 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Augmentation Prediction Autoencoder with Attention Design (VAPAAD)
Apr 17, 2024



Recent advancements in sequence prediction have significantly improved the accuracy of video data interpretation; however, existing models often overlook the potential of attention-based mechanisms for next-frame prediction. This study introduces the Vision Augmentation Prediction Autoencoder with Attention Design (VAPAAD), an innovative approach that integrates attention mechanisms into sequence prediction, enabling nuanced analysis and understanding of temporal dynamics in video sequences. Utilizing the Moving MNIST dataset, we demonstrate VAPAAD's robust performance and superior handling of complex temporal data compared to traditional methods. VAPAAD combines data augmentation, ConvLSTM2D layers, and a custom-built self-attention mechanism to effectively focus on salient features within a sequence, enhancing predictive accuracy and context-aware analysis. This methodology not only adheres to human cognitive processes during video interpretation but also addresses limitations in conventional models, which often struggle with the variability inherent in video sequences. The experimental results confirm that VAPAAD outperforms existing models, especially in integrating attention mechanisms, which significantly improve predictive performance.
Green AI: Exploring Carbon Footprints, Mitigation Strategies, and Trade Offs in Large Language Model Training
Apr 01, 2024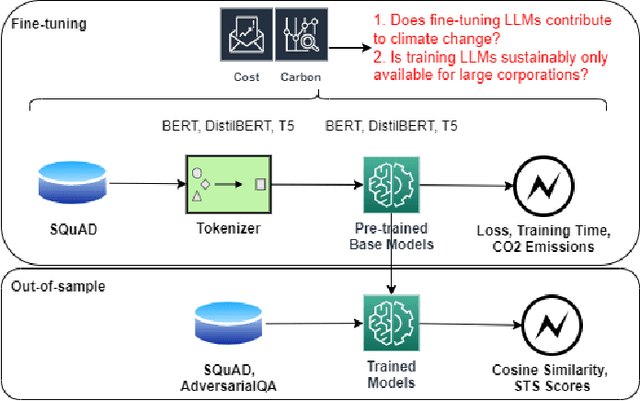
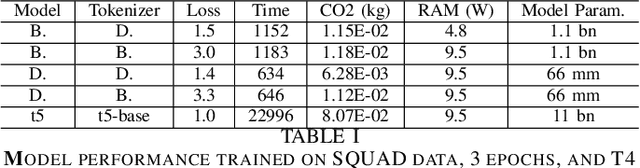
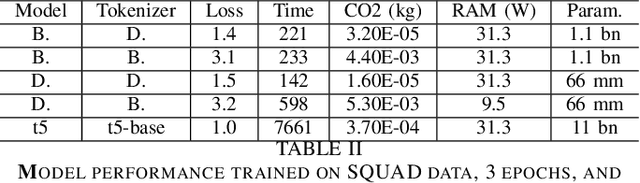
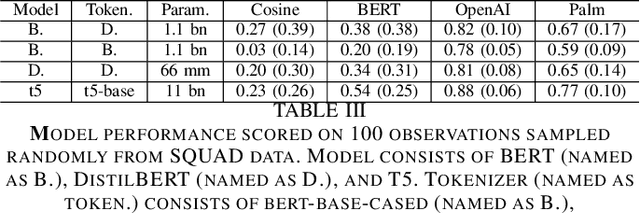
Prominent works in the field of Natural Language Processing have long attempted to create new innovative models by improving upon previous model training approaches, altering model architecture, and developing more in-depth datasets to better their performance. However, with the quickly advancing field of NLP comes increased greenhouse gas emissions, posing concerns over the environmental damage caused by training LLMs. Gaining a comprehensive understanding of the various costs, particularly those pertaining to environmental aspects, that are associated with artificial intelligence serves as the foundational basis for ensuring safe AI models. Currently, investigations into the CO2 emissions of AI models remain an emerging area of research, and as such, in this paper, we evaluate the CO2 emissions of well-known large language models, which have an especially high carbon footprint due to their significant amount of model parameters. We argue for the training of LLMs in a way that is responsible and sustainable by suggesting measures for reducing carbon emissions. Furthermore, we discuss how the choice of hardware affects CO2 emissions by contrasting the CO2 emissions during model training for two widely used GPUs. Based on our results, we present the benefits and drawbacks of our proposed solutions and make the argument for the possibility of training more environmentally safe AI models without sacrificing their robustness and performance.
