Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximizing Audio Event Detection Model Performance on Small Datasets Through Knowledge Transfer, Data Augmentation, And Pretraining: An Ablation Study
Paper and Code
Feb 07, 2022
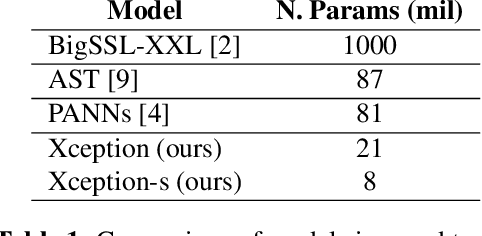
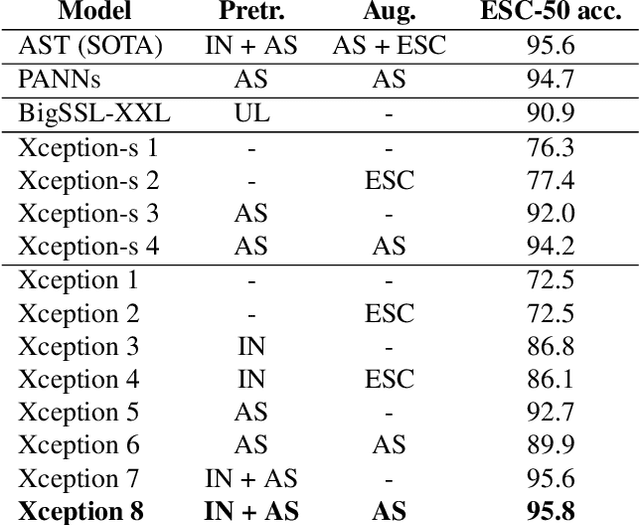

An Xception model reaches state-of-the-art (SOTA) accuracy on the ESC-50 dataset for audio event detection through knowledge transfer from ImageNet weights, pretraining on AudioSet, and an on-the-fly data augmentation pipeline. This paper presents an ablation study that analyzes which components contribute to the boost in performance and training time. A smaller Xception model is also presented which nears SOTA performance with almost a third of the parameters.
View paper on