 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaLoRA-QAT: Adaptive Low-Rank and Quantization-Aware Segmentation
Apr 01, 2026Chest X-ray (CXR) segmentation is an important step in computer-aided diagnosis, yet deploying large foundation models in clinical settings remains challenging due to computational constraints. We propose AdaLoRA-QAT, a two-stage fine-tuning framework that combines adaptive low-rank encoder adaptation with full quantization-aware training. Adaptive rank allocation improves parameter efficiency, while selective mixed-precision INT8 quantization preserves structural fidelity crucial for clinical reliability. Evaluated across large-scale CXR datasets, AdaLoRA-QAT achieves 95.6% Dice, matching full-precision SAM decoder fine-tuning while reducing trainable parameters by 16.6\times and yielding 2.24\times model compression. A Wilcoxon signed-rank test confirms that quantization does not significantly degrade segmentation accuracy. These results demonstrate that AdaLoRA-QAT effectively balances accuracy, efficiency, and structural trust-worthiness, enabling compact and deployable foundation models for medical image segmentation. Code and pretrained models are available at: https://prantik-pdeb.github.io/adaloraqat.github.io/
AI Generalisation Gap In Comorbid Sleep Disorder Staging
Mar 24, 2026Accurate sleep staging is essential for diagnosing OSA and hypopnea in stroke patients. Although PSG is reliable, it is costly, labor-intensive, and manually scored. While deep learning enables automated EEG-based sleep staging in healthy subjects, our analysis shows poor generalization to clinical populations with disrupted sleep. Using Grad-CAM interpretations, we systematically demonstrate this limitation. We introduce iSLEEPS, a newly clinically annotated ischemic stroke dataset (to be publicly released), and evaluate a SE-ResNet plus bidirectional LSTM model for single-channel EEG sleep staging. As expected, cross-domain performance between healthy and diseased subjects is poor. Attention visualizations, supported by clinical expert feedback, show the model focuses on physiologically uninformative EEG regions in patient data. Statistical and computational analyses further confirm significant sleep architecture differences between healthy and ischemic stroke cohorts, highlighting the need for subject-aware or disease-specific models with clinical validation before deployment. A summary of the paper and the code is available at https://himalayansaswatabose.github.io/iSLEEPS_Explainability.github.io/
Deep Neural Networks and Brain Alignment: Brain Encoding and Decoding (Survey)
Jul 17, 2023



How does the brain represent different modes of information? Can we design a system that automatically understands what the user is thinking? Such questions can be answered by studying brain recordings like functional magnetic resonance imaging (fMRI). As a first step, the neuroscience community has contributed several large cognitive neuroscience datasets related to passive reading/listening/viewing of concept words, narratives, pictures and movies. Encoding and decoding models using these datasets have also been proposed in the past two decades. These models serve as additional tools for basic research in cognitive science and neuroscience. Encoding models aim at generating fMRI brain representations given a stimulus automatically. They have several practical applications in evaluating and diagnosing neurological conditions and thus also help design therapies for brain damage. Decoding models solve the inverse problem of reconstructing the stimuli given the fMRI. They are useful for designing brain-machine or brain-computer interfaces. Inspired by the effectiveness of deep learning models for natural language processing, computer vision, and speech, recently several neural encoding and decoding models have been proposed. In this survey, we will first discuss popular representations of language, vision and speech stimuli, and present a summary of neuroscience datasets. Further, we will review popular deep learning based encoding and decoding architectures and note their benefits and limitations. Finally, we will conclude with a brief summary and discussion about future trends. Given the large amount of recently published work in the `computational cognitive neuroscience' community, we believe that this survey nicely organizes the plethora of work and presents it as a coherent story.
