 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
SOL-ExecBench: Speed-of-Light Benchmarking for Real-World GPU Kernels Against Hardware Limits
Mar 19, 2026As agentic AI systems become increasingly capable of generating and optimizing GPU kernels, progress is constrained by benchmarks that reward speedup over software baselines rather than proximity to hardware-efficient execution. We present SOL-ExecBench, a benchmark of 235 CUDA kernel optimization problems extracted from 124 production and emerging AI models spanning language, diffusion, vision, audio, video, and hybrid architectures, targeting NVIDIA Blackwell GPUs. The benchmark covers forward and backward workloads across BF16, FP8, and NVFP4, including kernels whose best performance is expected to rely on Blackwell-specific capabilities. Unlike prior benchmarks that evaluate kernels primarily relative to software implementations, SOL-ExecBench measures performance against analytically derived Speed-of-Light (SOL) bounds computed by SOLAR, our pipeline for deriving hardware-grounded SOL bounds, yielding a fixed target for hardware-efficient optimization. We report a SOL Score that quantifies how much of the gap between a release-defined scoring baseline and the hardware SOL bound a candidate kernel closes. To support robust evaluation of agentic optimizers, we additionally provide a sandboxed harness with GPU clock locking, L2 cache clearing, isolated subprocess execution, and static analysis based checks against common reward-hacking strategies. SOL-ExecBench reframes GPU kernel benchmarking from beating a mutable software baseline to closing the remaining gap to hardware Speed-of-Light.
KernelBlaster: Continual Cross-Task CUDA Optimization via Memory-Augmented In-Context Reinforcement Learning
Feb 15, 2026Optimizing CUDA code across multiple generations of GPU architectures is challenging, as achieving peak performance requires an extensive exploration of an increasingly complex, hardware-specific optimization space. Traditional compilers are constrained by fixed heuristics, whereas finetuning Large Language Models (LLMs) can be expensive. However, agentic workflows for CUDA code optimization have limited ability to aggregate knowledge from prior exploration, leading to biased sampling and suboptimal solutions. We propose KernelBlaster, a Memory-Augmented In-context Reinforcement Learning (MAIC-RL) framework designed to improve CUDA optimization search capabilities of LLM-based GPU coding agents. KernelBlaster enables agents to learn from experience and make systematically informed decisions on future tasks by accumulating knowledge into a retrievable Persistent CUDA Knowledge Base. We propose a novel profile-guided, textual-gradient-based agentic flow for CUDA generation and optimization to achieve high performance across generations of GPU architectures. KernelBlaster guides LLM agents to systematically explore high-potential optimization strategies beyond naive rewrites. Compared to the PyTorch baseline, our method achieves geometric mean speedups of 1.43x, 2.50x, and 1.50x on KernelBench Levels 1, 2, and 3, respectively. We release KernelBlaster as an open-source agentic framework, accompanied by a test harness, verification components, and a reproducible evaluation pipeline.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Code-Switching Text Generation and Injection in Mandarin-English ASR
Mar 20, 2023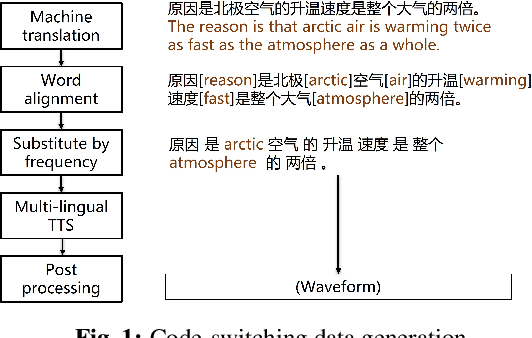
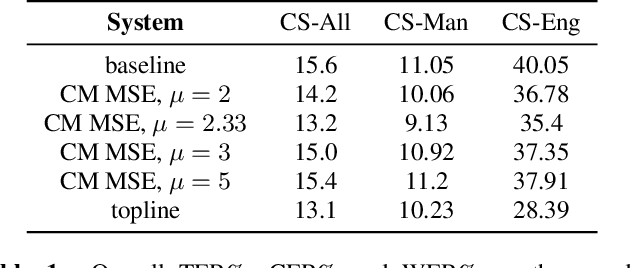
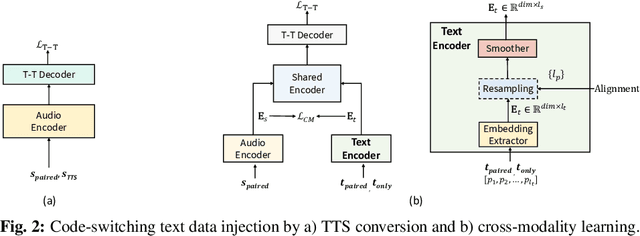

