 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePenguins Don't Fly: Reasoning about Generics through Instantiations and Exceptions
Paper and Code
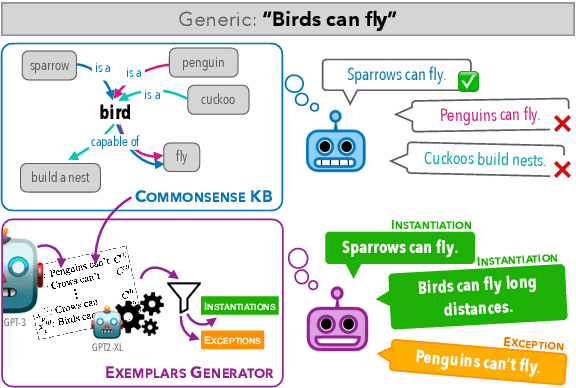


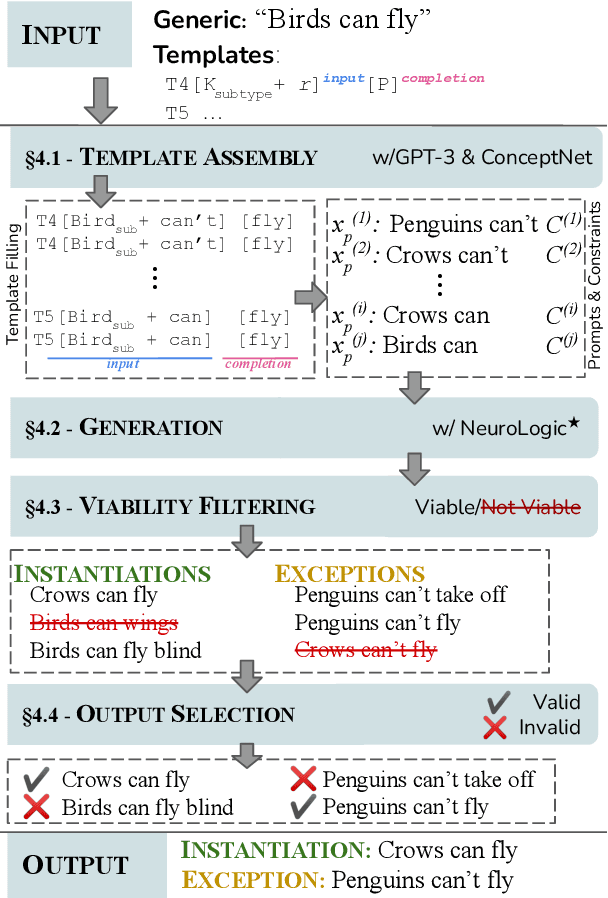
Generics express generalizations about the world (e.g., "birds can fly"). However, they are not universally true -- while sparrows and penguins are both birds, only sparrows can fly and penguins cannot. Commonsense knowledge bases, which are used extensively in many NLP tasks as a source of world-knowledge, can often encode generic knowledge but, by-design, cannot encode such exceptions. Therefore, it is crucial to realize the specific instances when a generic statement is true or false. In this work, we present a novel framework to generate pragmatically relevant true and false instances of a generic. We use pre-trained language models, constraining the generation based on insights from linguistic theory, and produce ${\sim}20k$ exemplars for ${\sim}650$ generics. Our system outperforms few-shot generation from GPT-3 (by 12.5 precision points) and our analysis highlights the importance of constrained decoding for this task and the implications of generics exemplars for language inference tasks.