Visio-Linguistic Brain Encoding
Apr 18, 2022
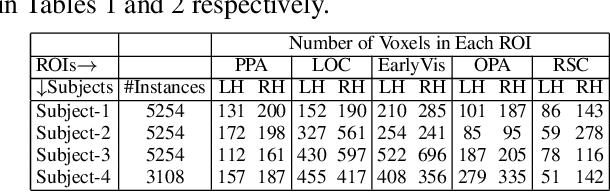
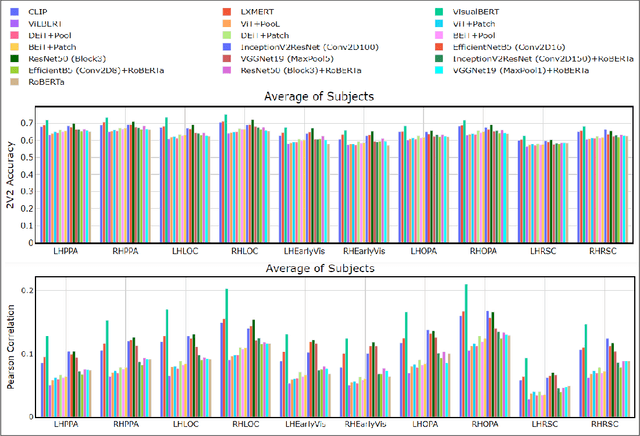
Enabling effective brain-computer interfaces requires understanding how the human brain encodes stimuli across modalities such as visual, language (or text), etc. Brain encoding aims at constructing fMRI brain activity given a stimulus. There exists a plethora of neural encoding models which study brain encoding for single mode stimuli: visual (pretrained CNNs) or text (pretrained language models). Few recent papers have also obtained separate visual and text representation models and performed late-fusion using simple heuristics. However, previous work has failed to explore: (a) the effectiveness of image Transformer models for encoding visual stimuli, and (b) co-attentive multi-modal modeling for visual and text reasoning. In this paper, we systematically explore the efficacy of image Transformers (ViT, DEiT, and BEiT) and multi-modal Transformers (VisualBERT, LXMERT, and CLIP) for brain encoding. Extensive experiments on two popular datasets, BOLD5000 and Pereira, provide the following insights. (1) To the best of our knowledge, we are the first to investigate the effectiveness of image and multi-modal Transformers for brain encoding. (2) We find that VisualBERT, a multi-modal Transformer, significantly outperforms previously proposed single-mode CNNs, image Transformers as well as other previously proposed multi-modal models, thereby establishing new state-of-the-art. The supremacy of visio-linguistic models raises the question of whether the responses elicited in the visual regions are affected implicitly by linguistic processing even when passively viewing images. Future fMRI tasks can verify this computational insight in an appropriate experimental setting.
Cross-view Brain Decoding
Apr 18, 2022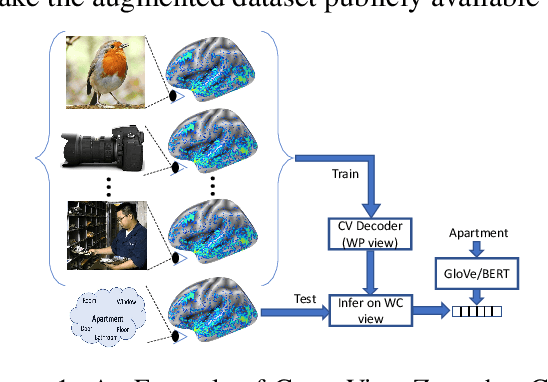
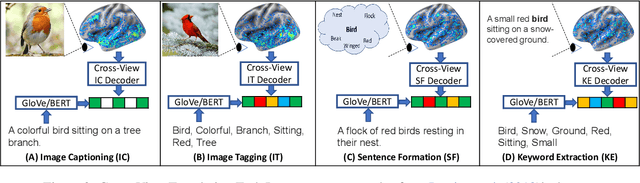
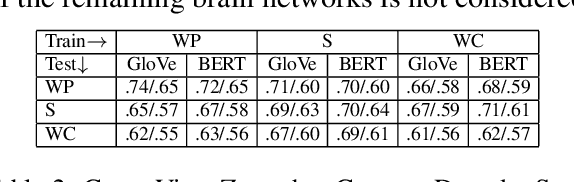
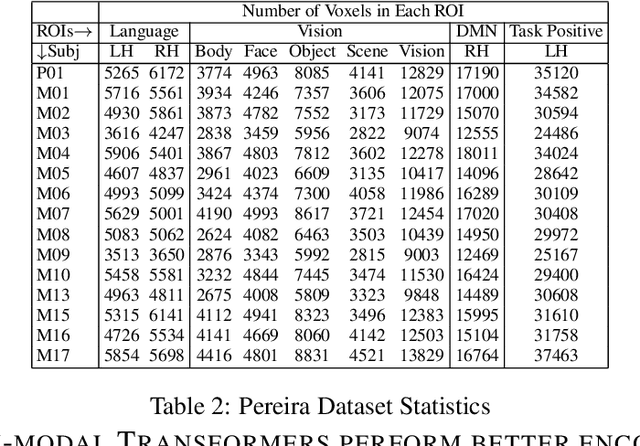
How the brain captures the meaning of linguistic stimuli across multiple views is still a critical open question in neuroscience. Consider three different views of the concept apartment: (1) picture (WP) presented with the target word label, (2) sentence (S) using the target word, and (3) word cloud (WC) containing the target word along with other semantically related words. Unlike