 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comprehensive study of speech separation: spectrogram vs waveform separation
Paper and Code
May 17, 2019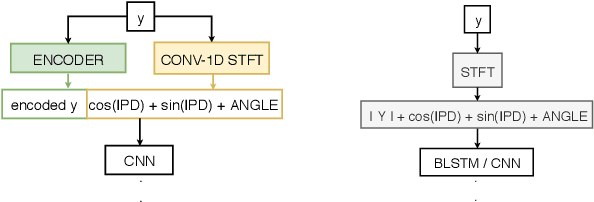

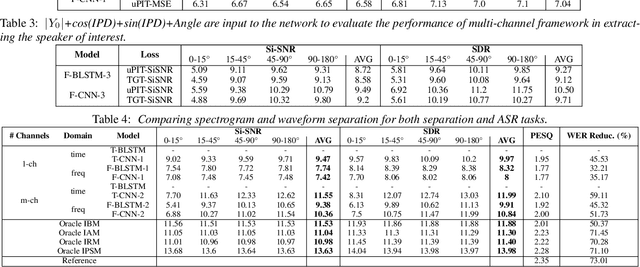
Speech separation has been studied widely for single-channel close-talk recordings over the past few years; developed solutions are mostly in frequency-domain. Recently, a raw audio waveform separation network (TasNet) introduced for single-channel data, with achieving high Si-SNR (scale-invariant source-to-noise ratio) and SDR (source-to-distortion ratio) comparing against the state-of-the-art solution in frequency-domain. In this study, we incorporate effective components of TasNet into a frequency-domain separation method. We compare both for alternative scenarios. We introduce a solution for directly optimizing the separation criterion in frequency-domain networks. In addition to speech separation objective and subjective measurements, we evaluate the separation performance on a speech recognition task as well. We study the speech separation problem for far-filed data (more similar to naturalistic audio streams) and develop multi-channel solutions for both frequency and time-domain separators with utilizing spectral, spatial and speaker location information. For our experiments, we simulated multi-channel spatialized reverberate WSJ0-2mix dataset. Our experimental results show that spectrogram separation can achieve competitive performance with better network design. With multi-channel framework as well, we can obtain relatively up to +35.5% and +46% improvement in terms of WER and SDR, respectively.