 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext Tokens Denoising for Speech Synthesis
Jul 30, 2025While diffusion and autoregressive (AR) models have significantly advanced generative modeling, they each present distinct limitations. AR models, which rely on causal attention, cannot exploit future context and suffer from slow generation speeds. Conversely, diffusion models struggle with key-value (KV) caching. To overcome these challenges, we introduce Dragon-FM, a novel text-to-speech (TTS) design that unifies AR and flow-matching. This model processes 48 kHz audio codec tokens in chunks at a compact 12.5 tokens per second rate. This design enables AR modeling across chunks, ensuring global coherence, while parallel flow-matching within chunks facilitates fast iterative denoising. Consequently, the proposed model can utilize KV-cache across chunks and incorporate future context within each chunk. Furthermore, it bridges continuous and discrete feature modeling, demonstrating that continuous AR flow-matching can predict discrete tokens with finite scalar quantizers. This efficient codec and fast chunk-autoregressive architecture also makes the proposed model particularly effective for generating extended content. Experiment for demos of our work} on podcast datasets demonstrate its capability to efficiently generate high-quality zero-shot podcasts.
FoundationTTS: Text-to-Speech for ASR Customization with Generative Language Model
Mar 08, 2023Neural text-to-speech (TTS) generally consists of cascaded architecture with separately optimized acoustic model and vocoder, or end-to-end architecture with continuous mel-spectrograms or self-extracted speech frames as the intermediate representations to bridge acoustic model and vocoder, which suffers from two limitations: 1) the continuous acoustic frames are hard to predict with phoneme only, and acoustic information like duration or pitch is also needed to solve the one-to-many problem, which is not easy to scale on large scale and noise datasets; 2) to achieve diverse speech output based on continuous speech features, complex VAE or flow-based models are usually required. In this paper, we propose FoundationTTS, a new speech synthesis system with a neural audio codec for discrete speech token extraction and waveform reconstruction and a large language model for discrete token generation from linguistic (phoneme) tokens. Specifically, 1) we propose a hierarchical codec network based on vector-quantized auto-encoders with adversarial training (VQ-GAN), which first extracts continuous frame-level speech representations with fine-grained codec, and extracts a discrete token from each continuous speech frame with coarse-grained codec; 2) we jointly optimize speech token, linguistic tokens, speaker token together with a large language model and predict the discrete speech tokens autoregressively. Experiments show that FoundationTTS achieves a MOS gain of +0.14 compared to the baseline system. In ASR customization tasks, our method achieves 7.09\% and 10.35\% WERR respectively over two strong customized ASR baselines.
DelightfulTTS 2: End-to-End Speech Synthesis with Adversarial Vector-Quantized Auto-Encoders
Jul 11, 2022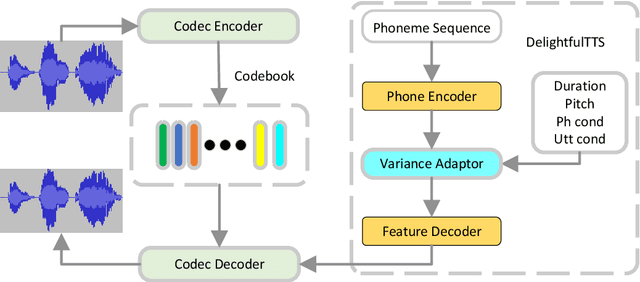
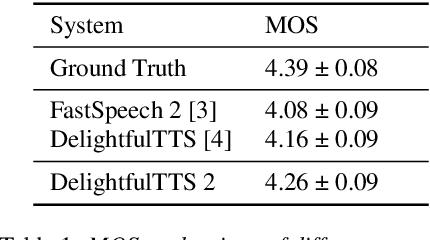
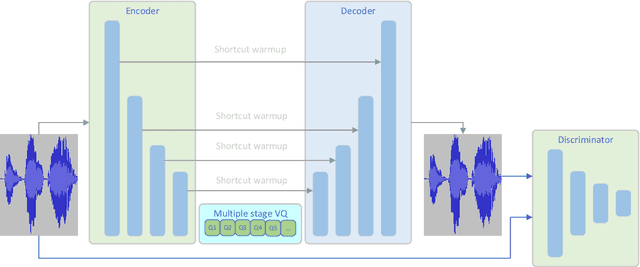
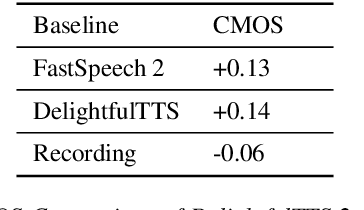
Current text to speech (TTS) systems usually leverage a cascaded acoustic model and vocoder pipeline with mel-spectrograms as the intermediate representations, which suffer from two limitations: 1) the acoustic model and vocoder are separately trained instead of jointly optimized, which incurs cascaded errors; 2) the intermediate speech representations (e.g., mel-spectrogram) are pre-designed and lose phase information, which are sub-optimal. To solve these problems, in this paper, we develop DelightfulTTS 2, a new end-to-end speech synthesis system with automatically learned speech representations and jointly optimized acoustic model and vocoder. Specifically, 1) we propose a new codec network based on vector-quantized auto-encoders with adversarial training (VQ-GAN) to extract intermediate frame-level speech representations (instead of traditional representations like mel-spectrograms) and reconstruct speech waveform; 2) we jointly optimize the acoustic model (based on DelightfulTTS) and the vocoder (the decoder of VQ-GAN), with an auxiliary loss on the acoustic model to predict intermediate speech representations. Experiments show that DelightfulTTS 2 achieves a CMOS gain +0.14 over DelightfulTTS, and more method analyses further verify the effectiveness of the developed system.