 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theoretical Framework for Self-Play Theorem Proving Algorithms
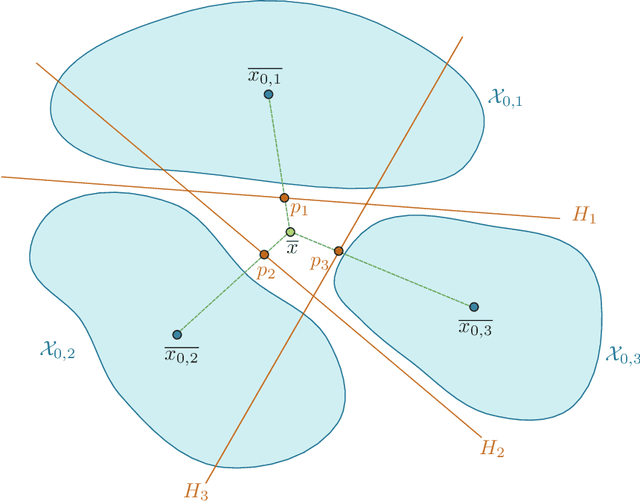
Jun 01, 2026Self-play, a type of training algorithm that enables a model to self-improve, has recently shown promising empirical results in the context of formal theorem proving using Large Language Models (LLMs). (Dong & Ma, 2025) instantiate self-play with two cooperating agents: a prover, which proves theorems, and a conjecturer, which generates new theorems as a curriculum to the prover. In this paper, we provide a theoretical framework for understanding the self-improvement capabilities of self-play algorithms for theorem proving. First, we formalize the set of theorems as a graph, with nodes as theorems and edges between pairs of theorems with similar semantics. We introduce a set of primitive assumptions that characterize the guarantees of a trained prover and how a conjecturer can access the structure of the graph. Second, we show that if the underlying graph of theorems is well-connected, then a prover-conjecturer system, where the conjecturing algorithm is based on a reversible random walk, is sufficient to grow the set of proved theorems exponentially. Third, motivated by an issue encountered empirically by self-play algorithms, where the conjecturer tends to generate artificially complex and non-fundamental theorems, we propose a diversity measure for a training distribution of theorems generated by a conjecturer and an improved conjecturing algorithm that locally maximizes this diversity measure, by computing the diffusion similarity between neighboring theorems in the theorem graph. Finally, we describe a method to compute the diffusion similarity by using contrastive learning to embed nodes into Euclidean space and then computing the inner-product between embeddings.
Architecture independent generalization bounds for overparametrized deep ReLU networks
Apr 09, 2025We prove that overparametrized neural networks are able to generalize with a test error that is independent of the level of overparametrization, and independent of the Vapnik-Chervonenkis (VC) dimension. We prove explicit bounds that only depend on the metric geometry of the test and training sets, on the regularity properties of the activation function, and on the operator norms of the weights and norms of biases. For overparametrized deep ReLU networks with a training sample size bounded by the input space dimension, we explicitly construct zero loss minimizers without use of gradient descent, and prove that the generalization error is independent of the network architecture.
Zero loss guarantees and explicit minimizers for generic overparametrized Deep Learning networks
Feb 19, 2025We determine sufficient conditions for overparametrized deep learning (DL) networks to guarantee the attainability of zero loss in the context of supervised learning, for the $\mathcal{L}^2$ cost and {\em generic} training data. We present an explicit construction of the zero loss minimizers without invoking gradient descent. On the other hand, we point out that increase of depth can deteriorate the efficiency of cost minimization using a gradient descent algorithm by analyzing the conditions for rank loss of the training Jacobian. Our results clarify key aspects on the dichotomy between zero loss reachability in underparametrized versus overparametrized DL.
Learning Symbolic Task Decompositions for Multi-Agent Teams
Feb 19, 2025



One approach for improving sample efficiency in cooperative multi-agent learning is to decompose overall tasks into sub-tasks that can be assigned to individual agents. We study this problem in the context of reward machines: symbolic tasks that can be formally decomposed into sub-tasks. In order to handle settings without a priori knowledge of the environment, we introduce a framework that can learn the optimal decomposition from model-free interactions with the environment. Our method uses a task-conditioned architecture to simultaneously learn an optimal decomposition and the corresponding agents' policies for each sub-task. In doing so, we remove the need for a human to manually design the optimal decomposition while maintaining the sample-efficiency benefits of improved credit assignment. We provide experimental results in several deep reinforcement learning settings, demonstrating the efficacy of our approach. Our results indicate that our approach succeeds even in environments with codependent agent dynamics, enabling synchronous multi-agent learning not achievable in previous works.
