Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Goal-Conditioned Pick and Place
Aug 26, 2020
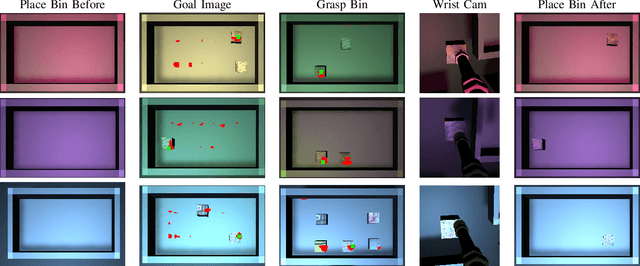
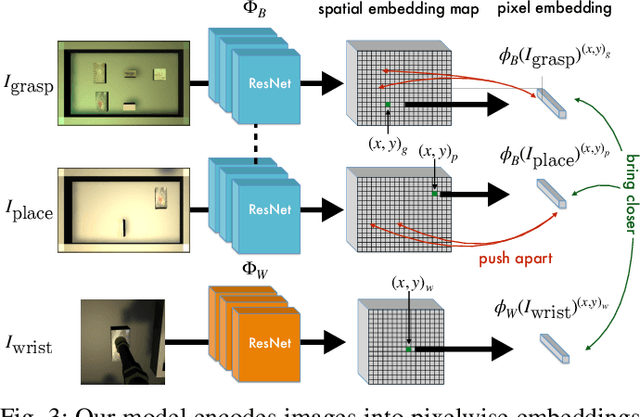

Robots have the capability to collect large amounts of data autonomously by interacting with objects in the world. However, it is often not obvious \emph{how} to learning from autonomously collected data without human-labeled supervision. In this work we learn pixel-wise object representations from unsupervised pick and place data that generalize to new objects. We introduce a novel framework for using these representations in order to predict where to pick and where to place in order to match a goal image. Finally, we demonstrate the utility of our approach in a simulated grasping environment.
* In RSS 2020 Visual Learning and Reasoning for Robotic Manipulation
Workshop
Via