 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey of Accelerated Generation Techniques in Large Language Models
May 15, 2024Despite the crucial importance of accelerating text generation in large language models (LLMs) for efficiently producing content, the sequential nature of this process often leads to high inference latency, posing challenges for real-time applications. Various techniques have been proposed and developed to address these challenges and improve efficiency. This paper presents a comprehensive survey of accelerated generation techniques in autoregressive language models, aiming to understand the state-of-the-art methods and their applications. We categorize these techniques into several key areas: speculative decoding, early exiting mechanisms, and non-autoregressive methods. We discuss each category's underlying principles, advantages, limitations, and recent advancements. Through this survey, we aim to offer insights into the current landscape of techniques in LLMs and provide guidance for future research directions in this critical area of natural language processing.
Adversarial Learning for Zero-Shot Stance Detection on Social Media
May 14, 2021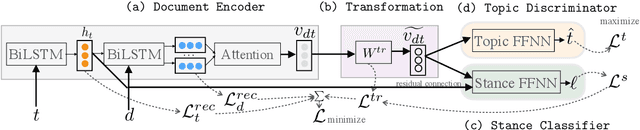
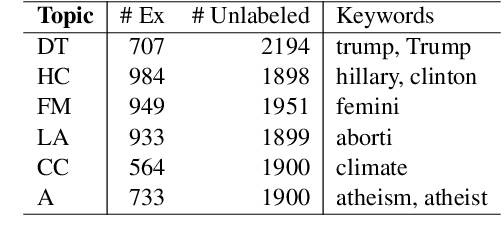
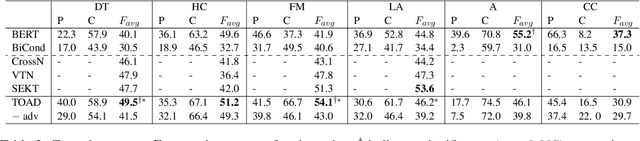
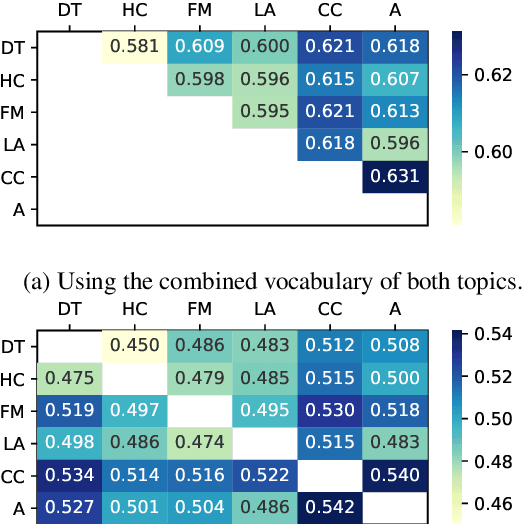
Stance detection on social media can help to identify and understand slanted news or commentary in everyday life. In this work, we propose a new model for zero-shot stance detection on Twitter that uses adversarial learning to generalize across topics. Our model achieves state-of-the-art performance on a number of unseen test topics with minimal computational costs. In addition, we extend zero-shot stance detection to new topics, highlighting future directions for zero-shot transfer.