Derivation of effective gradient flow equations and dynamical truncation of training data in Deep Learning
Jan 13, 2025We derive explicit equations governing the cumulative biases and weights in Deep Learning with ReLU activation function, based on gradient descent for the Euclidean cost in the input layer, and under the assumption that the weights are, in a precise sense, adapted to the coordinate system distinguished by the activations. We show that gradient descent corresponds to a dynamical process in the input layer, whereby clusters of data are progressively reduced in complexity ("truncated") at an exponential rate that increases with the number of data points that have already been truncated. We provide a detailed discussion of several types of solutions to the gradient flow equations. A main motivation for this work is to shed light on the interpretability question in supervised learning.
Gradient flow in parameter space is equivalent to linear interpolation in output space
Aug 02, 2024We prove that the usual gradient flow in parameter space that underlies many training algorithms for neural networks in deep learning can be continuously deformed into an adapted gradient flow which yields (constrained) Euclidean gradient flow in output space. Moreover, if the Jacobian of the outputs with respect to the parameters is full rank (for fixed training data), then the time variable can be reparametrized so that the resulting flow is simply linear interpolation, and a global minimum can be achieved.
Interpretable global minima of deep ReLU neural networks on sequentially separable data
May 11, 2024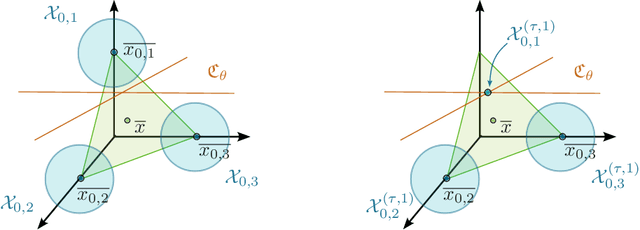

We explicitly construct zero loss neural network classifiers. We write the weight matrices and bias vectors in terms of cumulative parameters, which determine truncation maps acting recursively on input space. The configurations for the training data considered are (i) sufficiently small, well separated clusters corresponding to each class, and (ii) equivalence classes which are sequentially linearly separable. In the best case, for $Q$ classes of data in $\mathbb{R}^M$, global minimizers can be described with $Q(M+2)$ parameters.
Global $\mathcal{L}^2$ minimization with certainty via geometrically adapted gradient descent in Deep Learning
Nov 27, 2023We consider the gradient descent flow widely used for the minimization of the $\mathcal{L}^2$ cost function in Deep Learning networks, and introduce two modified versions; one adapted for the overparametrized setting, and the other for the underparametrized setting. Both have a clear and natural invariant geometric meaning, taking into account the pullback vector bundle structure in the overparametrized, and the pushforward vector bundle structure in the underparametrized setting. In the overparametrized case, we prove that, provided that a rank condition holds, all orbits of the modified gradient descent drive the $\mathcal{L}^2$ cost to its global minimum at a uniform exponential convergence rate. We point out relations of the latter to sub-Riemannian geometry.
Non-approximability of constructive global $\mathcal{L}^2$ minimizers by gradient descent in Deep Learning
Nov 13, 2023We analyze geometric aspects of the gradient descent algorithm in Deep Learning (DL) networks. In particular, we prove that the globally minimizing weights and biases for the $\mathcal{L}^2$ cost obtained constructively in [Chen-Munoz Ewald 2023] for underparametrized ReLU DL networks can generically not be approximated via the gradient descent flow. We therefore conclude that the method introduced in [Chen-Munoz Ewald 2023] is disjoint from the gradient descent method.
Geometric structure of Deep Learning networks and construction of global ${\mathcal L}^2$ minimizers
Sep 25, 2023In this paper, we provide a geometric interpretation of the structure of Deep Learning (DL) networks, characterized by $L$ hidden layers, a ramp activation function, an ${\mathcal L}^2$ Schatten class (or Hilbert-Schmidt) cost function, and input and output spaces ${\mathbb R}^Q$ with equal dimension $Q\geq1$. The hidden layers are defined on spaces ${\mathbb R}^{Q}$, as well. We apply our recent results on shallow neural networks to construct an explicit family of minimizers for the global minimum of the cost function in the case $L\geq Q$, which we show to be degenerate. In the context presented here, the hidden layers of the DL network "curate" the training inputs by recursive application of a truncation map that minimizes the noise to signal ratio of the training inputs. Moreover, we determine a set of $2^Q-1$ distinct degenerate local minima of the cost function.