this method, we develop a system for image data retrieval and propose practical solutions that enable leveraging future advancements in GenAI and vector representations for improving our system's performance. Our comprehensive experiments on various benchmark datasets verify that our system significantly outperforms state-of-the-art techniques.
Rank It, Then Ask It: Input Reranking for Maximizing the Performance of LLMs on Symmetric Tasks
Nov 30, 2024Large language models (LLMs) have quickly emerged as practical and versatile tools that provide new solutions for a wide range of domains. In this paper, we consider the application of LLMs on symmetric tasks where a query is asked on an (unordered) bag of elements. Examples of such tasks include answering aggregate queries on a database table. In general, when the bag contains a large number of elements, LLMs tend to overlook some elements, leading to challenges in generating accurate responses to the query. LLMs receive their inputs as ordered sequences. However, in this problem, we leverage the fact that the symmetric input is not ordered, and reordering should not affect the LLM's response. Observing that LLMs are less likely to miss elements at certain positions of the input, we introduce the problem of LLM input reranking: to find a ranking of the input that maximizes the LLM's accuracy for the given query without making explicit assumptions about the query. Finding the optimal ranking requires identifying (i) the relevance of each input element for answering the query and (ii) the importance of each rank position for the LLM's attention. We develop algorithms for estimating these values efficiently utilizing a helper LLM. We conduct comprehensive experiments on different synthetic and real datasets to validate our proposal and to evaluate the effectiveness of our proposed algorithms. Our experiments confirm that our reranking approach improves the accuracy of the LLMs on symmetric tasks by up to $99\%$ proximity to the optimum upper bound.
Optimized Inference for 1.58-bit LLMs: A Time and Memory-Efficient Algorithm for Binary and Ternary Matrix Multiplication
Nov 10, 2024

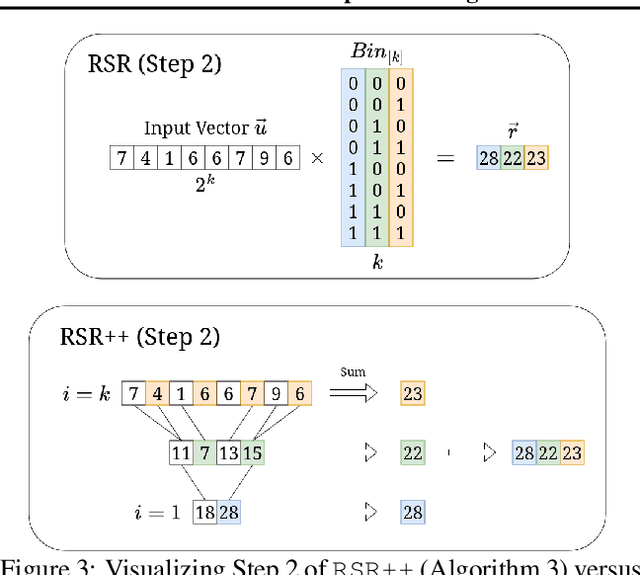

Despite their tremendous success and versatility, Large Language Models (LLMs) suffer from inference inefficiency while relying on advanced computational infrastructure. To address these challenges and make LLMs more accessible and cost-effective, in this paper, we propose algorithms to improve the inference time and memory efficiency of 1.58-bit LLMs with ternary weight matrices. Particularly focusing on matrix multiplication as the bottle-neck operation of inference, we observe that, once trained, the weight matrices of a model no longer change. This allows us to preprocess these matrices and create indices that help reduce the storage requirements by a logarithmic factor while enabling our efficient inference algorithms. Specifically, for a $n$ by $n$ weight matrix, our efficient algorithm guarantees a time complexity of $O(\frac{n^2}{\log n})$, a logarithmic factor improvement over the standard $O(n^2)$ vector-matrix multiplication. Besides theoretical analysis, we conduct extensive experiments to evaluate the practical efficiency of our algorithms. Our results confirm the superiority of the approach both with respect to time and memory, as we observed a reduction in inference time up to 29x and memory usage up to 6x.
Mining the Minoria: Unknown, Under-represented, and Under-performing Minority Groups
Nov 07, 2024Due to a variety of reasons, such as privacy, data in the wild often misses the grouping information required for identifying minorities. On the other hand, it is known that machine learning models are only as good as the data they are trained on and, hence, may underperform for the under-represented minority groups. The missing grouping information presents a dilemma for responsible data scientists who find themselves in an unknown-unknown situation, where not only do they not have access to the grouping attributes but do not also know what groups to consider. This paper is an attempt to address this dilemma. Specifically, we propose a minority mining problem, where we find vectors in the attribute space that reveal potential groups that are under-represented and under-performing. Technically speaking, we propose a geometric transformation of data into a dual space and use notions such as the arrangement of hyperplanes to design an efficient algorithm for the problem in lower dimensions. Generalizing our solution to the higher dimensions is cursed by dimensionality. Therefore, we propose a solution based on smart exploration of the search space for such cases. We conduct comprehensive experiments using real-world and synthetic datasets alongside the theoretical analysis. Our experiment results demonstrate the effectiveness of our proposed solutions in mining the unknown, under-represented, and under-performing minorities.