 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffect in Tweets Using Experts Model
Mar 20, 2019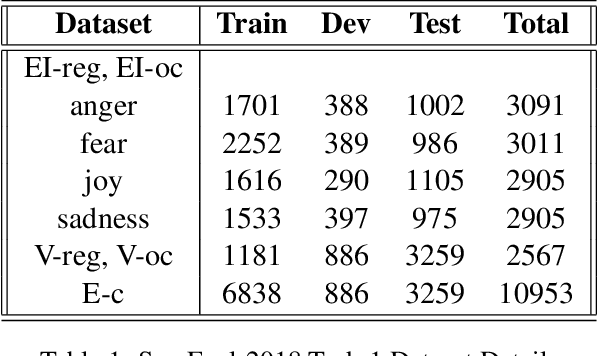
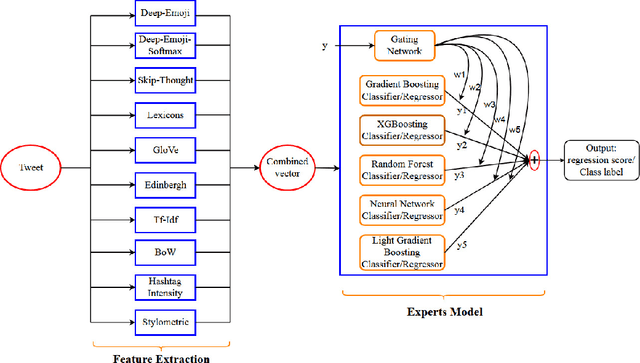
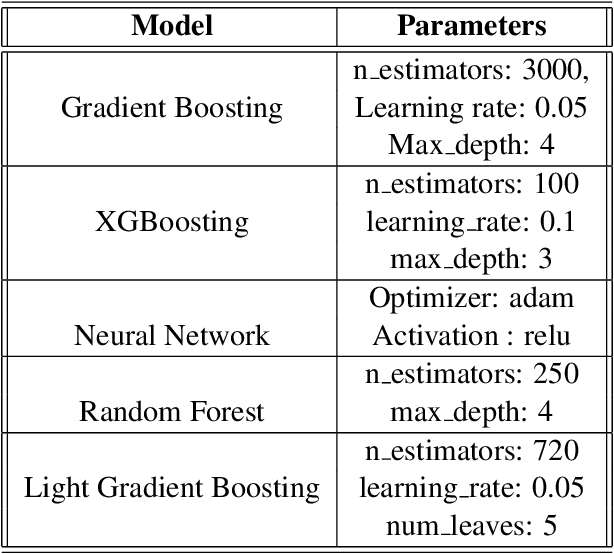
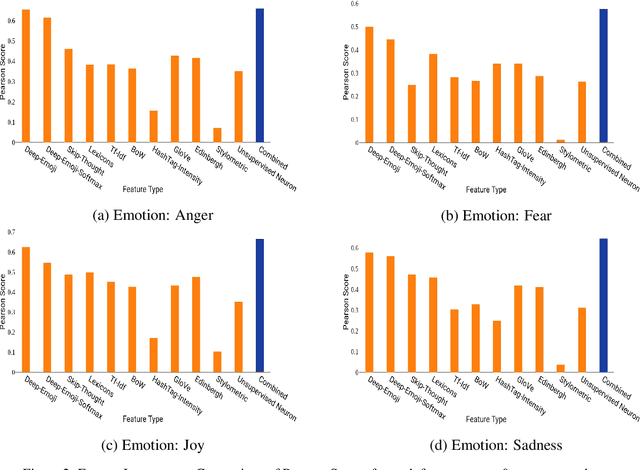
Estimating the intensity of emotion has gained significance as modern textual inputs in potential applications like social media, e-retail markets, psychology, advertisements etc., carry a lot of emotions, feelings, expressions along with its meaning. However, the approaches of traditional sentiment analysis primarily focuses on classifying the sentiment in general (positive or negative) or at an aspect level(very positive, low negative, etc.) and cannot exploit the intensity information. Moreover, automatically identifying emotions like anger, fear, joy, sadness, disgust etc., from text introduces challenging scenarios where single tweet may contain multiple emotions with different intensities and some emotions may even co-occur in some of the tweets. In this paper, we propose an architecture, Experts Model, inspired from the standard Mixture of Experts (MoE) model. The key idea here is each expert learns different sets of features from the feature vector which helps in better emotion detection from the tweet. We compared the results of our Experts Model with both baseline results and top five performers of SemEval-2018 Task-1, Affect in Tweets (AIT). The experimental results show that our proposed approach deals with the emotion detection problem and stands at top-5 results.
Mixture of Regression Experts in fMRI Encoding
Dec 01, 2018
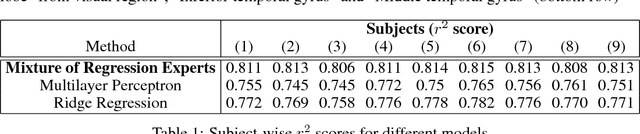
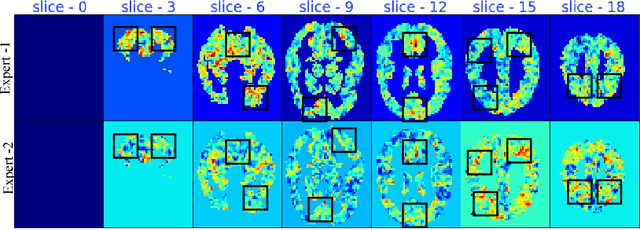
fMRI semantic category understanding using linguistic encoding models attempt to learn a forward mapping that relates stimuli to the corresponding brain activation. Classical encoding models use linear multi-variate methods to predict the brain activation (all voxels) given the stimulus. However, these methods essentially assume multiple regions as one large uniform region or several independent regions, ignoring connections among them. In this paper, we present a mixture of experts-based model where a group of experts captures brain activity patterns related to particular regions of interest (ROI) and also show the discrimination across different experts. The model is trained word stimuli encoded as 25-dimensional feature vectors as input and the corresponding brain responses as output. Given a new word (25-dimensional feature vector), it predicts the entire brain activation as the linear combination of multiple experts brain activations. We argue that each expert learns a certain region of brain activations corresponding to its category of words, which solves the problem of identifying the regions with a simple encoding model. We showcase that proposed mixture of experts-based model indeed learns region-based experts to predict the brain activations with high spatial accuracy.