 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow do Language Models Generate Slang: A Systematic Comparison between Human and Machine-Generated Slang Usages
Sep 19, 2025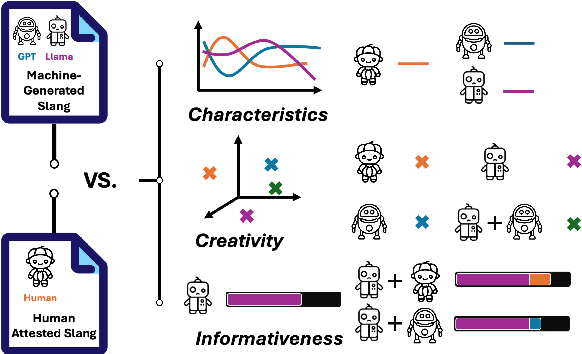

Slang is a commonly used type of informal language that poses a daunting challenge to NLP systems. Recent advances in large language models (LLMs), however, have made the problem more approachable. While LLM agents are becoming more widely applied to intermediary tasks such as slang detection and slang interpretation, their generalizability and reliability are heavily dependent on whether these models have captured structural knowledge about slang that align well with human attested slang usages. To answer this question, we contribute a systematic comparison between human and machine-generated slang usages. Our evaluative framework focuses on three core aspects: 1) Characteristics of the usages that reflect systematic biases in how machines perceive slang, 2) Creativity reflected by both lexical coinages and word reuses employed by the slang usages, and 3) Informativeness of the slang usages when used as gold-standard examples for model distillation. By comparing human-attested slang usages from the Online Slang Dictionary (OSD) and slang generated by GPT-4o and Llama-3, we find significant biases in how LLMs perceive slang. Our results suggest that while LLMs have captured significant knowledge about the creative aspects of slang, such knowledge does not align with humans sufficiently to enable LLMs for extrapolative tasks such as linguistic analyses.
Toward Informal Language Processing: Knowledge of Slang in Large Language Models
Apr 13, 2024


Recent advancement in large language models (LLMs) has offered a strong potential for natural language systems to process informal language. A representative form of informal language is slang, used commonly in daily conversations and online social media. To date, slang has not been comprehensively evaluated in LLMs due partly to the absence of a carefully designed and publicly accessible benchmark. Using movie subtitles, we construct a dataset that supports evaluation on a diverse set of tasks pertaining to automatic processing of slang. For both evaluation and finetuning, we show the effectiveness of our dataset on two core applications: 1) slang detection, and 2) identification of regional and historical sources of slang from natural sentences. We also show how our dataset can be used to probe the output distributions of LLMs for interpretive insights. We find that while LLMs such as GPT-4 achieve good performance in a zero-shot setting, smaller BERT-like models finetuned on our dataset achieve comparable performance. Furthermore, we show that our dataset enables finetuning of LLMs such as GPT-3.5 that achieve substantially better performance than strong zero-shot baselines. Our work offers a comprehensive evaluation and a high-quality benchmark on English slang based on the OpenSubtitles corpus, serving both as a publicly accessible resource and a platform for applying tools for informal language processing.
Tracing Semantic Variation in Slang
Oct 16, 2022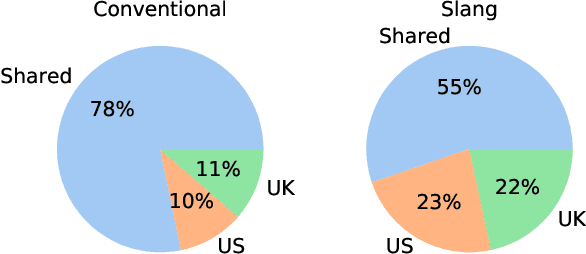
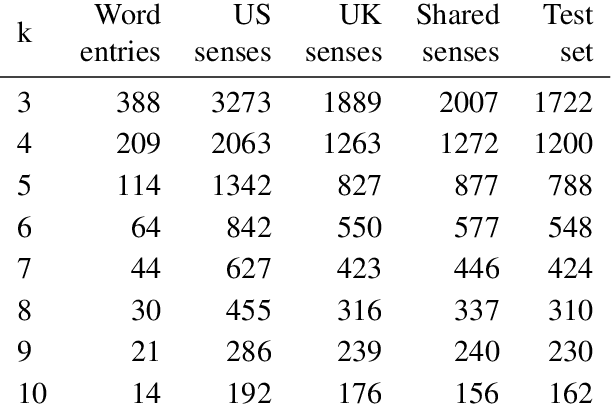

