 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREQUAL-LM: Reliability and Equity through Aggregation in Large Language Models
Paper and Code
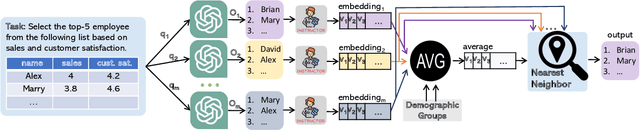
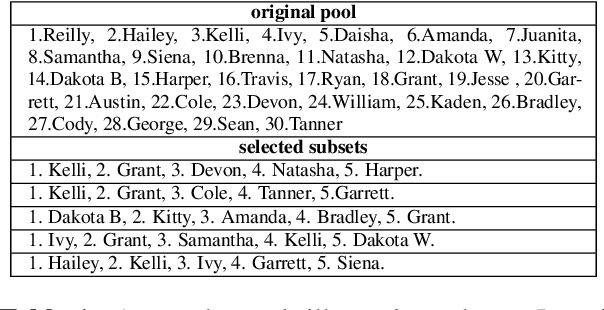
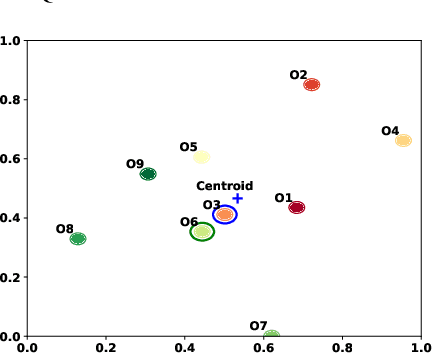
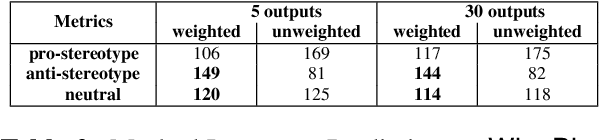
The extensive scope of large language models (LLMs) across various domains underscores the critical importance of responsibility in their application, beyond natural language processing. In particular, the randomized nature of LLMs, coupled with inherent biases and historical stereotypes in data, raises critical concerns regarding reliability and equity. Addressing these challenges are necessary before using LLMs for applications with societal impact. Towards addressing this gap, we introduce REQUAL-LM, a novel method for finding reliable and equitable LLM outputs through aggregation. Specifically, we develop a Monte Carlo method based on repeated sampling to find a reliable output close to the mean of the underlying distribution of possible outputs. We formally define the terms such as reliability and bias, and design an equity-aware aggregation to minimize harmful bias while finding a highly reliable output. REQUAL-LM does not require specialized hardware, does not impose a significant computing load, and uses LLMs as a blackbox. This design choice enables seamless scalability alongside the rapid advancement of LLM technologies. Our system does not require retraining the LLMs, which makes it deployment ready and easy to adapt. Our comprehensive experiments using various tasks and datasets demonstrate that REQUAL- LM effectively mitigates bias and selects a more equitable response, specifically the outputs that properly represents minority groups.