 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDTalk: Structured Facial Priors and Dual-Branch Motion Fields for Generalizable Gaussian Talking Head Synthesis
May 11, 2026High-quality, real-time talking head synthesis remains a fundamental challenge in computer vision. Existing reconstruction- and rendering-based methods typically rely on identity-specific models, limiting cross-identity generalization. To address this issue, we propose SDTalk, a one-shot 3D Gaussian Splatting (3DGS)-based framework that generalizes to unseen identities without personalized training or fine-tuning. Our framework comprises two modules with a two-stage training strategy. In the first stage, we incorporate structured facial priors into the reconstruction module and separately predict 3DGS parameters for visible and occluded regions, enabling complete head reconstruction from a single image. In the second stage, we introduce a dual-branch motion field to model coarse and fine facial dynamics, improving detail fidelity and lip synchronization. Experiments demonstrate that SDTalk surpasses existing methods in both visual quality and inference efficiency.
Exploring Robust Face-Voice Matching in Multilingual Environments
Jul 29, 2024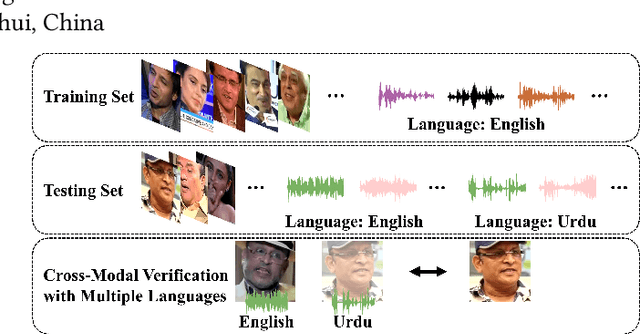



This paper presents Team Xaiofei's innovative approach to exploring Face-Voice Association in Multilingual Environments (FAME) at ACM Multimedia 2024. We focus on the impact of different languages in face-voice matching by building upon Fusion and Orthogonal Projection (FOP), introducing four key components: a dual-branch structure, dynamic sample pair weighting, robust data augmentation, and score polarization strategy. Our dual-branch structure serves as an auxiliary mechanism to better integrate and provide more comprehensive information. We also introduce a dynamic weighting mechanism for various sample pairs to optimize learning. Data augmentation techniques are employed to enhance the model's generalization across diverse conditions. Additionally, score polarization strategy based on age and gender matching confidence clarifies and accentuates the final results. Our methods demonstrate significant effectiveness, achieving an equal error rate (EER) of 20.07 on the V2-EH dataset and 21.76 on the V1-EU dataset.
Revisiting Deep Local Descriptor for Improved Few-Shot Classification
Mar 30, 2021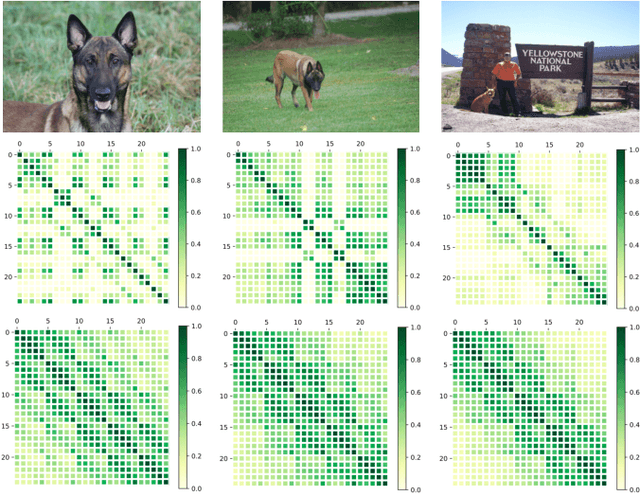
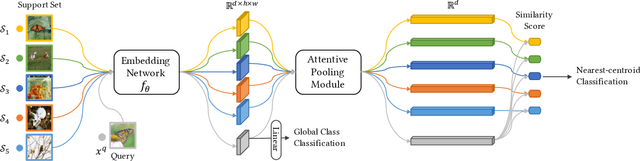
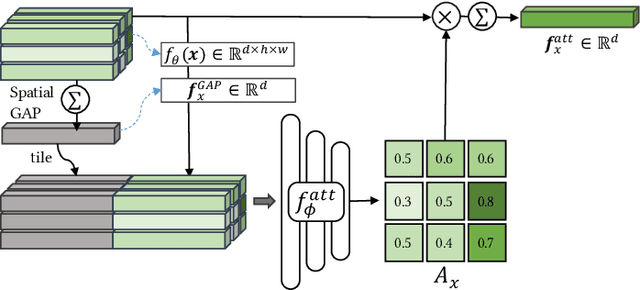
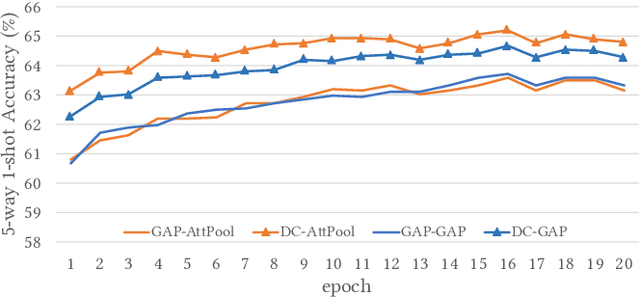
