 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIMRL: Combining IMitation and Reinforcement Learning for Safe Autonomous Driving
Jun 17, 2024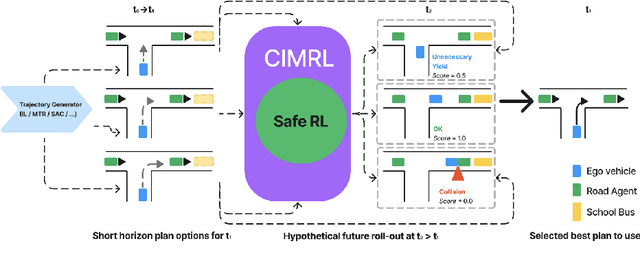

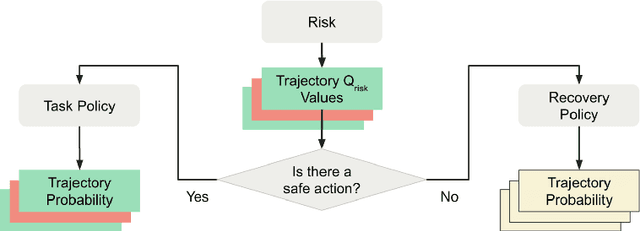

Modern approaches to autonomous driving rely heavily on learned components trained with large amounts of human driving data via imitation learning. However, these methods require large amounts of expensive data collection and even then face challenges with safely handling long-tail scenarios and compounding errors over time. At the same time, pure Reinforcement Learning (RL) methods can fail to learn performant policies in sparse, constrained, and challenging-to-define reward settings like driving. Both of these challenges make deploying purely cloned policies in safety critical applications like autonomous vehicles challenging. In this paper we propose Combining IMitation and Reinforcement Learning (CIMRL) approach - a framework that enables training driving policies in simulation through leveraging imitative motion priors and safety constraints. CIMRL does not require extensive reward specification and improves on the closed loop behavior of pure cloning methods. By combining RL and imitation, we demonstrate that our method achieves state-of-the-art results in closed loop simulation driving benchmarks.
Online Tool Selection with Learned Grasp Prediction Models
Feb 15, 2023
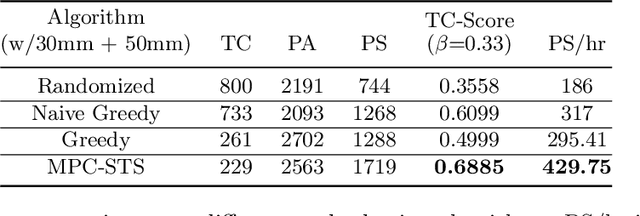
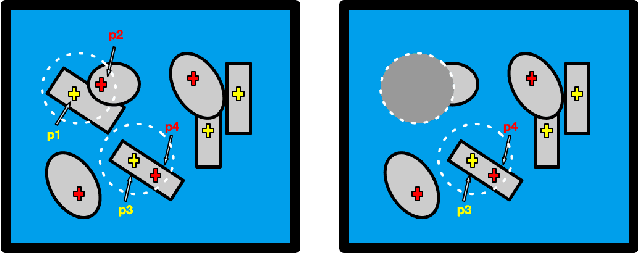
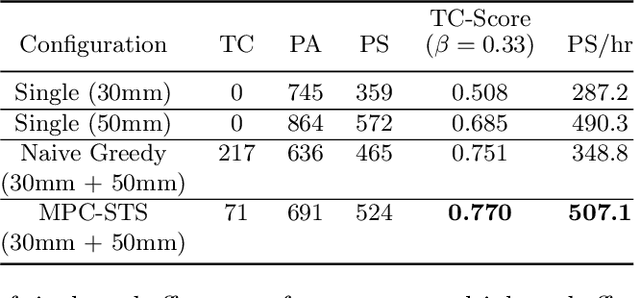
Deep learning-based grasp prediction models have become an industry standard for robotic bin-picking systems. To maximize pick success, production environments are often equipped with several end-effector tools that can be swapped on-the-fly, based on the target object. Tool-change, however, takes time. Choosing the order of grasps to perform, and corresponding tool-change actions, can improve system throughput; this is the topic of our work. The main challenge in planning tool change is uncertainty - we typically cannot see objects in the bin that are currently occluded. Inspired by queuing and admission control problems, we model the problem as a Markov Decision Process (MDP), where the goal is to maximize expected throughput, and we pursue an approximate solution based on model predictive control, where at each time step we plan based only on the currently visible objects. Special to our method is the idea of void zones, which are geometrical boundaries in which an unknown object will be present, and therefore cannot be accounted for during planning. Our planning problem can be solved using integer linear programming (ILP). However, we find that an approximate solution based on sparse tree search yields near optimal performance at a fraction of the time. Another question that we explore is how to measure the performance of tool-change planning: we find that throughput alone can fail to capture delicate and smooth behavior, and propose a principled alternative. Finally, we demonstrate our algorithms on both synthetic and real world bin picking tasks.
Self-Supervised Goal-Conditioned Pick and Place
Aug 26, 2020
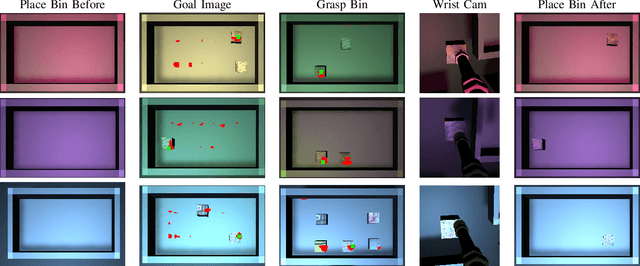
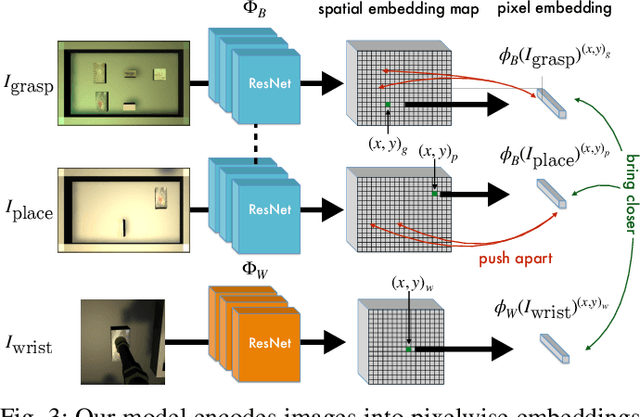

