 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIMRL: Combining IMitation and Reinforcement Learning for Safe Autonomous Driving
Jun 17, 2024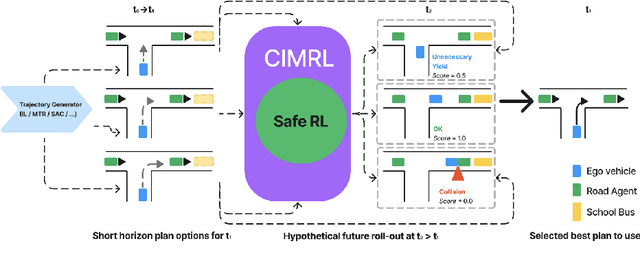


Modern approaches to autonomous driving rely heavily on learned components trained with large amounts of human driving data via imitation learning. However, these methods require large amounts of expensive data collection and even then face challenges with safely handling long-tail scenarios and compounding errors over time. At the same time, pure Reinforcement Learning (RL) methods can fail to learn performant policies in sparse, constrained, and challenging-to-define reward settings like driving. Both of these challenges make deploying purely cloned policies in safety critical applications like autonomous vehicles challenging. In this paper we propose Combining IMitation and Reinforcement Learning (CIMRL) approach - a framework that enables training driving policies in simulation through leveraging imitative motion priors and safety constraints. CIMRL does not require extensive reward specification and improves on the closed loop behavior of pure cloning methods. By combining RL and imitation, we demonstrate that our method achieves state-of-the-art results in closed loop simulation driving benchmarks.
Multi-Constraint Safe RL with Objective Suppression for Safety-Critical Applications
Feb 23, 2024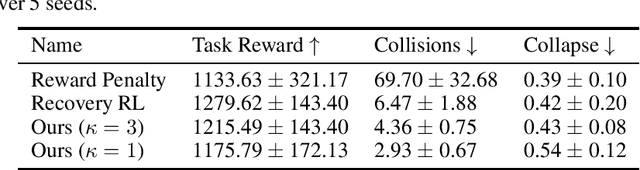

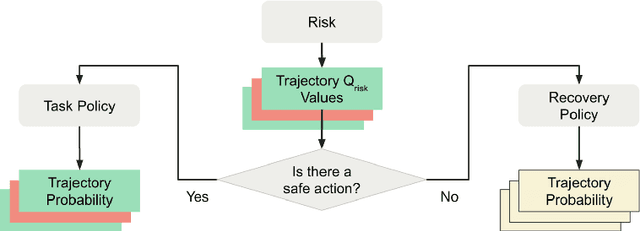
Safe reinforcement learning tasks with multiple constraints are a challenging domain despite being very common in the real world. To address this challenge, we propose Objective Suppression, a novel method that adaptively suppresses the task reward maximizing objectives according to a safety critic. We benchmark Objective Suppression in two multi-constraint safety domains, including an autonomous driving domain where any incorrect behavior can lead to disastrous consequences. Empirically, we demonstrate that our proposed method, when combined with existing safe RL algorithms, can match the task reward achieved by our baselines with significantly fewer constraint violations.
Scaling Robot Supervision to Hundreds of Hours with RoboTurk: Robotic Manipulation Dataset through Human Reasoning and Dexterity
Nov 11, 2019
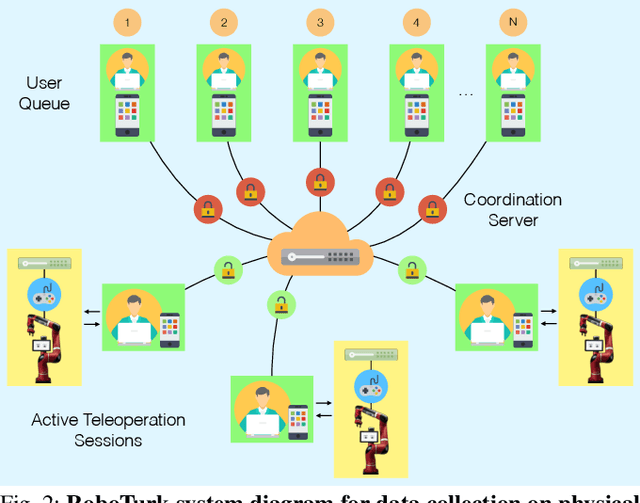