previous efforts, which focus only on single view analysis, in this paper, we study the effectiveness of brain decoding in a zero-shot cross-view learning setup. Further, we propose brain decoding in the novel context of cross-view-translation tasks like image captioning (IC), image tagging (IT), keyword extraction (KE), and sentence formation (SF). Using extensive experiments, we demonstrate that cross-view zero-shot brain decoding is practical leading to ~0.68 average pairwise accuracy across view pairs. Also, the decoded representations are sufficiently detailed to enable high accuracy for cross-view-translation tasks with following pairwise accuracy: IC (78.0), IT (83.0), KE (83.7) and SF (74.5). Analysis of the contribution of different brain networks reveals exciting cognitive insights: (1) A high percentage of visual voxels are involved in image captioning and image tagging tasks, and a high percentage of language voxels are involved in the sentence formation and keyword extraction tasks. (2) Zero-shot accuracy of the model trained on S view and tested on WC view is better than same-view accuracy of the model trained and tested on WC view.
A Conservative Q-Learning approach for handling distribution shift in sepsis treatment strategies
Mar 25, 2022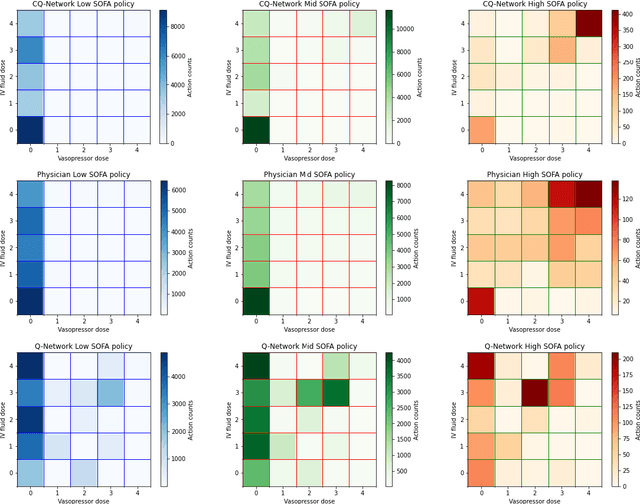
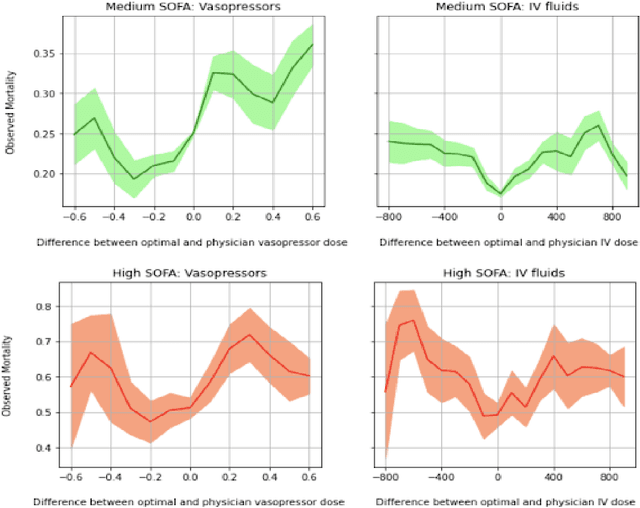
Sepsis is a leading cause of mortality and its treatment is very expensive. Sepsis treatment is also very challenging because there is no consensus on what interventions work best and different patients respond very differently to the same treatment. Deep Reinforcement Learning methods can be used to come up with optimal policies for treatment strategies mirroring physician actions. In the healthcare scenario, the available data is mostly collected offline with no interaction with the environment, which necessitates the use of offline RL techniques. The Offline RL paradigm suffers from action distribution shifts which in turn negatively affects learning an optimal policy for the treatment. In this work, a Conservative-Q Learning (CQL) algorithm is used to mitigate this shift and its corresponding policy reaches closer to the physicians policy than conventional deep Q Learning. The policy learned could help clinicians in Intensive Care Units to make better decisions while treating septic patients and improve survival rate.
