 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepVOX: Discovering Features from Raw Audio for Speaker Recognition in Degraded Audio Signals
Paper and Code
Aug 26, 2020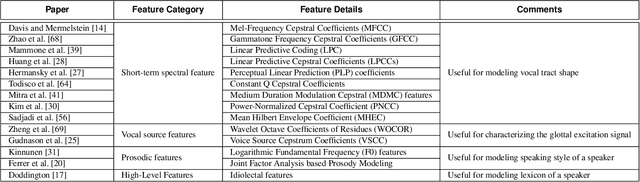
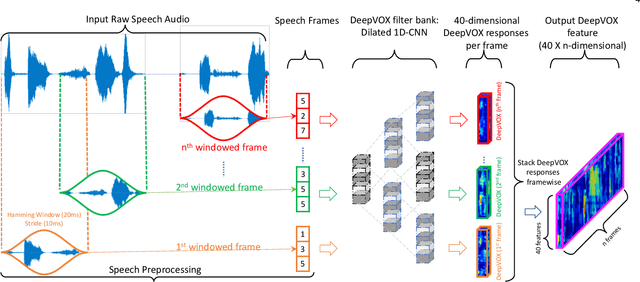
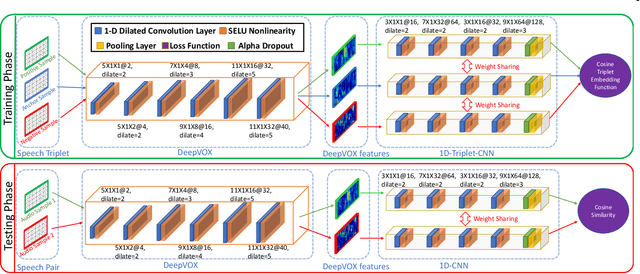

Automatic speaker recognition algorithms typically use pre-defined filterbanks, such as Mel-Frequency and Gammatone filterbanks, for characterizing speech audio. The design of these filterbanks is based on domain-knowledge and limited empirical observations. The resultant features, therefore, may not generalize well to different types of audio degradation. In this work, we propose a deep learning-based technique to induce the filterbank design from vast amounts of speech audio. The purpose of such a filterbank is to extract features robust to degradations in the input audio. To this effect, a 1D convolutional neural network is designed to learn a time-domain filterbank called DeepVOX directly from raw speech audio. Secondly, an adaptive triplet mining technique is developed to efficiently mine the data samples best suited to train the filterbank. Thirdly, a detailed ablation study of the DeepVOX filterbanks reveals the presence of both vocal source and vocal tract characteristics in the extracted features. Experimental results on VOXCeleb2, NIST SRE 2008 and 2010, and Fisher speech datasets demonstrate the efficacy of the DeepVOX features across a variety of audio degradations, multi-lingual speech data, and varying-duration speech audio. The DeepVOX features also improve the performance of existing speaker recognition algorithms, such as the xVector-PLDA and the iVector-PLDA.