Code-switching speech refers to a means of expression by mixing two or more languages within a single utterance. Automatic Speech Recognition (ASR) with End-to-End (E2E) modeling for such speech can be a challenging task due to the lack of data. In this study, we investigate text generation and injection for improving the performance of an industry commonly-used streaming model, Transformer-Transducer (T-T), in Mandarin-English code-switching speech recognition. We first propose a strategy to generate code-switching text data and then investigate injecting generated text into T-T model explicitly by Text-To-Speech (TTS) conversion or implicitly by tying speech and text latent spaces. Experimental results on the T-T model trained with a dataset containing 1,800 hours of real Mandarin-English code-switched speech show that our approaches to inject generated code-switching text significantly boost the performance of T-T models, i.e., 16% relative Token-based Error Rate (TER) reduction averaged on three evaluation sets, and the approach of tying speech and text latent spaces is superior to that of TTS conversion on the evaluation set which contains more homogeneous data with the training set.
FoundationTTS: Text-to-Speech for ASR Customization with Generative Language Model
Mar 08, 2023Neural text-to-speech (TTS) generally consists of cascaded architecture with separately optimized acoustic model and vocoder, or end-to-end architecture with continuous mel-spectrograms or self-extracted speech frames as the intermediate representations to bridge acoustic model and vocoder, which suffers from two limitations: 1) the continuous acoustic frames are hard to predict with phoneme only, and acoustic information like duration or pitch is also needed to solve the one-to-many problem, which is not easy to scale on large scale and noise datasets; 2) to achieve diverse speech output based on continuous speech features, complex VAE or flow-based models are usually required. In this paper, we propose FoundationTTS, a new speech synthesis system with a neural audio codec for discrete speech token extraction and waveform reconstruction and a large language model for discrete token generation from linguistic (phoneme) tokens. Specifically, 1) we propose a hierarchical codec network based on vector-quantized auto-encoders with adversarial training (VQ-GAN), which first extracts continuous frame-level speech representations with fine-grained codec, and extracts a discrete token from each continuous speech frame with coarse-grained codec; 2) we jointly optimize speech token, linguistic tokens, speaker token together with a large language model and predict the discrete speech tokens autoregressively. Experiments show that FoundationTTS achieves a MOS gain of +0.14 compared to the baseline system. In ASR customization tasks, our method achieves 7.09\% and 10.35\% WERR respectively over two strong customized ASR baselines.
Building High-accuracy Multilingual ASR with Gated Language Experts and Curriculum Training
Mar 01, 2023



We propose gated language experts to improve multilingual transformer transducer models without any language identification (LID) input from users during inference. We define gating mechanism and LID loss to let transformer encoders learn language-dependent information, construct the multilingual transformer block with gated transformer experts and shared transformer layers for compact models, and apply linear experts on joint network output to better regularize speech acoustic and token label joint information. Furthermore, a curriculum training scheme is proposed to let LID guide the gated language experts for better serving their corresponding languages. Evaluated on the English and Spanish bilingual task, our methods achieve average 12.5% and 7.3% relative word error reductions over the baseline bilingual model and monolingual models, respectively, obtaining similar results to the upper bound model trained and inferred with oracle LID. We further explore our method on trilingual, quadrilingual, and pentalingual models, and observe similar advantages as in the bilingual models, which demonstrates the easy extension to more languages.
SoftCorrect: Error Correction with Soft Detection for Automatic Speech Recognition
Dec 02, 2022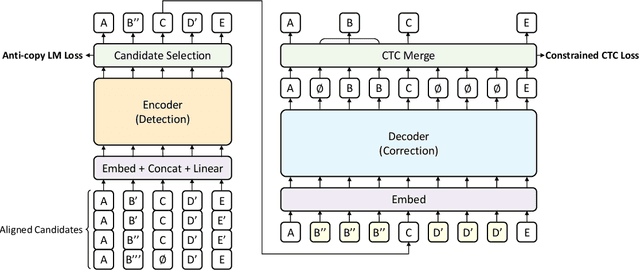



Error correction in automatic speech recognition (ASR) aims to correct those incorrect words in sentences generated by ASR models. Since recent ASR models usually have low word error rate (WER), to avoid affecting originally correct tokens, error correction models should only modify incorrect words, and therefore detecting incorrect words is important for error correction. Previous works on error correction either implicitly detect error words through target-source attention or CTC (connectionist temporal classification) loss, or explicitly locate specific deletion/substitution/insertion errors. However, implicit error detection does not provide clear signal about which tokens are incorrect and explicit error detection suffers from low detection accuracy. In this paper, we propose SoftCorrect with a soft error detection mechanism to avoid the limitations of both explicit and implicit error detection. Specifically, we first detect whether a token is correct or not through a probability produced by a dedicatedly designed language model, and then design a constrained CTC loss that only duplicates the detected incorrect tokens to let the decoder focus on the correction of error tokens. Compared with implicit error detection with CTC loss, SoftCorrect provides explicit signal about which words are incorrect and thus does not need to duplicate every token but only incorrect tokens; compared with explicit error detection, SoftCorrect does not detect specific deletion/substitution/insertion errors but just leaves it to CTC loss. Experiments on AISHELL-1 and Aidatatang datasets show that SoftCorrect achieves 26.1% and 9.4% CER reduction respectively, outperforming previous works by a large margin, while still enjoying fast speed of parallel generation.
Mask the Correct Tokens: An Embarrassingly Simple Approach for Error Correction
Nov 23, 2022Text error correction aims to correct the errors in text sequences such as those typed by humans or generated by speech recognition models. Previous error correction methods usually take the source (incorrect) sentence as encoder input and generate the target (correct) sentence through the decoder. Since the error rate of the incorrect sentence is usually low (e.g., 10\%), the correction model can only learn to correct on limited error tokens but trivially copy on most tokens (correct tokens), which harms the effective training of error correction. In this paper, we argue that the correct tokens should be better utilized to facilitate effective training and then propose a simple yet effective masking strategy to achieve this goal. Specifically, we randomly mask out a part of the correct tokens in the source sentence and let the model learn to not only correct the original error tokens but also predict the masked tokens based on their context information. Our method enjoys several advantages: 1) it alleviates trivial copy; 2) it leverages effective training signals from correct tokens; 3) it is a plug-and-play module and can be applied to different models and tasks. Experiments on spelling error correction and speech recognition error correction on Mandarin datasets and grammar error correction on English datasets with both autoregressive and non-autoregressive generation models show that our method improves the correction accuracy consistently.