 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreen AI: Exploring Carbon Footprints, Mitigation Strategies, and Trade Offs in Large Language Model Training
Apr 01, 2024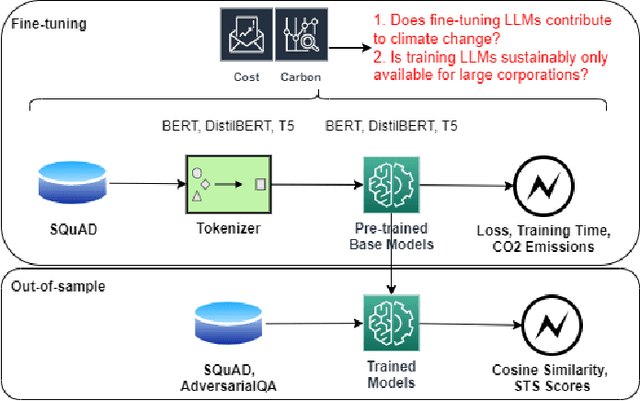
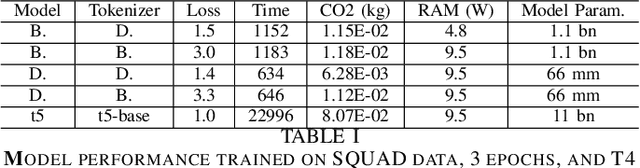
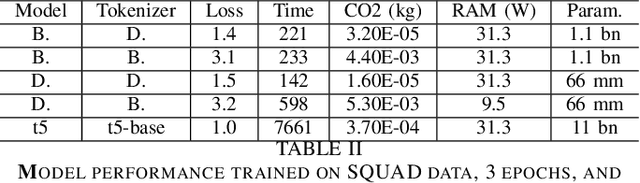
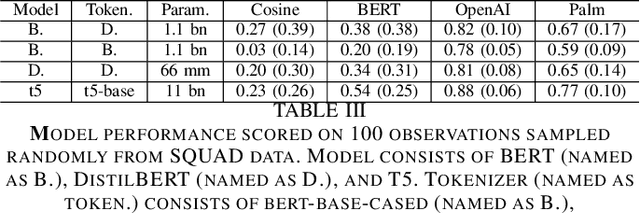
Prominent works in the field of Natural Language Processing have long attempted to create new innovative models by improving upon previous model training approaches, altering model architecture, and developing more in-depth datasets to better their performance. However, with the quickly advancing field of NLP comes increased greenhouse gas emissions, posing concerns over the environmental damage caused by training LLMs. Gaining a comprehensive understanding of the various costs, particularly those pertaining to environmental aspects, that are associated with artificial intelligence serves as the foundational basis for ensuring safe AI models. Currently, investigations into the CO2 emissions of AI models remain an emerging area of research, and as such, in this paper, we evaluate the CO2 emissions of well-known large language models, which have an especially high carbon footprint due to their significant amount of model parameters. We argue for the training of LLMs in a way that is responsible and sustainable by suggesting measures for reducing carbon emissions. Furthermore, we discuss how the choice of hardware affects CO2 emissions by contrasting the CO2 emissions during model training for two widely used GPUs. Based on our results, we present the benefits and drawbacks of our proposed solutions and make the argument for the possibility of training more environmentally safe AI models without sacrificing their robustness and performance.
Generative Disco: Text-to-Video Generation for Music Visualization
Apr 17, 2023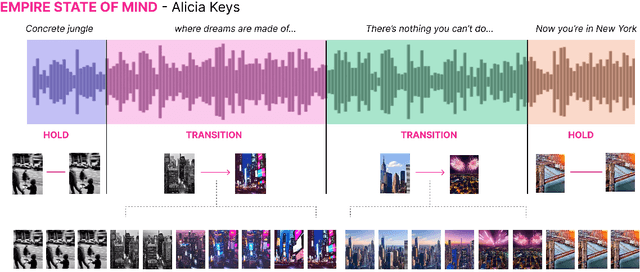