Few-shot classification studies the problem of quickly adapting a deep learner to understanding novel classes based on few support images. In this context, recent research efforts have been aimed at designing more and more complex classifiers that measure similarities between query and support images, but left the importance of feature embeddings seldom explored. We show that the reliance on sophisticated classifier is not necessary and a simple classifier applied directly to improved feature embeddings can outperform state-of-the-art methods. To this end, we present a new method named \textbf{DCAP} in which we investigate how one can improve the quality of embeddings by leveraging \textbf{D}ense \textbf{C}lassification and \textbf{A}ttentive \textbf{P}ooling. Specifically, we propose to pre-train a learner on base classes with abundant samples to solve dense classification problem first and then fine-tune the learner on a bunch of randomly sampled few-shot tasks to adapt it to few-shot scenerio or the test time scenerio. We suggest to pool feature maps by applying attentive pooling instead of the widely used global average pooling (GAP) to prepare embeddings for few-shot classification during meta-finetuning. Attentive pooling learns to reweight local descriptors, explaining what the learner is looking for as evidence for decision making. Experiments on two benchmark datasets show the proposed method to be superior in multiple few-shot settings while being simpler and more explainable. Code is available at: \url{https://github.com/Ukeyboard/dcap/}.
Memory-Augmented Relation Network for Few-Shot Learning
May 13, 2020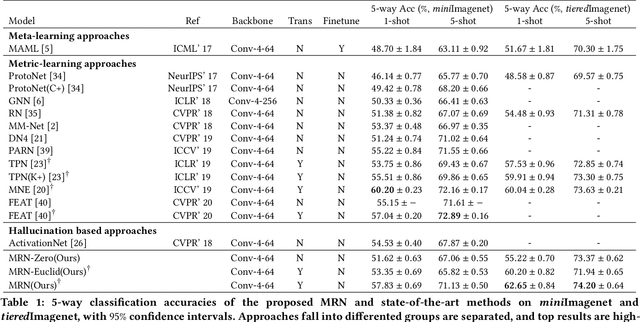
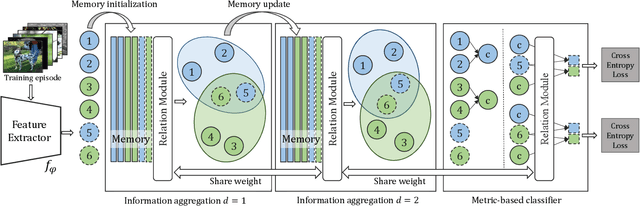
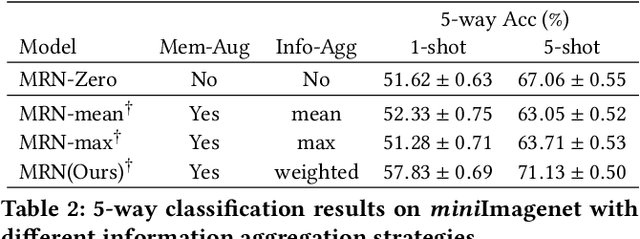

Metric-based few-shot learning methods concentrate on learning transferable feature embedding that generalizes well from seen categories to unseen categories under the supervision of limited number of labelled instances. However, most of them treat each individual instance in the working context separately without considering its relationships with the others. In this work, we investigate a new metric-learning method, Memory-Augmented Relation Network (MRN), to explicitly exploit these relationships. In particular, for an instance, we choose the samples that are visually similar from the working context, and perform weighted information propagation to attentively aggregate helpful information from the chosen ones to enhance its representation. In MRN, we also formulate the distance metric as a learnable relation module which learns to compare for similarity measurement, and augment the working context with memory slots, both contributing to its generality. We empirically demonstrate that MRN yields significant improvement over its ancestor and achieves competitive or even better performance when compared with other few-shot learning approaches on the two major benchmark datasets, i.e. miniImagenet and tieredImagenet.