Vehicle Trajectory Prediction by Transfer Learning of Semi-Supervised Models
Jul 14, 2020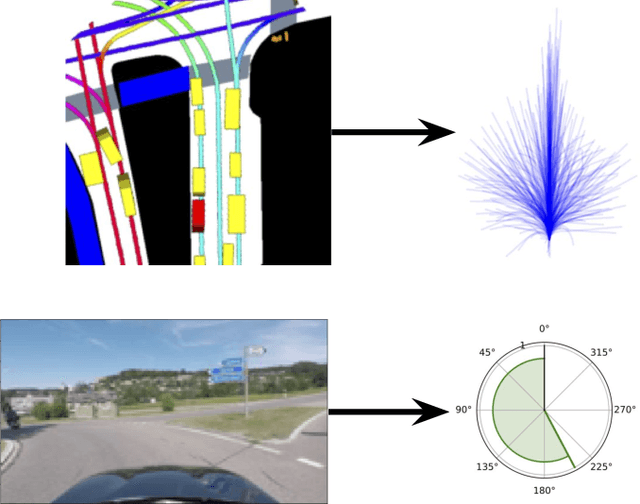
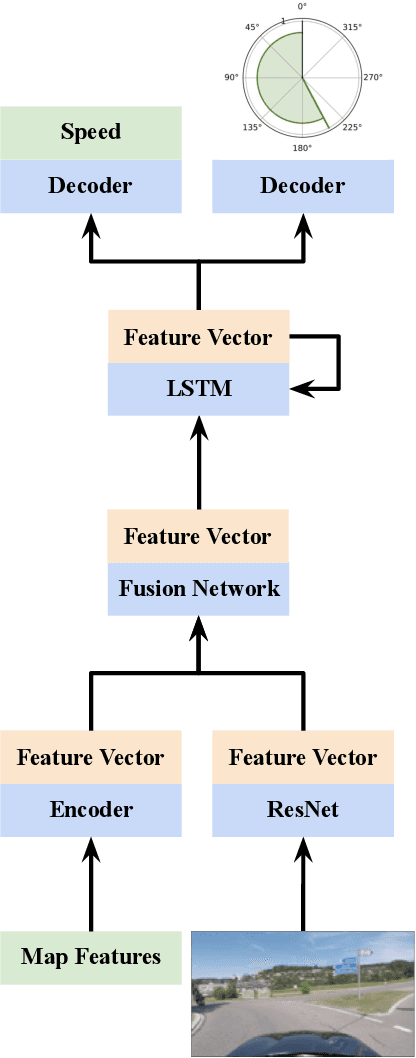
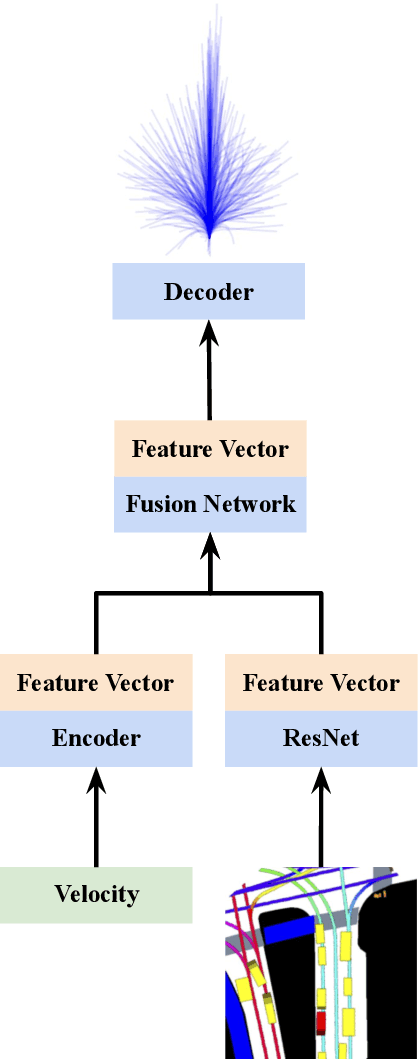
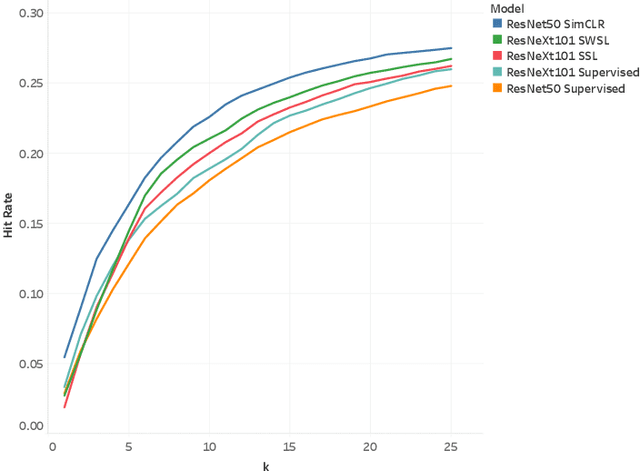
In this work we show that semi-supervised models for vehicle trajectory prediction significantly improve performance over supervised models on state-of-the-art real-world benchmarks. Moving from supervised to semi-supervised models allows scaling-up by using unlabeled data, increasing the number of images in pre-training from Millions to a Billion. We perform ablation studies comparing transfer learning of semi-supervised and supervised models while keeping all other factors equal. Within semi-supervised models we compare contrastive learning with teacher-student methods as well as networks predicting a small number of trajectories with networks predicting probabilities over a large trajectory set. Our results using both low-level and mid-level representations of the driving environment demonstrate the applicability of semi-supervised methods for real-world vehicle trajectory prediction.
