 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepTalk: Vocal Style Encoding for Speaker Recognition and Speech Synthesis
Paper and Code
Dec 09, 2020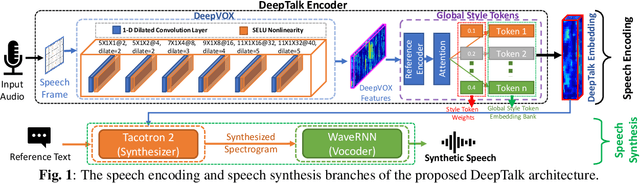
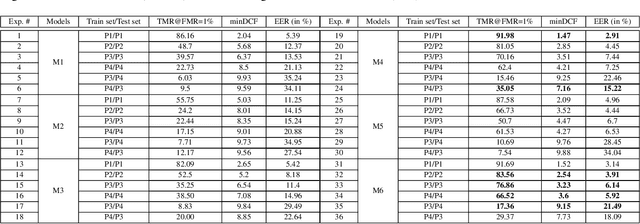
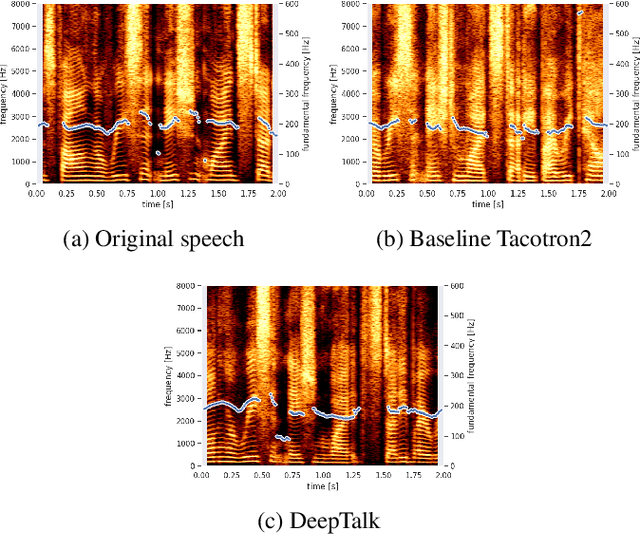
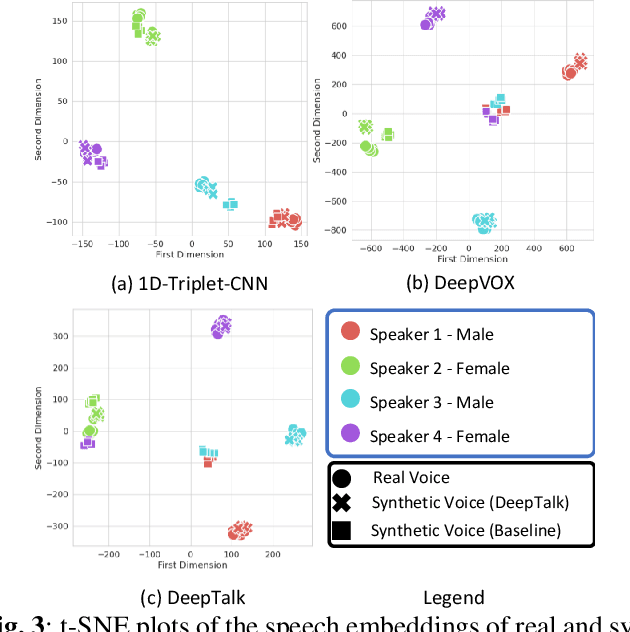
Automatic speaker recognition algorithms typically use physiological speech characteristics encoded in the short term spectral features for characterizing speech audio. Such algorithms do not capitalize on the complementary and discriminative speaker-dependent characteristics present in the behavioral speech features. In this work, we propose a prosody encoding network called DeepTalk for extracting vocal style features directly from raw audio data. The DeepTalk method outperforms several state-of-the-art physiological speech characteristics-based speaker recognition systems across multiple challenging datasets. The speaker recognition performance is further improved by combining DeepTalk with a state-of-the-art physiological speech feature-based speaker recognition system. We also integrate the DeepTalk method into a current state-of-the-art speech synthesizer to generate synthetic speech. A detailed analysis of the synthetic speech shows that the DeepTalk captures F0 contours essential for vocal style modeling. Furthermore, DeepTalk-based synthetic speech is shown to be almost indistinguishable from real speech in the context of speaker recognition.