Deep Recurrent Neural Network for Protein Function Prediction from Sequence
Jan 28, 2017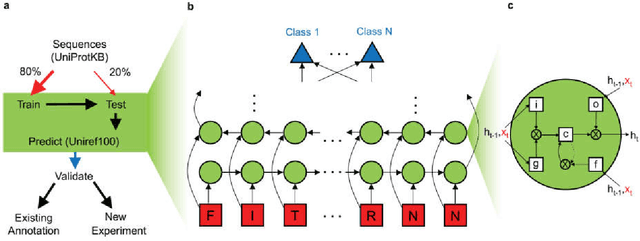
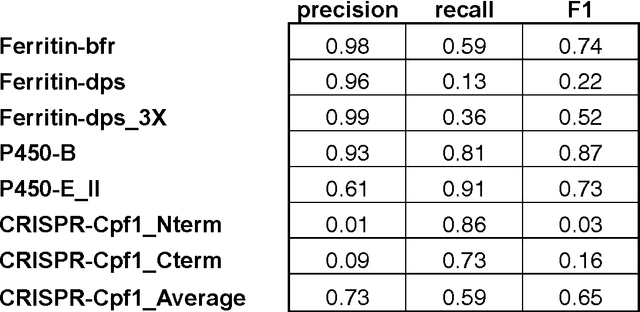
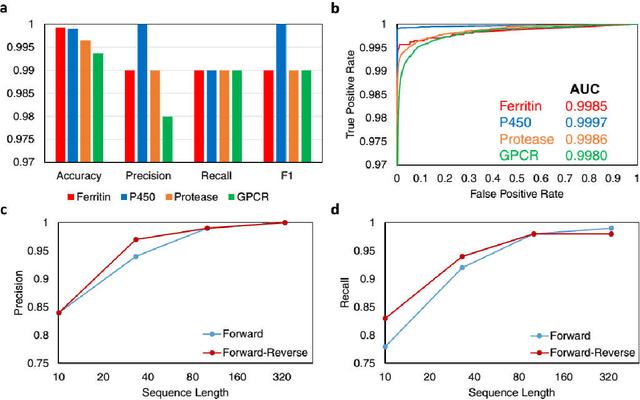
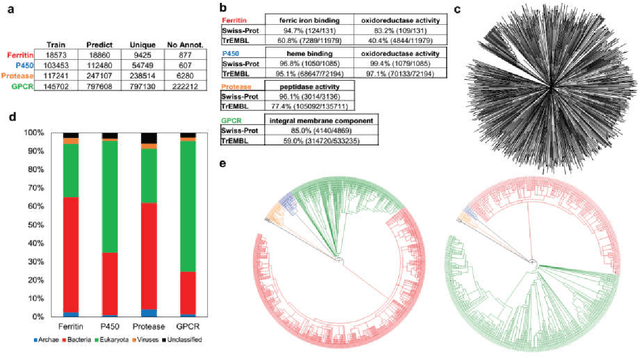
As high-throughput biological sequencing becomes faster and cheaper, the need to extract useful information from sequencing becomes ever more paramount, often limited by low-throughput experimental characterizations. For proteins, accurate prediction of their functions directly from their primary amino-acid sequences has been a long standing challenge. Here, machine learning using artificial recurrent neural networks (RNN) was applied towards classification of protein function directly from primary sequence without sequence alignment, heuristic scoring or feature engineering. The RNN models containing long-short-term-memory (LSTM) units trained on public, annotated datasets from UniProt achieved high performance for in-class prediction of four important protein functions tested, particularly compared to other machine learning algorithms using sequence-derived protein features. RNN models were used also for out-of-class predictions of phylogenetically distinct protein families with similar functions, including proteins of the CRISPR-associated nuclease, ferritin-like iron storage and cytochrome P450 families. Applying the trained RNN models on the partially unannotated UniRef100 database predicted not only candidates validated by existing annotations but also currently unannotated sequences. Some RNN predictions for the ferritin-like iron sequestering function were experimentally validated, even though their sequences differ significantly from known, characterized proteins and from each other and cannot be easily predicted using popular bioinformatics methods. As sequencing and experimental characterization data increases rapidly, the machine-learning approach based on RNN could be useful for discovery and prediction of homologues for a wide range of protein functions.