 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Language Taskonomy: Which NLP Tasks are the most Predictive of fMRI Brain Activity?
May 03, 2022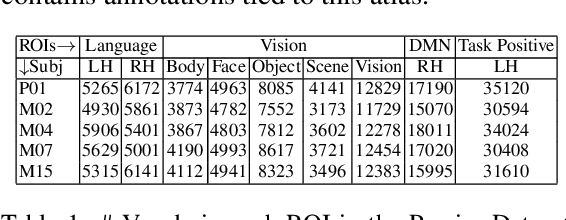
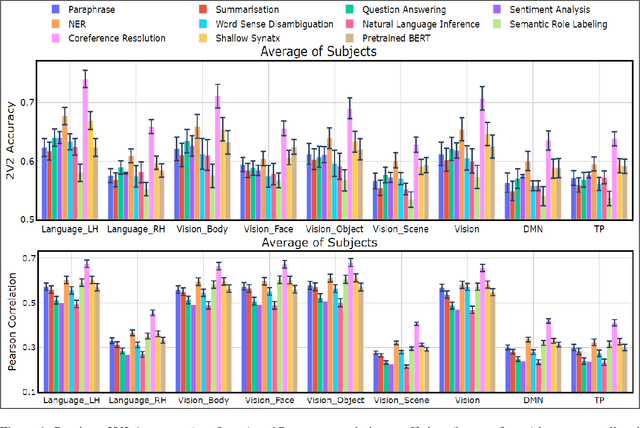
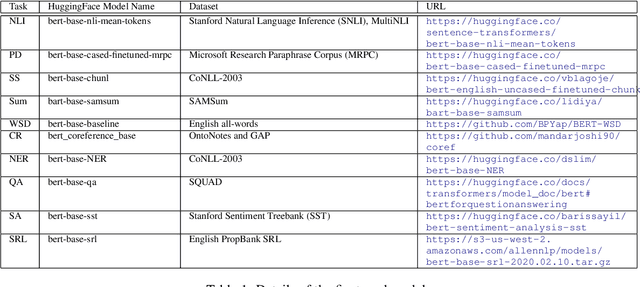
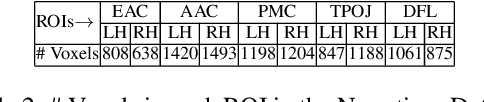
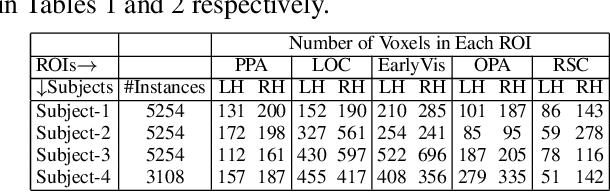
Several popular Transformer based language models have been found to be successful for text-driven brain encoding. However, existing literature leverages only pretrained text Transformer models and has not explored the efficacy of task-specific learned Transformer representations. In this work, we explore transfer learning from representations learned for ten popular natural language processing tasks (two syntactic and eight semantic) for predicting brain responses from two diverse datasets: Pereira (subjects reading sentences from paragraphs) and Narratives (subjects listening to the spoken stories). Encoding models based on task features are used to predict activity in different regions across the whole brain. Features from coreference resolution, NER, and shallow syntax parsing explain greater variance for the reading activity. On the other hand, for the listening activity, tasks such as paraphrase generation, summarization, and natural language inference show better encoding performance. Experiments across all 10 task representations provide the following cognitive insights: (i) language left hemisphere has higher predictive brain activity versus language right hemisphere, (ii) posterior medial cortex, temporo-parieto-occipital junction, dorsal frontal lobe have higher correlation versus early auditory and auditory association cortex, (iii) syntactic and semantic tasks display a good predictive performance across brain regions for reading and listening stimuli resp.
