 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-Switching Text Generation and Injection in Mandarin-English ASR
Mar 20, 2023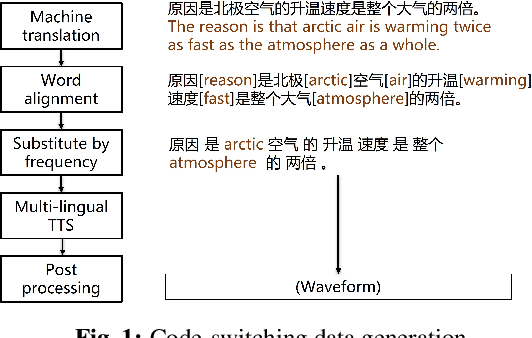
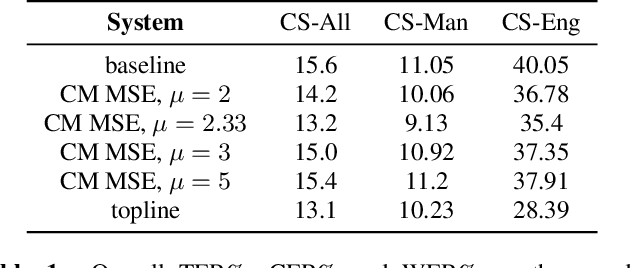
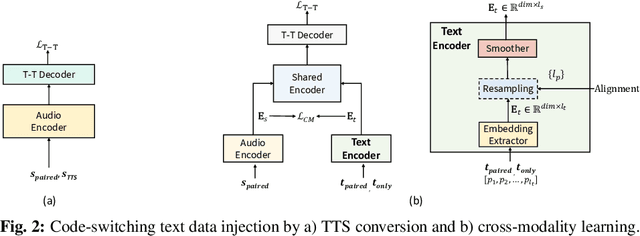

Code-switching speech refers to a means of expression by mixing two or more languages within a single utterance. Automatic Speech Recognition (ASR) with End-to-End (E2E) modeling for such speech can be a challenging task due to the lack of data. In this study, we investigate text generation and injection for improving the performance of an industry commonly-used streaming model, Transformer-Transducer (T-T), in Mandarin-English code-switching speech recognition. We first propose a strategy to generate code-switching text data and then investigate injecting generated text into T-T model explicitly by Text-To-Speech (TTS) conversion or implicitly by tying speech and text latent spaces. Experimental results on the T-T model trained with a dataset containing 1,800 hours of real Mandarin-English code-switched speech show that our approaches to inject generated code-switching text significantly boost the performance of T-T models, i.e., 16% relative Token-based Error Rate (TER) reduction averaged on three evaluation sets, and the approach of tying speech and text latent spaces is superior to that of TTS conversion on the evaluation set which contains more homogeneous data with the training set.