ExpertoCoder: Capturing Divergent Brain Regions Using Mixture of Regression Experts
Sep 26, 2019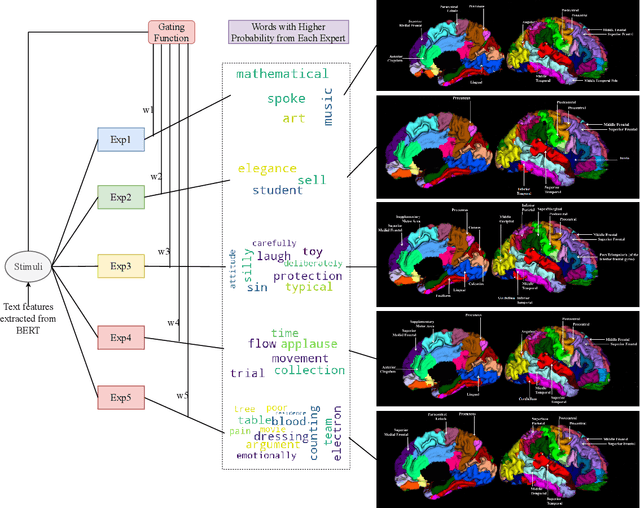
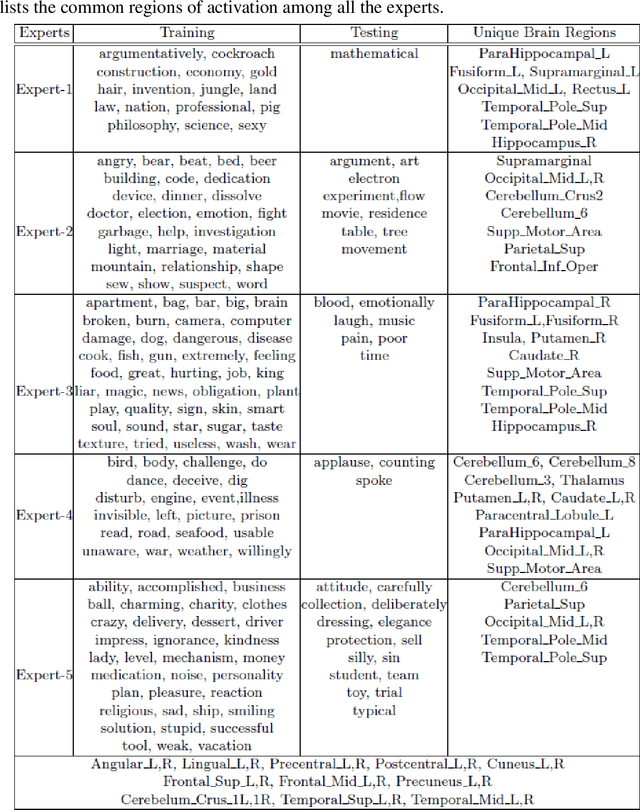

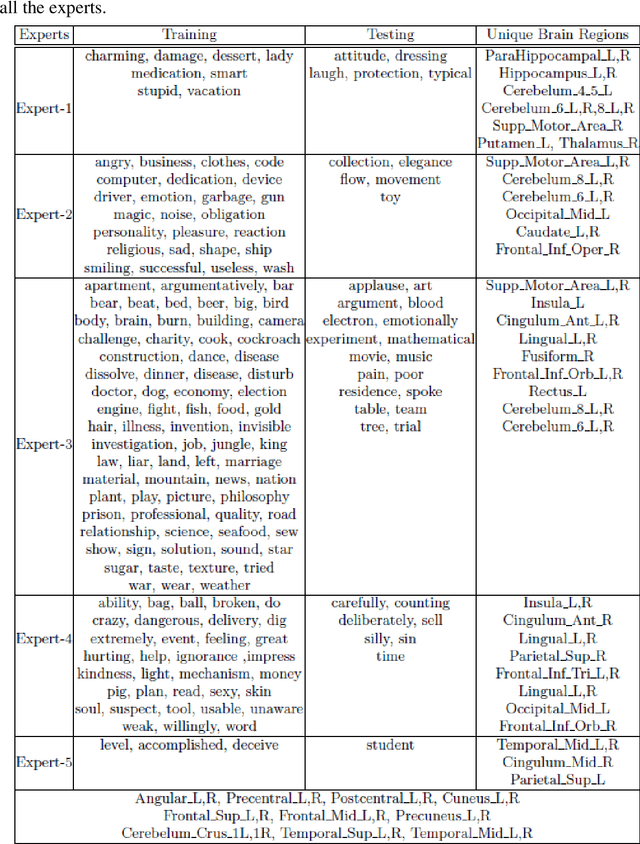
fMRI semantic category understanding using linguistic encoding models attempts to learn a forward mapping that relates stimuli to the corresponding brain activation. Classical encoding models use linear multivariate methods to predict brain activation (all the voxels) given the stimulus. However, these methods mainly assume multiple regions as one vast uniform region or several independent regions, ignoring connections among them. In this paper, we present a mixture of experts model for predicting brain activity patterns. Given a new stimulus, the model predicts the entire brain activation as a weighted linear combination of activation of multiple experts. We argue that each expert captures activity patterns related to a particular region of interest (ROI) in the human brain. Thus, the utility of the proposed model is twofold. It not only accurately predicts the brain activation for a given stimulus, but it also reveals the level of activation of individual brain regions. Results of our experiments highlight the importance of the proposed model for predicting brain activation. This study also helps in understanding which of the brain regions get activated together, given a certain kind of stimulus. Importantly, we suggest that the mixture of regression experts (MoRE) framework successfully combines the two principles of organization of function in the brain, namely that of specialization and integration.
