 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual effects of sentiment deployment in human and machine translation
Feb 25, 2025This paper illustrates how the overall sentiment of a text may be shifted in translation and the implications for automated sentiment analyses, particularly those that utilize machine translation and assess findings via semantic similarity metrics. While human and machine translation will produce more lemmas that fit the expected frequency of sentiment in the target language, only machine translation will also reduce the overall semantic field of the text, particularly in regard to words with epistemic content.
Image to Language Understanding: Captioning approach
Feb 21, 2020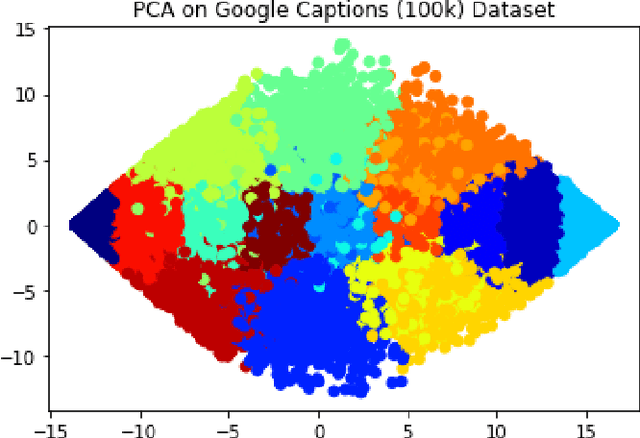
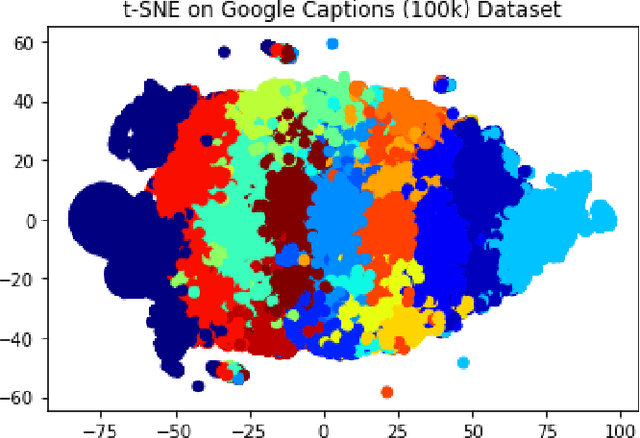
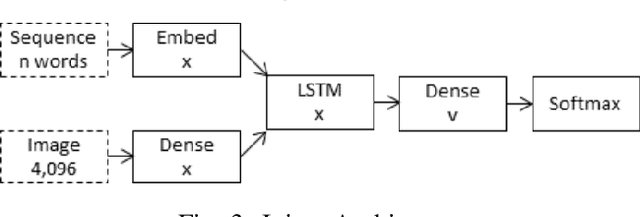
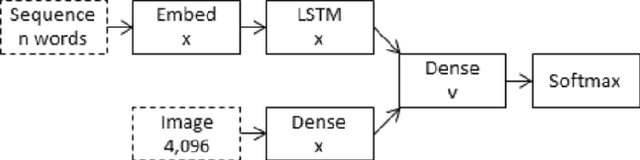
Extracting context from visual representations is of utmost importance in the advancement of Computer Science. Representation of such a format in Natural Language has a huge variety of applications such as helping the visually impaired etc. Such an approach is a combination of Computer Vision and Natural Language techniques which is a hard problem to solve. This project aims to compare different approaches for solving the image captioning problem. In specific, the focus was on comparing two different types of models: Encoder-Decoder approach and a Multi-model approach. In the encoder-decoder approach, inject and merge architectures were compared against a multi-modal image captioning approach based primarily on object detection. These approaches have been compared on the basis on state of the art sentence comparison metrics such as BLEU, GLEU, Meteor, and Rouge on a subset of the Google Conceptual captions dataset which contains 100k images. On the basis of this comparison, we observed that the best model was the Inception injected encoder model. This best approach has been deployed as a web-based system. On uploading an image, such a system will output the best caption associated with the image.