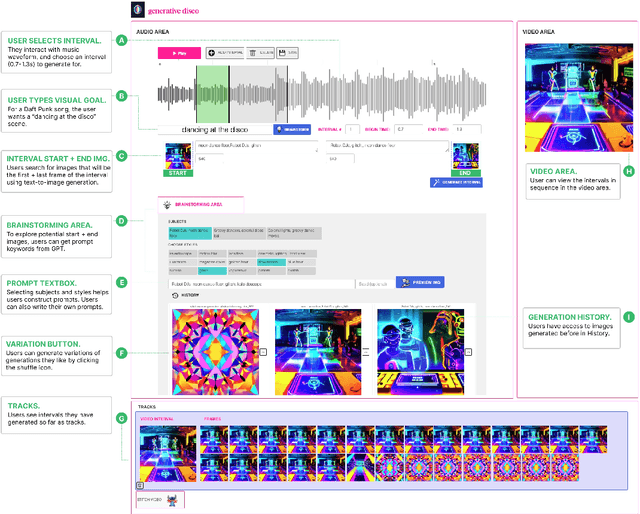
Visuals are a core part of our experience of music, owing to the way they can amplify the emotions and messages conveyed through the music. However, creating music visualization is a complex, time-consuming, and resource-intensive process. We introduce Generative Disco, a generative AI system that helps generate music visualizations with large language models and text-to-image models. Users select intervals of music to visualize and then parameterize that visualization by defining start and end prompts. These prompts are warped between and generated according to the beat of the music for audioreactive video. We introduce design patterns for improving generated videos: "transitions", which express shifts in color, time, subject, or style, and "holds", which encourage visual emphasis and consistency. A study with professionals showed that the system was enjoyable, easy to explore, and highly expressive. We conclude on use cases of Generative Disco for professionals and how AI-generated content is changing the landscape of creative work.
TextCraft: Zero-Shot Generation of High-Fidelity and Diverse Shapes from Text
Nov 04, 2022



Language is one of the primary means by which we describe the 3D world around us. While rapid progress has been made in text-to-2D-image synthesis, similar progress in text-to-3D-shape synthesis has been hindered by the lack of paired (text, shape) data. Moreover, extant methods for text-to-shape generation have limited shape diversity and fidelity. We introduce TextCraft, a method to address these limitations by producing high-fidelity and diverse 3D shapes without the need for (text, shape) pairs for training. TextCraft achieves this by using CLIP and using a multi-resolution approach by first generating in a low-dimensional latent space and then upscaling to a higher resolution, improving the fidelity of the generated shape. To improve shape diversity, we use a discrete latent space which is modelled using a bidirectional transformer conditioned on the interchangeable image-text embedding space induced by CLIP. Moreover, we present a novel variant of classifier-free guidance, which further improves the accuracy-diversity trade-off. Finally, we perform extensive experiments that demonstrate that TextCraft outperforms state-of-the-art baselines.
Sparks: Inspiration for Science Writing using Language Models
Oct 14, 2021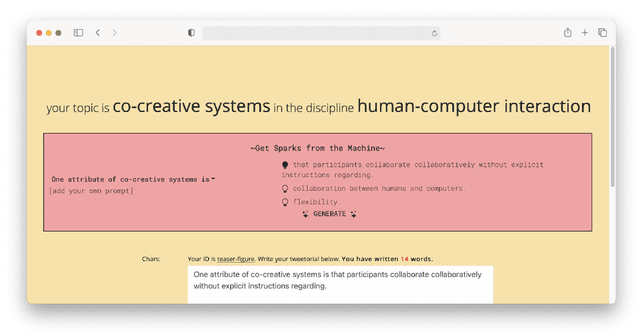


Large-scale language models are rapidly improving, performing well on a wide variety of tasks with little to no customization. In this work we investigate how language models can support science writing, a challenging writing task that is both open-ended and highly constrained. We present a system for generating "sparks", sentences related to a scientific concept intended to inspire writers. We find that our sparks are more coherent and diverse than a competitive language model baseline, and approach a human-created gold standard. In a study with 13 PhD students writing on topics of their own selection, we find three main use cases of sparks: aiding with crafting detailed sentences, providing interesting angles to engage readers, and demonstrating common reader perspectives. We also report on the various reasons sparks were considered unhelpful, and discuss how we might improve language models as writing support tools.