Mixture of Regression Experts in fMRI Encoding
Dec 01, 2018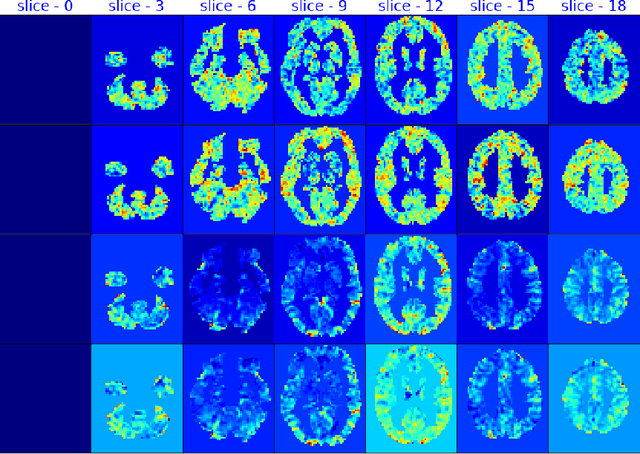
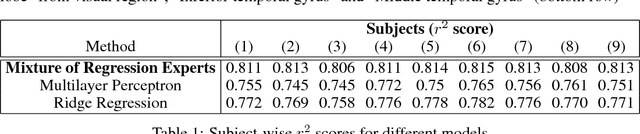
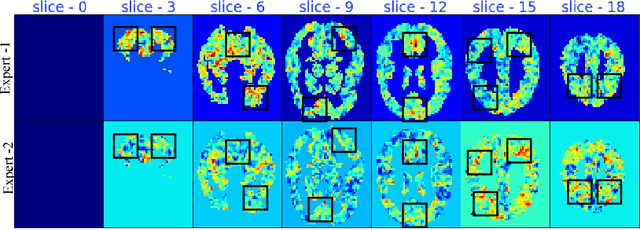
fMRI semantic category understanding using linguistic encoding models attempt to learn a forward mapping that relates stimuli to the corresponding brain activation. Classical encoding models use linear multi-variate methods to predict the brain activation (all voxels) given the stimulus. However, these methods essentially assume multiple regions as one large uniform region or several independent regions, ignoring connections among them. In this paper, we present a mixture of experts-based model where a group of experts captures brain activity patterns related to particular regions of interest (ROI) and also show the discrimination across different experts. The model is trained word stimuli encoded as 25-dimensional feature vectors as input and the corresponding brain responses as output. Given a new word (25-dimensional feature vector), it predicts the entire brain activation as the linear combination of multiple experts brain activations. We argue that each expert learns a certain region of brain activations corresponding to its category of words, which solves the problem of identifying the regions with a simple encoding model. We showcase that proposed mixture of experts-based model indeed learns region-based experts to predict the brain activations with high spatial accuracy.
