 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging gradient-derived metrics for data selection and valuation in differentially private training
Paper and Code
May 05, 2023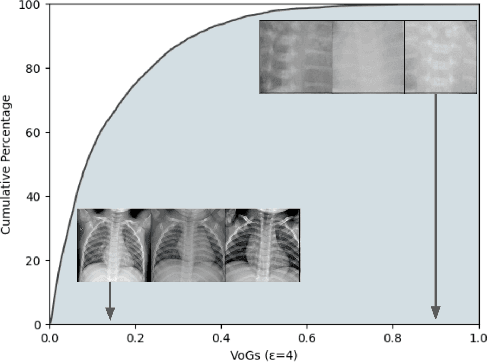
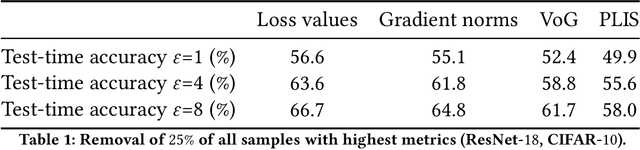

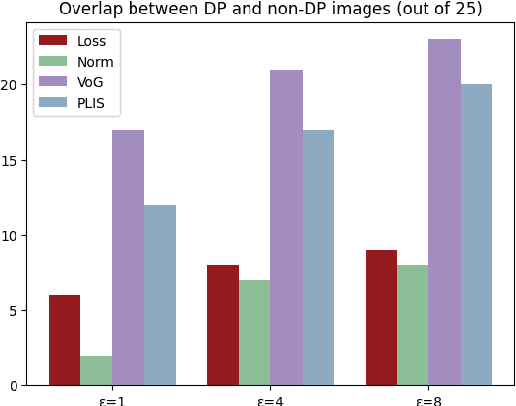
Obtaining high-quality data for collaborative training of machine learning models can be a challenging task due to A) the regulatory concerns and B) lack of incentive to participate. The first issue can be addressed through the use of privacy enhancing technologies (PET), one of the most frequently used one being differentially private (DP) training. The second challenge can be addressed by identifying which data points can be beneficial for model training and rewarding data owners for sharing this data. However, DP in deep learning typically adversely affects atypical (often informative) data samples, making it difficult to assess the usefulness of individual contributions. In this work we investigate how to leverage gradient information to identify training samples of interest in private training settings. We show that there exist techniques which are able to provide the clients with the tools for principled data selection even in strictest privacy settings.