 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-Autoregressive Neural Codec Language Models for Efficient Zero-Shot Text-to-Speech Synthesis
Paper and Code

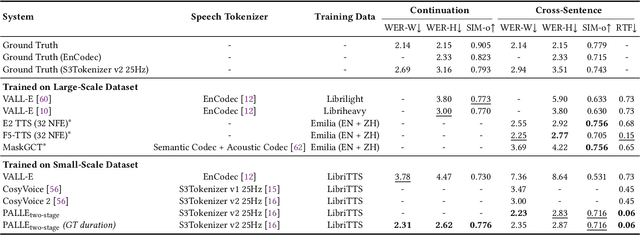

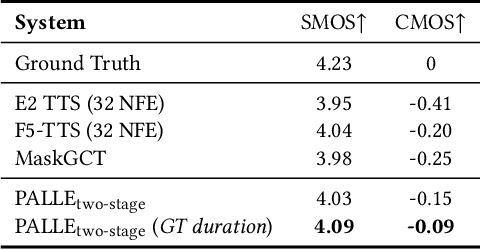
Recent zero-shot text-to-speech (TTS) systems face a common dilemma: autoregressive (AR) models suffer from slow generation and lack duration controllability, while non-autoregressive (NAR) models lack temporal modeling and typically require complex designs. In this paper, we introduce a novel pseudo-autoregressive (PAR) codec language modeling approach that unifies AR and NAR modeling. Combining explicit temporal modeling from AR with parallel generation from NAR, PAR generates dynamic-length spans at fixed time steps. Building on PAR, we propose PALLE, a two-stage TTS system that leverages PAR for initial generation followed by NAR refinement. In the first stage, PAR progressively generates speech tokens along the time dimension, with each step predicting all positions in parallel but only retaining the left-most span. In the second stage, low-confidence tokens are iteratively refined in parallel, leveraging the global contextual information. Experiments demonstrate that PALLE, trained on LibriTTS, outperforms state-of-the-art systems trained on large-scale data, including F5-TTS, E2-TTS, and MaskGCT, on the LibriSpeech test-clean set in terms of speech quality, speaker similarity, and intelligibility, while achieving up to ten times faster inference speed. Audio samples are available at https://anonymous-palle.github.io.