Learning Photography Aesthetics with Deep CNNs
Jul 13, 2017
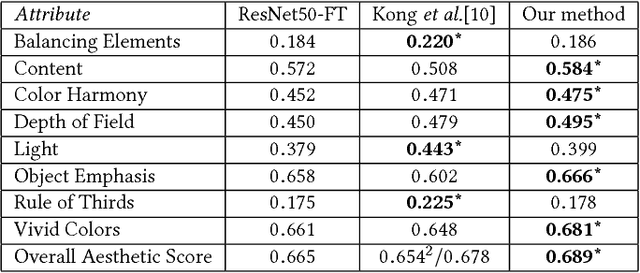
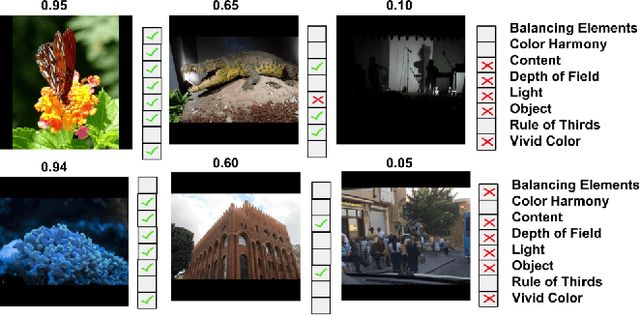
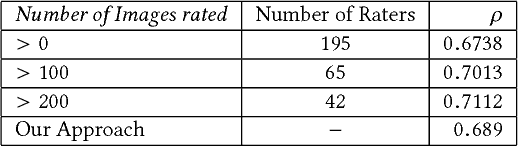
Automatic photo aesthetic assessment is a challenging artificial intelligence task. Existing computational approaches have focused on modeling a single aesthetic score or a class (good or bad), however these do not provide any details on why the photograph is good or bad, or which attributes contribute to the quality of the photograph. To obtain both accuracy and human interpretation of the score, we advocate learning the aesthetic attributes along with the prediction of the overall score. For this purpose, we propose a novel multitask deep convolution neural network, which jointly learns eight aesthetic attributes along with the overall aesthetic score. We report near human performance in the prediction of the overall aesthetic score. To understand the internal representation of these attributes in the learned model, we also develop the visualization technique using back propagation of gradients. These visualizations highlight the important image regions for the corresponding attributes, thus providing insights about model's representation of these attributes. We showcase the diversity and complexity associated with different attributes through a qualitative analysis of the activation maps.