Image to Language Understanding: Captioning approach
Feb 21, 2020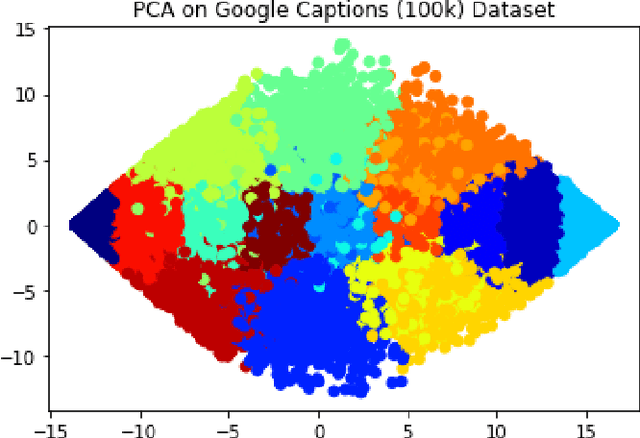
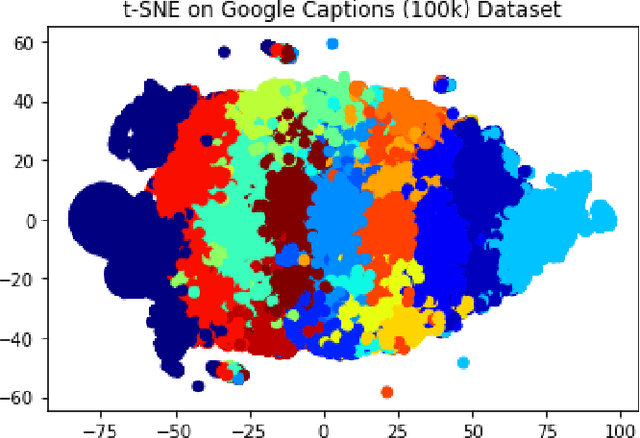
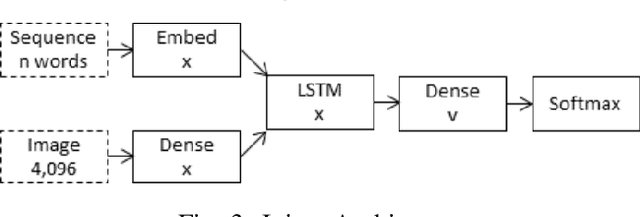
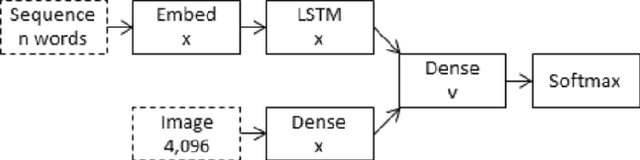
Extracting context from visual representations is of utmost importance in the advancement of Computer Science. Representation of such a format in Natural Language has a huge variety of applications such as helping the visually impaired etc. Such an approach is a combination of Computer Vision and Natural Language techniques which is a hard problem to solve. This project aims to compare different approaches for solving the image captioning problem. In specific, the focus was on comparing two different types of models: Encoder-Decoder approach and a Multi-model approach. In the encoder-decoder approach, inject and merge architectures were compared against a multi-modal image captioning approach based primarily on object detection. These approaches have been compared on the basis on state of the art sentence comparison metrics such as BLEU, GLEU, Meteor, and Rouge on a subset of the Google Conceptual captions dataset which contains 100k images. On the basis of this comparison, we observed that the best model was the Inception injected encoder model. This best approach has been deployed as a web-based system. On uploading an image, such a system will output the best caption associated with the image.