 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMomentum Boosted Episodic Memory for Improving Learning in Long-Tailed RL Environments
Paper and Code
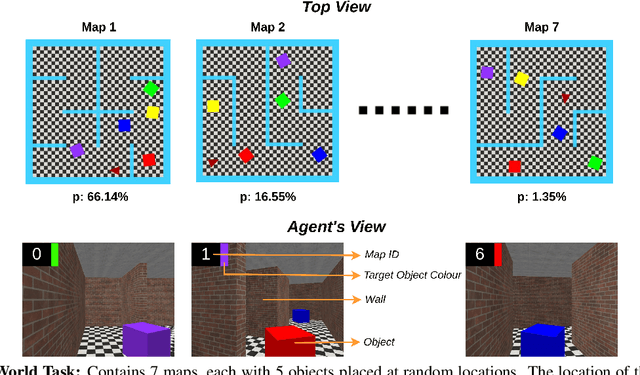
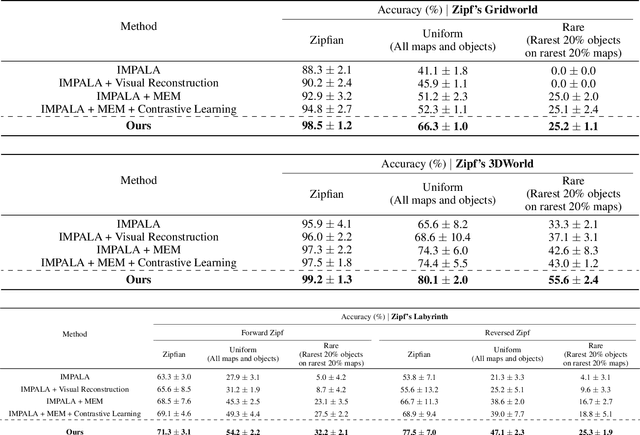
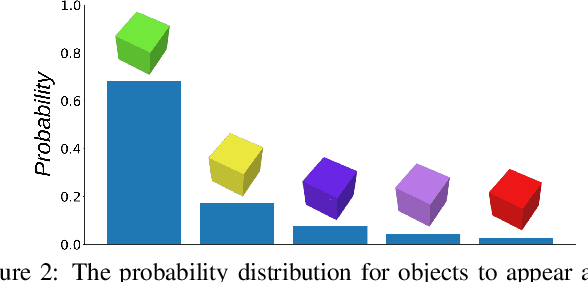
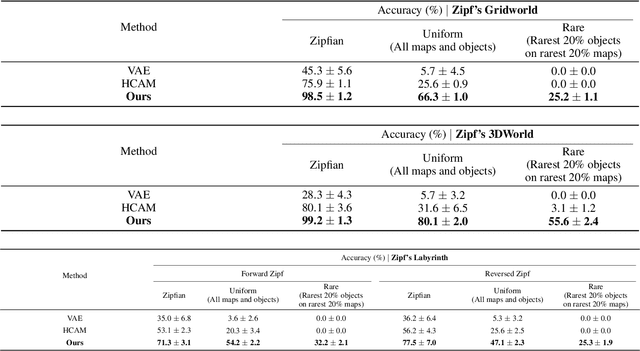
Traditional Reinforcement Learning (RL) algorithms assume the distribution of the data to be uniform or mostly uniform. However, this is not the case with most real-world applications like autonomous driving or in nature where animals roam. Some experiences are encountered frequently, and most of the remaining experiences occur rarely; the resulting distribution is called Zipfian. Taking inspiration from the theory of complementary learning systems, an architecture for learning from Zipfian distributions is proposed where important long tail trajectories are discovered in an unsupervised manner. The proposal comprises an episodic memory buffer containing a prioritised memory module to ensure important rare trajectories are kept longer to address the Zipfian problem, which needs credit assignment to happen in a sample efficient manner. The experiences are then reinstated from episodic memory and given weighted importance forming the trajectory to be executed. Notably, the proposed architecture is modular, can be incorporated in any RL architecture and yields improved performance in multiple Zipfian tasks over traditional architectures. Our method outperforms IMPALA by a significant margin on all three tasks and all three evaluation metrics (Zipfian, Uniform, and Rare Accuracy) and also gives improvements on most Atari environments that are considered challenging