 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework for Speech Separation
Paper and Code
Dec 17, 2019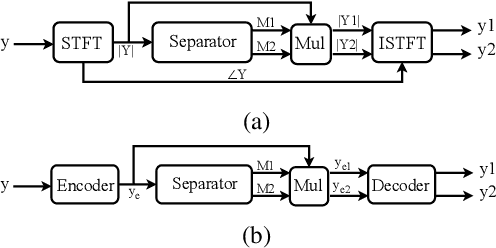
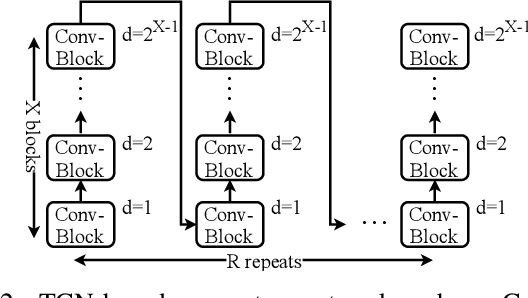
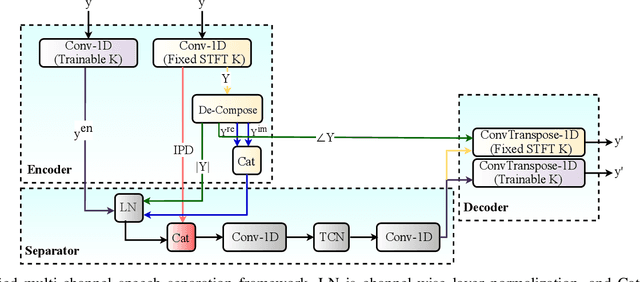
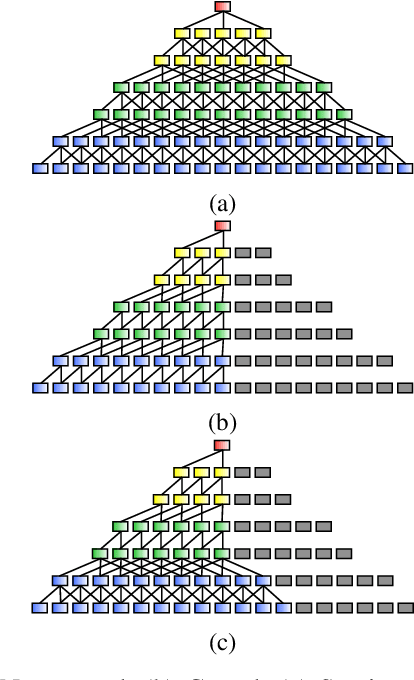
Speech separation refers to extracting each individual speech source in a given mixed signal. Recent advancements in speech separation and ongoing research in this area, have made these approaches as promising techniques for pre-processing of naturalistic audio streams. After incorporating deep learning techniques into speech separation, performance on these systems is improving faster. The initial solutions introduced for deep learning based speech separation analyzed the speech signals into time-frequency domain with STFT; and then encoded mixed signals were fed into a deep neural network based separator. Most recently, new methods are introduced to separate waveform of the mixed signal directly without analyzing them using STFT. Here, we introduce a unified framework to include both spectrogram and waveform separations into a single structure, while being only different in the kernel function used to encode and decode the data; where, both can achieve competitive performance. This new framework provides flexibility; in addition, depending on the characteristics of the data, or limitations of the memory and latency can set the hyper-parameters to flow in a pipeline of the framework which fits the task properly. We extend single-channel speech separation into multi-channel framework with end-to-end training of the network while optimizing the speech separation criterion (i.e., Si-SNR) directly. We emphasize on how tied kernel functions for calculating spatial features, encoder, and decoder in multi-channel framework can be effective. We simulate spatialized reverberate data for both WSJ0 and LibriSpeech corpora here, and while these two sets of data are different in the matter of size and duration, the effect of capturing shorter and longer dependencies of previous/+future samples are studied in detail. We report SDR, Si-SNR and PESQ to evaluate the performance of developed solutions.