 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavFT: Acoustic model finetuning with labelled and unlabelled data
Apr 01, 2022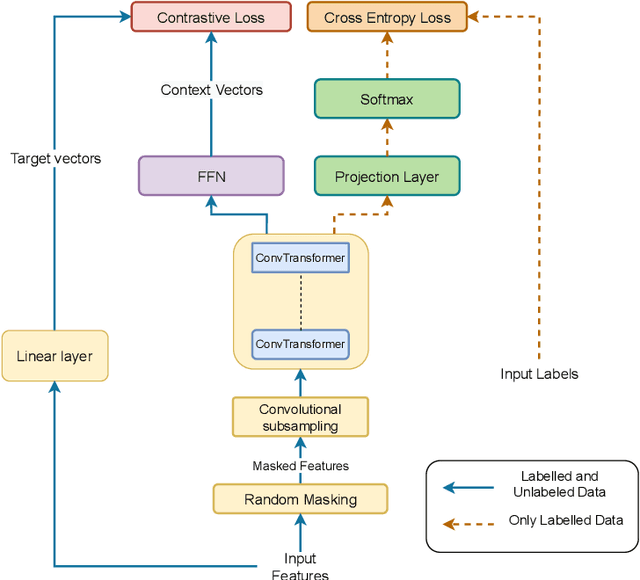

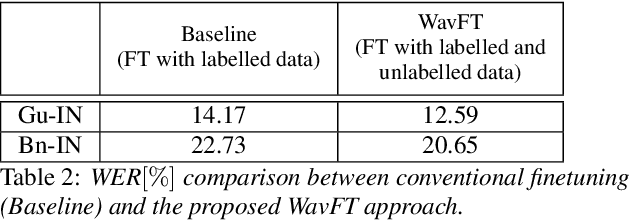

Unsupervised and self-supervised learning methods have leveraged unlabelled data to improve the pretrained models. However, these methods need significantly large amount of unlabelled data and the computational cost of training models with such large amount of data can be prohibitively high. We address this issue by using unlabelled data during finetuning, instead of pretraining. We propose acoustic model finetuning (FT) using labelled and unlabelled data. The model is jointly trained to learn representations to classify senones, as well as learn contextual acoustic representations. Our training objective is a combination of cross entropy loss, suitable for classification task, and contrastive loss, suitable to learn acoustic representations. The proposed approach outperforms conventional finetuning with 11.2% and 9.19% word error rate relative (WERR) reduction on Gujarati and Bengali languages respectively.
Transfer Learning Approaches for Streaming End-to-End Speech Recognition System
Aug 17, 2020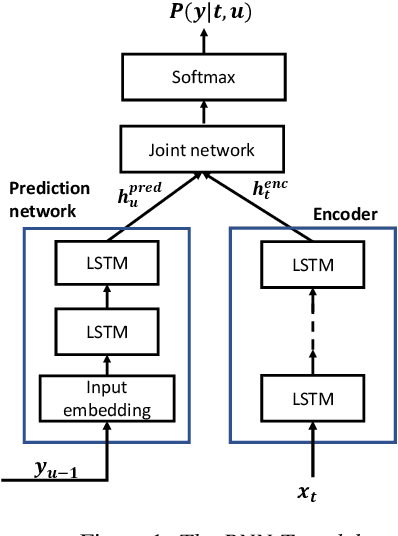
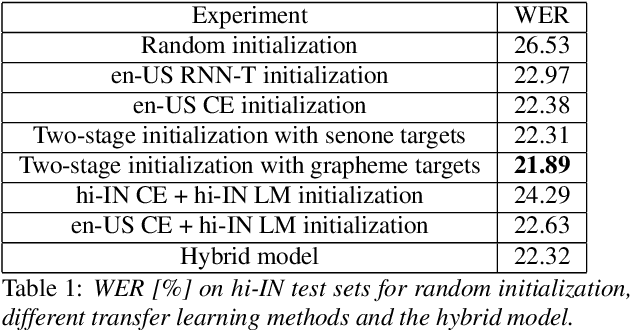
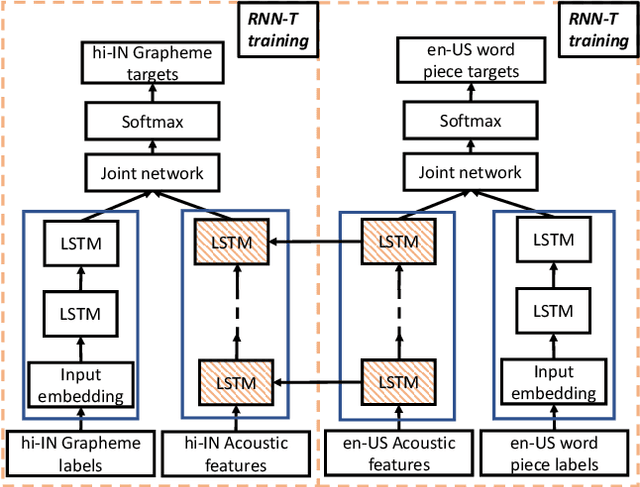
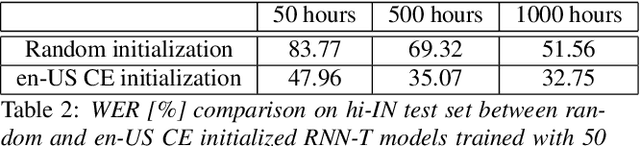
Transfer learning (TL) is widely used in conventional hybrid automatic speech recognition (ASR) system, to transfer the knowledge from source to target language. TL can be applied to end-to-end (E2E) ASR system such as recurrent neural network transducer (RNN-T) models, by initializing the encoder and/or prediction network of the target language with the pre-trained models from source language. In the hybrid ASR system, transfer learning is typically done by initializing the target language acoustic model (AM) with source language AM. Several transfer learning strategies exist in the case of the RNN-T framework, depending upon the choice of the initialization model for encoder and prediction networks. This paper presents a comparative study of four different TL methods for RNN-T framework. We show 17% relative word error rate reduction with different TL methods over randomly initialized RNN-T model. We also study the impact of TL with varying amount of training data ranging from 50 hours to 1000 hours and show the efficacy of TL for languages with small amount of training data.