 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Low Can You Go? Surfacing Prototypical In-Distribution Samples for Unsupervised Anomaly Detection
Paper and Code
Dec 06, 2023
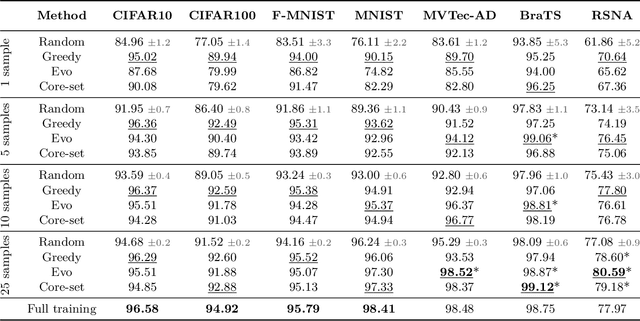
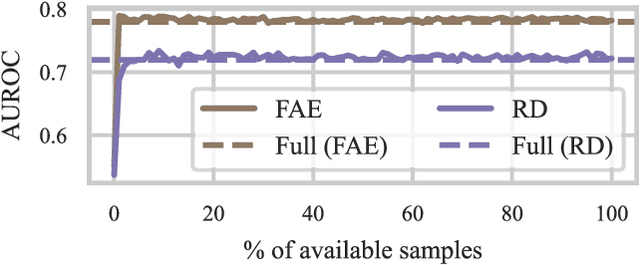
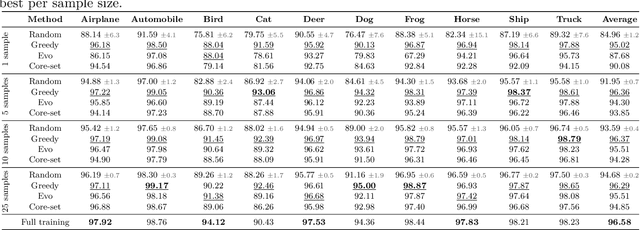
Unsupervised anomaly detection (UAD) alleviates large labeling efforts by training exclusively on unlabeled in-distribution data and detecting outliers as anomalies. Generally, the assumption prevails that large training datasets allow the training of higher-performing UAD models. However, in this work, we show that using only very few training samples can already match - and in some cases even improve - anomaly detection compared to training with the whole training dataset. We propose three methods to identify prototypical samples from a large dataset of in-distribution samples. We demonstrate that by training with a subset of just ten such samples, we achieve an area under the receiver operating characteristics curve (AUROC) of $96.37 \%$ on CIFAR10, $92.59 \%$ on CIFAR100, $95.37 \%$ on MNIST, $95.38 \%$ on Fashion-MNIST, $96.37 \%$ on MVTec-AD, $98.81 \%$ on BraTS, and $81.95 \%$ on RSNA pneumonia detection, even exceeding the performance of full training in $25/67$ classes we tested. Additionally, we show that the prototypical in-distribution samples identified by our proposed methods translate well to different models and other datasets and that using their characteristics as guidance allows for successful manual selection of small subsets of high-performing samples. Our code is available at https://anonymous.4open.science/r/uad_prototypical_samples/