 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-view Brain Decoding
Paper and Code
Apr 18, 2022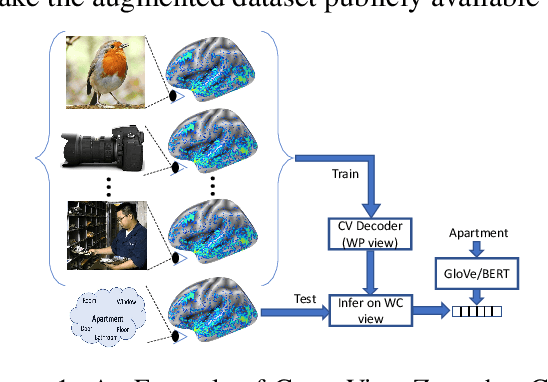
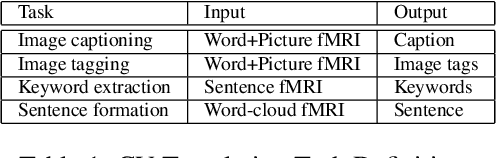
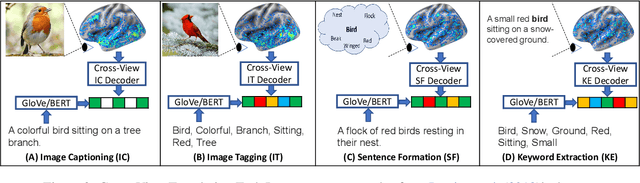
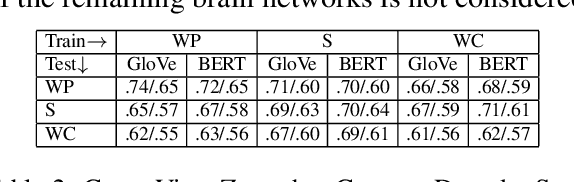
How the brain captures the meaning of linguistic stimuli across multiple views is still a critical open question in neuroscience. Consider three different views of the concept apartment: (1) picture (WP) presented with the target word label, (2) sentence (S) using the target word, and (3) word cloud (WC) containing the target word along with other semantically related words. Unlike previous efforts, which focus only on single view analysis, in this paper, we study the effectiveness of brain decoding in a zero-shot cross-view learning setup. Further, we propose brain decoding in the novel context of cross-view-translation tasks like image captioning (IC), image tagging (IT), keyword extraction (KE), and sentence formation (SF). Using extensive experiments, we demonstrate that cross-view zero-shot brain decoding is practical leading to ~0.68 average pairwise accuracy across view pairs. Also, the decoded representations are sufficiently detailed to enable high accuracy for cross-view-translation tasks with following pairwise accuracy: IC (78.0), IT (83.0), KE (83.7) and SF (74.5). Analysis of the contribution of different brain networks reveals exciting cognitive insights: (1) A high percentage of visual voxels are involved in image captioning and image tagging tasks, and a high percentage of language voxels are involved in the sentence formation and keyword extraction tasks. (2) Zero-shot accuracy of the model trained on S view and tested on WC view is better than same-view accuracy of the model trained and tested on WC view.