Visio-Linguistic Brain Encoding
Apr 18, 2022
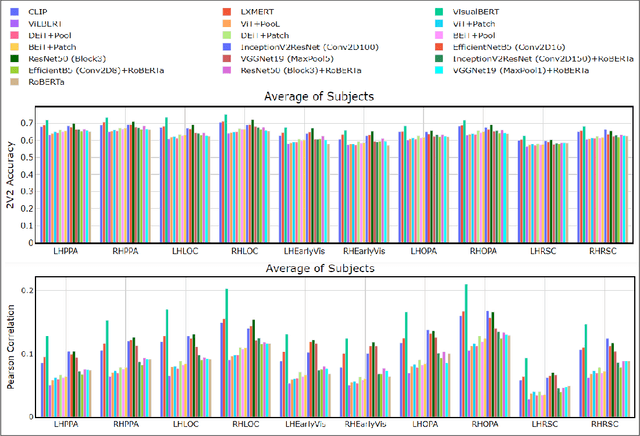
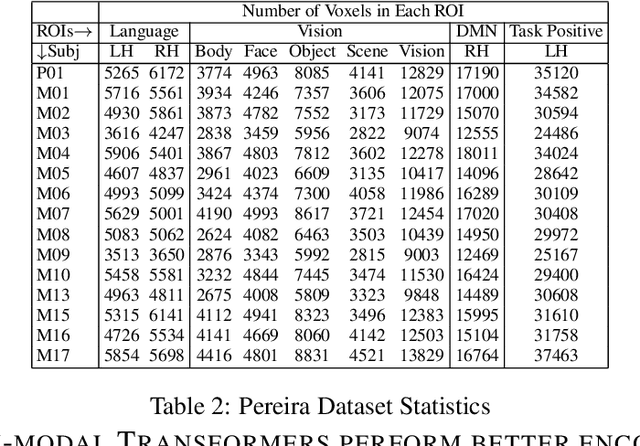
Enabling effective brain-computer interfaces requires understanding how the human brain encodes stimuli across modalities such as visual, language (or text), etc. Brain encoding aims at constructing fMRI brain activity given a stimulus. There exists a plethora of neural encoding models which study brain encoding for single mode stimuli: visual (pretrained CNNs) or text (pretrained language models). Few recent papers have also obtained separate visual and text representation models and performed late-fusion using simple heuristics. However, previous work has failed to explore: (a) the effectiveness of image Transformer models for encoding visual stimuli, and (b) co-attentive multi-modal modeling for visual and text reasoning. In this paper, we systematically explore the efficacy of image Transformers (ViT, DEiT, and BEiT) and multi-modal Transformers (VisualBERT, LXMERT, and CLIP) for brain encoding. Extensive experiments on two popular datasets, BOLD5000 and Pereira, provide the following insights. (1) To the best of our knowledge, we are the first to investigate the effectiveness of image and multi-modal Transformers for brain encoding. (2) We find that VisualBERT, a multi-modal Transformer, significantly outperforms previously proposed single-mode CNNs, image Transformers as well as other previously proposed multi-modal models, thereby establishing new state-of-the-art. The supremacy of visio-linguistic models raises the question of whether the responses elicited in the visual regions are affected implicitly by linguistic processing even when passively viewing images. Future fMRI tasks can verify this computational insight in an appropriate experimental setting.
Cross-view Brain Decoding
Apr 18, 2022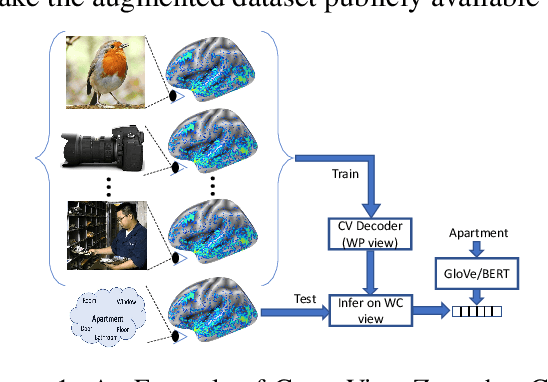
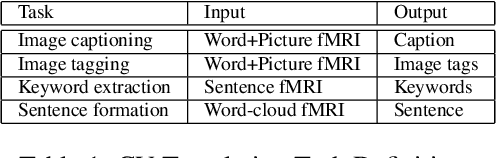
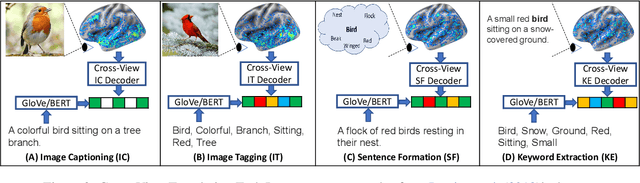
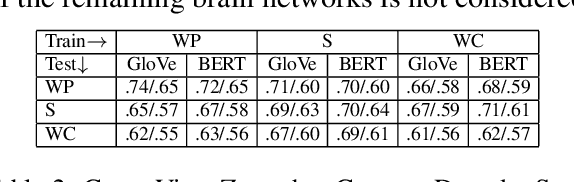
How the brain captures the meaning of linguistic stimuli across multiple views is still a critical open question in neuroscience. Consider three different views of the concept apartment: (1) picture (WP) presented with the target word label, (2) sentence (S) using the target word, and (3) word cloud (WC) containing the target word along with other semantically related words. Unlike previous efforts, which focus only on single view analysis, in this paper, we study the effectiveness of brain decoding in a zero-shot cross-view learning setup. Further, we propose brain decoding in the novel context of cross-view-translation tasks like image captioning (IC), image tagging (IT), keyword extraction (KE), and sentence formation (SF). Using extensive experiments, we demonstrate that cross-view zero-shot brain decoding is practical leading to ~0.68 average pairwise accuracy across view pairs. Also, the decoded representations are sufficiently detailed to enable high accuracy for cross-view-translation tasks with following pairwise accuracy: IC (78.0), IT (83.0), KE (83.7) and SF (74.5). Analysis of the contribution of different brain networks reveals exciting cognitive insights: (1) A high percentage of visual voxels are involved in image captioning and image tagging tasks, and a high percentage of language voxels are involved in the sentence formation and keyword extraction tasks. (2) Zero-shot accuracy of the model trained on S view and tested on WC view is better than same-view accuracy of the model trained and tested on WC view.