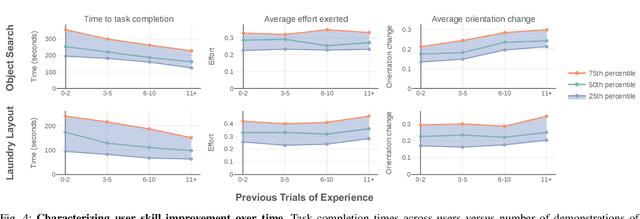
Large, richly annotated datasets have accelerated progress in fields such as computer vision and natural language processing, but replicating these successes in robotics has been challenging. While prior data collection methodologies such as self-supervision have resulted in large datasets, the data can have poor signal-to-noise ratio. By contrast, previous efforts to collect task demonstrations with humans provide better quality data, but they cannot reach the same data magnitude. Furthermore, neither approach places guarantees on the diversity of the data collected, in terms of solution strategies. In this work, we leverage and extend the RoboTurk platform to scale up data collection for robotic manipulation using remote teleoperation. The primary motivation for our platform is two-fold: (1) to address the shortcomings of prior work and increase the total quantity of manipulation data collected through human supervision by an order of magnitude without sacrificing the quality of the data and (2) to collect data on challenging manipulation tasks across several operators and observe a diverse set of emergent behaviors and solutions. We collected over 111 hours of robot manipulation data across 54 users and 3 challenging manipulation tasks in 1 week, resulting in the largest robot dataset collected via remote teleoperation. We evaluate the quality of our platform, the diversity of demonstrations in our dataset, and the utility of our dataset via quantitative and qualitative analysis. For additional results, supplementary videos, and to download our dataset, visit http://roboturk.stanford.edu/realrobotdataset .
RoboTurk: A Crowdsourcing Platform for Robotic Skill Learning through Imitation
Nov 07, 2018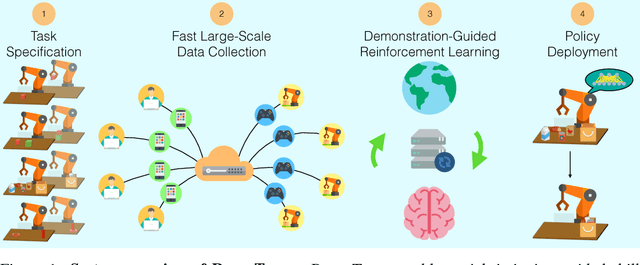

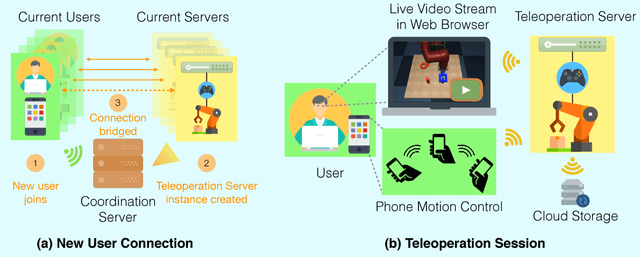
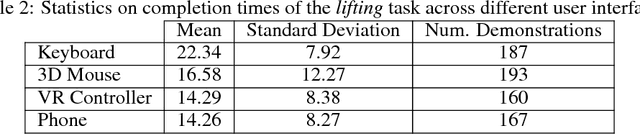
Imitation Learning has empowered recent advances in learning robotic manipulation tasks by addressing shortcomings of Reinforcement Learning such as exploration and reward specification. However, research in this area has been limited to modest-sized datasets due to the difficulty of collecting large quantities of task demonstrations through existing mechanisms. This work introduces RoboTurk to address this challenge. RoboTurk is a crowdsourcing platform for high quality 6-DoF trajectory based teleoperation through the use of widely available mobile devices (e.g. iPhone). We evaluate RoboTurk on three manipulation tasks of varying timescales (15-120s) and observe that our user interface is statistically similar to special purpose hardware such as virtual reality controllers in terms of task completion times. Furthermore, we observe that poor network conditions, such as low bandwidth and high delay links, do not substantially affect the remote users' ability to perform task demonstrations successfully on RoboTurk. Lastly, we demonstrate the efficacy of RoboTurk through the collection of a pilot dataset; using RoboTurk, we collected 137.5 hours of manipulation data from remote workers, amounting to over 2200 successful task demonstrations in 22 hours of total system usage. We show that the data obtained through RoboTurk enables policy learning on multi-step manipulation tasks with sparse rewards and that using larger quantities of demonstrations during policy learning provides benefits in terms of both learning consistency and final performance. For additional results, videos, and to download our pilot dataset, visit $\href{http://roboturk.stanford.edu/}{\texttt{roboturk.stanford.edu}}$