A Fine-tuning Enhanced RAG System with Quantized Influence Measure as AI Judge
Feb 26, 2024This study presents an innovative enhancement to retrieval-augmented generation (RAG) systems by seamlessly integrating fine-tuned large language models (LLMs) with vector databases. This integration capitalizes on the combined strengths of structured data retrieval and the nuanced comprehension provided by advanced LLMs. Central to our approach are the LoRA and QLoRA methodologies, which stand at the forefront of model refinement through parameter-efficient fine-tuning and memory optimization. A novel feature of our research is the incorporation of user feedback directly into the training process, ensuring the model's continuous adaptation to user expectations and thus, improving its performance and applicability. Additionally, we introduce a Quantized Influence Measure (QIM) as an innovative "AI Judge" mechanism to enhance the precision of result selection, further refining the system's accuracy. Accompanied by an executive diagram and a detailed algorithm for fine-tuning QLoRA, our work provides a comprehensive framework for implementing these advancements within chatbot technologies. This research contributes significant insights into LLM optimization for specific uses and heralds new directions for further development in retrieval-augmented models. Through extensive experimentation and analysis, our findings lay a robust foundation for future advancements in chatbot technology and retrieval systems, marking a significant step forward in the creation of more sophisticated, precise, and user-centric conversational AI systems.
An Analysis of Embedding Layers and Similarity Scores using Siamese Neural Networks
Dec 31, 2023Large Lanugage Models (LLMs) are gaining increasing popularity in a variety of use cases, from language understanding and writing to assistance in application development. One of the most important aspects for optimal funcionality of LLMs is embedding layers. Word embeddings are distributed representations of words in a continuous vector space. In the context of LLMs, words or tokens from the input text are transformed into high-dimensional vectors using unique algorithms specific to the model. Our research examines the embedding algorithms from leading companies in the industry, such as OpenAI, Google's PaLM, and BERT. Using medical data, we have analyzed similarity scores of each embedding layer, observing differences in performance among each algorithm. To enhance each model and provide an additional encoding layer, we also implemented Siamese Neural Networks. After observing changes in performance with the addition of the model, we measured the carbon footage per epoch of training. The carbon footprint associated with large language models (LLMs) is a significant concern, and should be taken into consideration when selecting algorithms for a variety of use cases. Overall, our research compared the accuracy different, leading embedding algorithms and their carbon footage, allowing for a holistic review of each embedding algorithm.
