 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACDC: Automated Creation of Digital Cousins for Robust Policy Learning
Oct 09, 2024



Training robot policies in the real world can be unsafe, costly, and difficult to scale. Simulation serves as an inexpensive and potentially limitless source of training data, but suffers from the semantics and physics disparity beween simulated and real-world environments. These discrepancies can be minimized by training in digital twins,which serve as virtual replicas of a real scene but are expensive to generate and cannot produce cross-domain generalization. To address these limitations, we propose the concept of digital cousins, a virtual asset or scene that, unlike a digital twin,does not explicitly model a real-world counterpart but still exhibits similar geometric and semantic affordances. As a result, digital cousins simultaneously reduce the cost of generating an analogous virtual environment while also facilitating better robustness during sim-to-real domain transfer by providing a distribution of similar training scenes. Leveraging digital cousins, we introduce a novel method for the Automatic Creation of Digital Cousins (ACDC), and propose a fully automated real-to-sim-to-real pipeline for generating fully interactive scenes and training robot policies that can be deployed zero-shot in the original scene. We find that ACDC can produce digital cousin scenes that preserve geometric and semantic affordances, and can be used to train policies that outperform policies trained on digital twins, achieving 90% vs. 25% under zero-shot sim-to-real transfer. Additional details are available at https://digital-cousins.github.io/.
FDNeRF: Semantics-Driven Face Reconstruction, Prompt Editing and Relighting with Diffusion Models
Jun 01, 2023

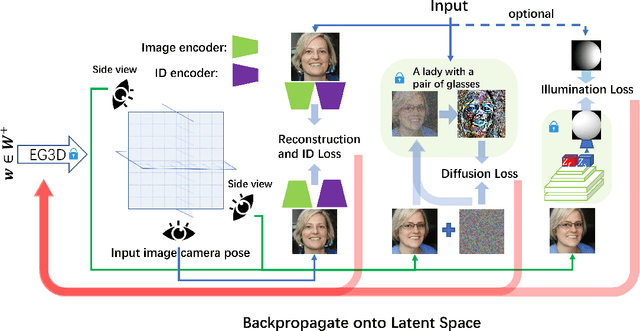
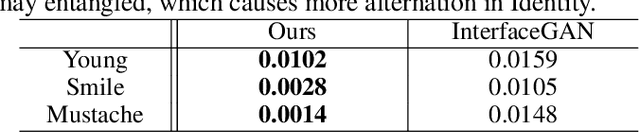
The ability to create high-quality 3D faces from a single image has become increasingly important with wide applications in video conferencing, AR/VR, and advanced video editing in movie industries. In this paper, we propose Face Diffusion NeRF (FDNeRF), a new generative method to reconstruct high-quality Face NeRFs from single images, complete with semantic editing and relighting capabilities. FDNeRF utilizes high-resolution 3D GAN inversion and expertly trained 2D latent-diffusion model, allowing users to manipulate and construct Face NeRFs in zero-shot learning without the need for explicit 3D data. With carefully designed illumination and identity preserving loss, as well as multi-modal pre-training, FD-NeRF offers users unparalleled control over the editing process enabling them to create and edit face NeRFs using just single-view images, text prompts, and explicit target lighting. The advanced features of FDNeRF have been designed to produce more impressive results than existing 2D editing approaches that rely on 2D segmentation maps for editable attributes. Experiments show that our FDNeRF achieves exceptionally realistic results and unprecedented flexibility in editing compared with state-of-the-art 3D face reconstruction and editing methods. Our code will be available at https://github.com/BillyXYB/FDNeRF.
FLNeRF: 3D Facial Landmarks Estimation in Neural Radiance Fields
Nov 22, 2022This paper presents the first significant work on directly predicting 3D face landmarks on neural radiance fields (NeRFs), without using intermediate representations such as 2D images, depth maps, or point clouds. Our 3D coarse-to-fine Face Landmarks NeRF (FLNeRF) model efficiently samples from the NeRF on the whole face with individual facial features for accurate landmarks. To mitigate the limited number of facial expressions in the available data, local and non-linear NeRF warp is applied at facial features in fine scale to simulate large emotions range, including exaggerated facial expressions (e.g., cheek blowing, wide opening mouth, eye blinking), for training FLNeRF. With such expression augmentation, our model can predict 3D landmarks not limited to the 20 discrete expressions given in the data. Robust 3D NeRF facial landmarks contribute to many downstream tasks. As an example, we modify MoFaNeRF to enable high-quality face editing and swapping using face landmarks on NeRF, allowing more direct control and wider range of complex expressions. Experiments show that the improved model using landmarks achieves comparable to better results.