 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVALL-T: Decoder-Only Generative Transducer for Robust and Decoding-Controllable Text-to-Speech
Paper and Code
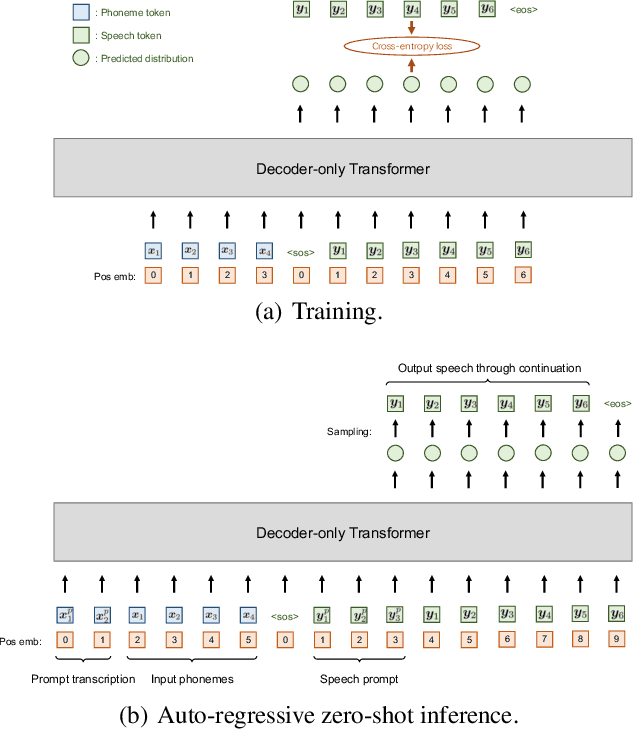
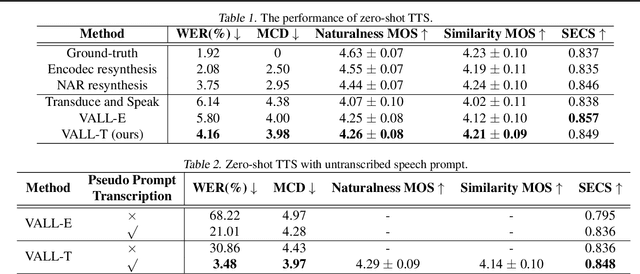
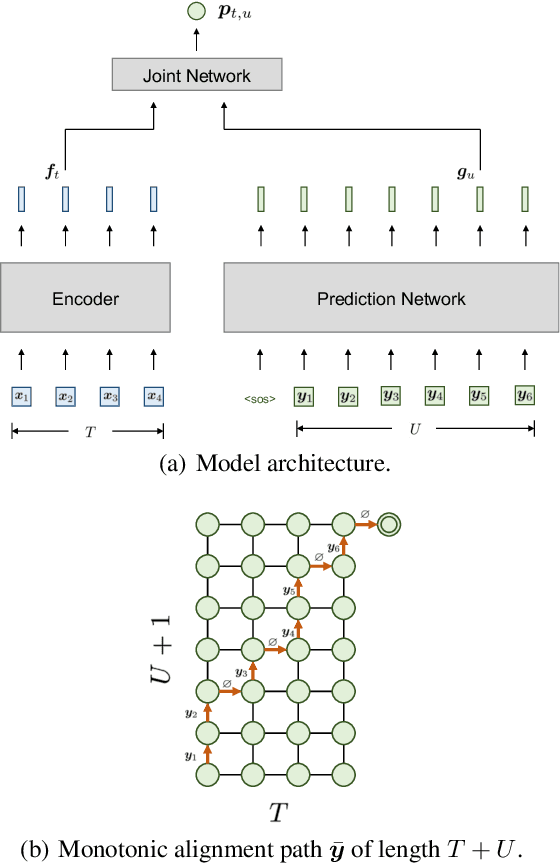
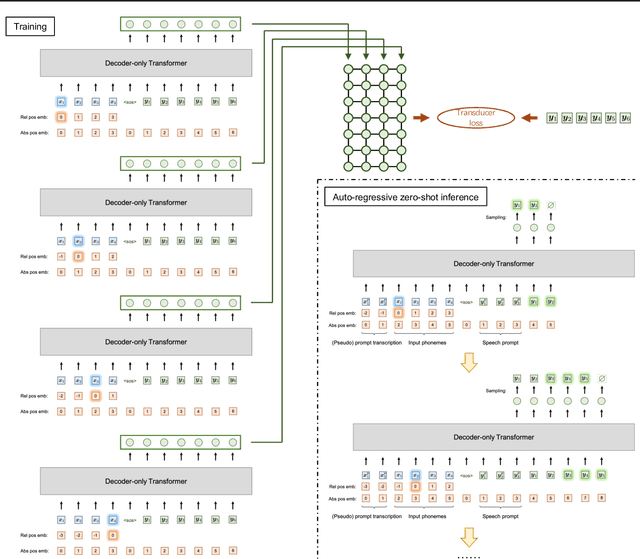
Recent TTS models with decoder-only Transformer architecture, such as SPEAR-TTS and VALL-E, achieve impressive naturalness and demonstrate the ability for zero-shot adaptation given a speech prompt. However, such decoder-only TTS models lack monotonic alignment constraints, sometimes leading to hallucination issues such as mispronunciation, word skipping and repeating. To address this limitation, we propose VALL-T, a generative Transducer model that introduces shifting relative position embeddings for input phoneme sequence, explicitly indicating the monotonic generation process while maintaining the architecture of decoder-only Transformer. Consequently, VALL-T retains the capability of prompt-based zero-shot adaptation and demonstrates better robustness against hallucinations with a relative reduction of 28.3% in the word error rate. Furthermore, the controllability of alignment in VALL-T during decoding facilitates the use of untranscribed speech prompts, even in unknown languages. It also enables the synthesis of lengthy speech by utilizing an aligned context window.