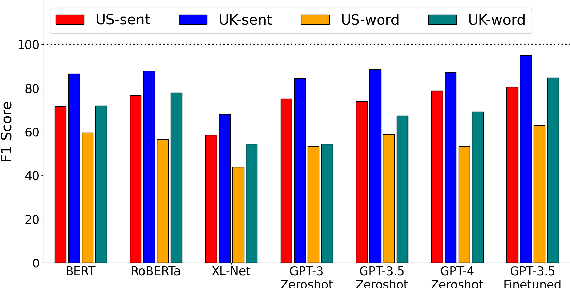
The meaning of a slang term can vary in different communities. However, slang semantic variation is not well understood and under-explored in the natural language processing of slang. One existing view argues that slang semantic variation is driven by culture-dependent communicative needs. An alternative view focuses on slang's social functions suggesting that the desire to foster semantic distinction may have led to the historical emergence of community-specific slang senses. We explore these theories using computational models and test them against historical slang dictionary entries, with a focus on characterizing regularity in the geographical variation of slang usages attested in the US and the UK over the past two centuries. We show that our models are able to predict the regional identity of emerging slang word meanings from historical slang records. We offer empirical evidence that both communicative need and semantic distinction play a role in the variation of slang meaning yet their relative importance fluctuates over the course of history. Our work offers an opportunity for incorporating historical cultural elements into the natural language processing of slang.
Semantically Informed Slang Interpretation
May 02, 2022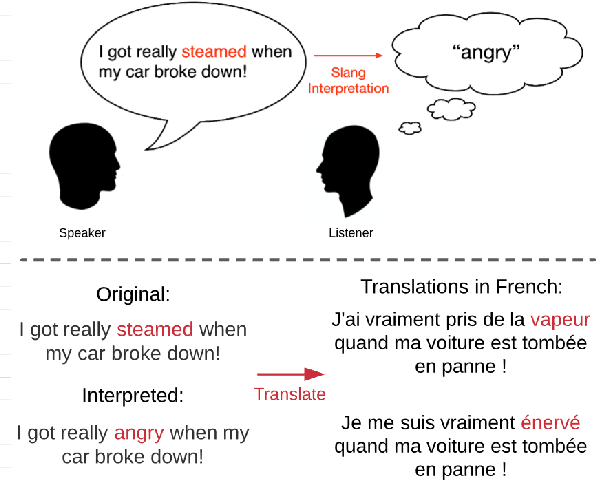



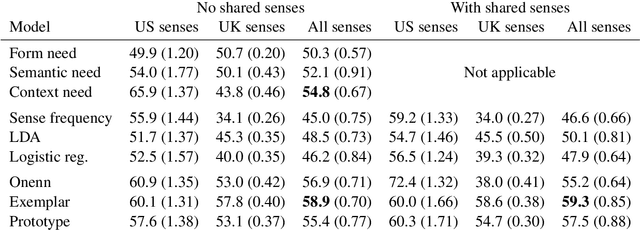
Slang is a predominant form of informal language making flexible and extended use of words that is notoriously hard for natural language processing systems to interpret. Existing approaches to slang interpretation tend to rely on context but ignore semantic extensions common in slang word usage. We propose a semantically informed slang interpretation (SSI) framework that considers jointly the contextual and semantic appropriateness of a candidate interpretation for a query slang. We perform rigorous evaluation on two large-scale online slang dictionaries and show that our approach not only achieves state-of-the-art accuracy for slang interpretation in English, but also does so in zero-shot and few-shot scenarios where training data is sparse. Furthermore, we show how the same framework can be applied to enhancing machine translation of slang from English to other languages. Our work creates opportunities for the automated interpretation and translation of informal language.
A Computational Framework for Slang Generation
Feb 03, 2021
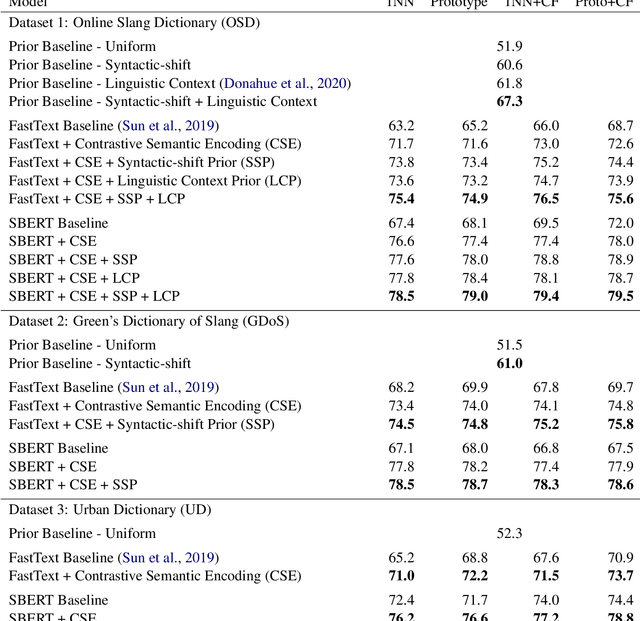
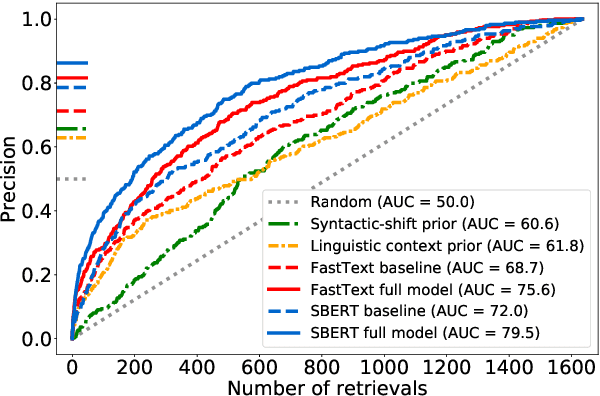

Slang is a common type of informal language, but its flexible nature and paucity of data resources present challenges for existing natural language systems. We take an initial step toward machine generation of slang by developing a framework that models the speaker's word choice in slang context. Our framework encodes novel slang meaning by relating the conventional and slang senses of a word while incorporating syntactic and contextual knowledge in slang usage. We construct the framework using a combination of probabilistic inference and neural contrastive learning. We perform rigorous evaluations on three slang dictionaries and show that our approach not only outperforms state-of-the-art language models, but also better predicts the historical emergence of slang word usages from 1960s to 2000s. We interpret the proposed models and find that the contrastively learned semantic space is sensitive to the similarities between slang and conventional senses of words. Our work creates opportunities for the automated generation and interpretation of informal language.