Robots have the capability to collect large amounts of data autonomously by interacting with objects in the world. However, it is often not obvious \emph{how} to learning from autonomously collected data without human-labeled supervision. In this work we learn pixel-wise object representations from unsupervised pick and place data that generalize to new objects. We introduce a novel framework for using these representations in order to predict where to pick and where to place in order to match a goal image. Finally, we demonstrate the utility of our approach in a simulated grasping environment.
Decision-Theoretic Planning with Concurrent Temporally Extended Actions
Jan 10, 2013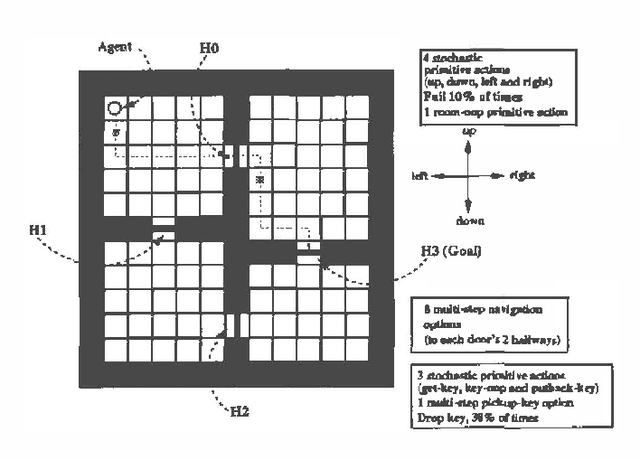
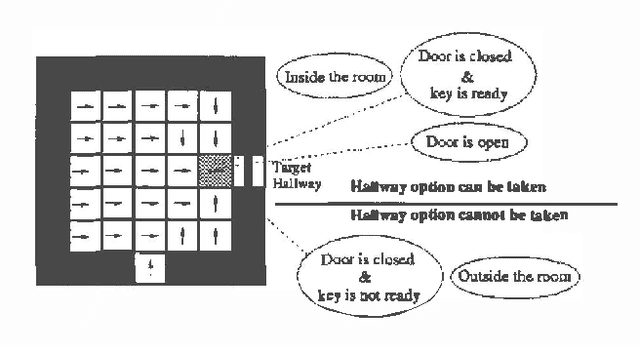
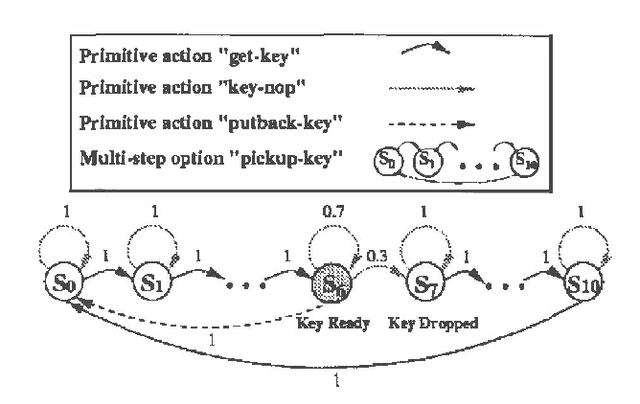
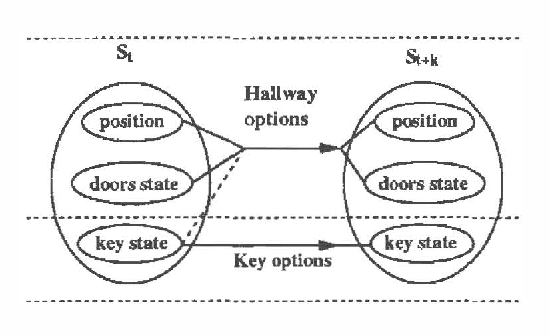
We investigate a model for planning under uncertainty with temporallyextended actions, where multiple actions can be taken concurrently at each decision epoch. Our model is based on the options framework, and combines it with factored state space models,where the set of options can be partitioned into classes that affectdisjoint state variables. We show that the set of decisionepochs for concurrent options defines a semi-Markov decisionprocess, if the underlying temporally extended actions being parallelized arerestricted to Markov options. This property allows us to use SMDPalgorithms for computing the value function over concurrentoptions. The concurrent options model allows overlapping execution ofoptions in order to achieve higher performance or in order to performa complex task. We describe a simple experiment using a navigationtask which illustrates how concurrent options results in a faster planwhen compared to the case when only one option is taken at a time.