An Interaction-based Convolutional Neural Network (ICNN) Towards Better Understanding of COVID-19 X-ray Images
Jun 13, 2021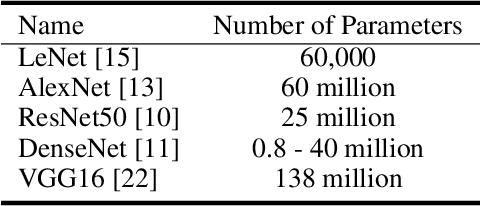
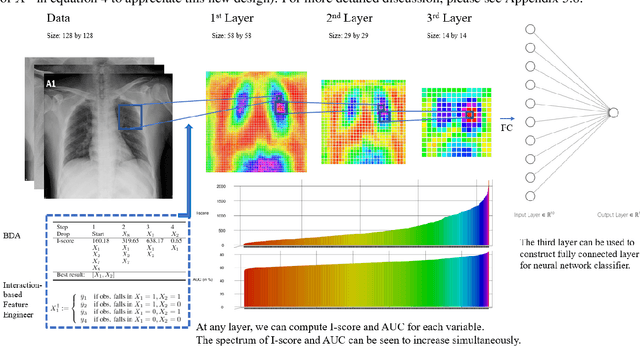

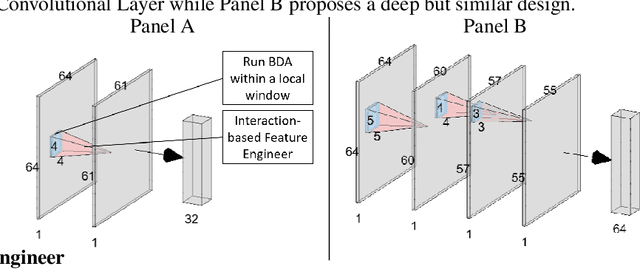
The field of Explainable Artificial Intelligence (XAI) aims to build explainable and interpretable machine learning (or deep learning) methods without sacrificing prediction performance. Convolutional Neural Networks (CNNs) have been successful in making predictions, especially in image classification. However, these famous deep learning models use tens of millions of parameters based on a large number of pre-trained filters which have been repurposed from previous data sets. We propose a novel Interaction-based Convolutional Neural Network (ICNN) that does not make assumptions about the relevance of local information. Instead, we use a model-free Influence Score (I-score) to directly extract the influential information from images to form important variable modules. We demonstrate that the proposed method produces state-of-the-art prediction performance of 99.8% on a real-world data set classifying COVID-19 Chest X-ray images without sacrificing the explanatory power of the model. This proposed design can efficiently screen COVID-19 patients before human diagnosis, and will be the benchmark for addressing future XAI problems in large-scale data sets.
A Novel Interaction-based Methodology Towards Explainable AI with Better Understanding of Pneumonia Chest X-ray Images
Apr 19, 2021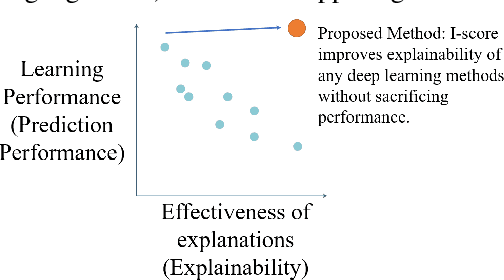
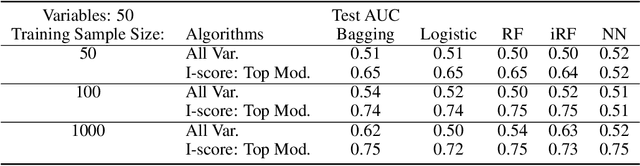
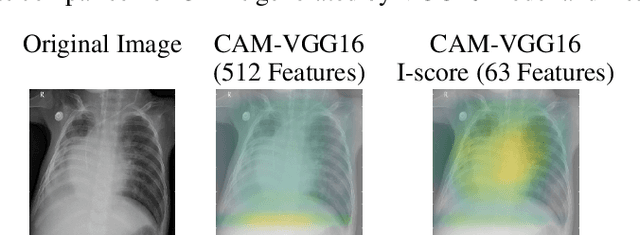
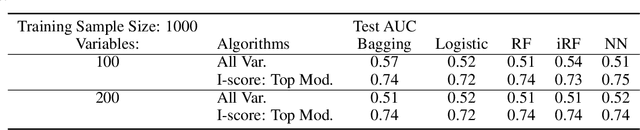
In the field of eXplainable AI (XAI), robust ``blackbox'' algorithms such as Convolutional Neural Networks (CNNs) are known for making high prediction performance. However, the ability to explain and interpret these algorithms still require innovation in the understanding of influential and, more importantly, explainable features that directly or indirectly impact the performance of predictivity. A number of methods existing in literature focus on visualization techniques but the concepts of explainability and interpretability still require rigorous definition. In view of the above needs, this paper proposes an interaction-based methodology -- Influence Score (I-score) -- to screen out the noisy and non-informative variables in the images hence it nourishes an environment with explainable and interpretable features that are directly associated to feature predictivity. We apply the proposed method on a real world application in Pneumonia Chest X-ray Image data set and produced state-of-the-art results. We demonstrate how to apply the proposed approach for more general big data problems by improving the explainability and interpretability without sacrificing the prediction performance. The contribution of this paper opens a novel angle that moves the community closer to the future pipelines of XAI problems.