 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJudge Reliability Harness: Stress Testing the Reliability of LLM Judges
Mar 05, 2026We present the Judge Reliability Harness, an open source library for constructing validation suites that test the reliability of LLM judges. As LLM based scoring is widely deployed in AI benchmarks, more tooling is needed to efficiently assess the reliability of these methods. Given a benchmark dataset and an LLM judge configuration, the harness generates reliability tests that evaluate both binary judgment accuracy and ordinal grading performance for free-response and agentic task formats. We evaluate four state-of-the-art judges across four benchmarks spanning safety, persuasion, misuse, and agentic behavior, and find meaningful variation in performance across models and perturbation types, highlighting opportunities to improve the robustness of LLM judges. No judge that we evaluated is uniformly reliable across benchmarks using our harness. For example, our preliminary experiments on judges revealed consistency issues as measured by accuracy in judging another LLM's ability to complete a task due to simple text formatting changes, paraphrasing, changes in verbosity, and flipping the ground truth label in LLM-produced responses. The code for this tool is available at: https://github.com/RANDCorporation/judge-reliability-harness
A Linguistic Comparison between Human and ChatGPT-Generated Conversations
Feb 02, 2024This study explores linguistic differences between human and LLM-generated dialogues, using 19.5K dialogues generated by ChatGPT-3.5 as a companion to the EmpathicDialogues dataset. The research employs Linguistic Inquiry and Word Count (LIWC) analysis, comparing ChatGPT-generated conversations with human conversations across 118 linguistic categories. Results show greater variability and authenticity in human dialogues, but ChatGPT excels in categories such as social processes, analytical style, cognition, attentional focus, and positive emotional tone, reinforcing recent findings of LLMs being "more human than human." However, no significant difference was found in positive or negative affect between ChatGPT and human dialogues. Classifier analysis of dialogue embeddings indicates implicit coding of the valence of affect despite no explicit mention of affect in the conversations. The research also contributes a novel, companion ChatGPT-generated dataset of conversations between two independent chatbots, which were designed to replicate a corpus of human conversations available for open access and used widely in AI research on language modeling. Our findings increase understanding of ChatGPT's linguistic capabilities and inform ongoing efforts to distinguish between human and LLM-generated text, which is critical in detecting AI-generated fakes, misinformation, and disinformation.
Voice Morphing: Two Identities in One Voice
Sep 05, 2023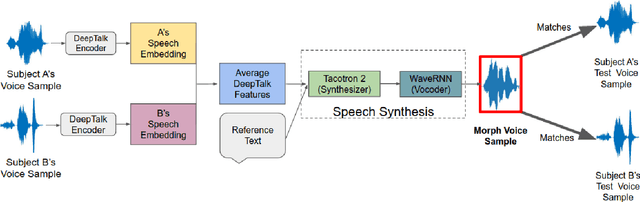
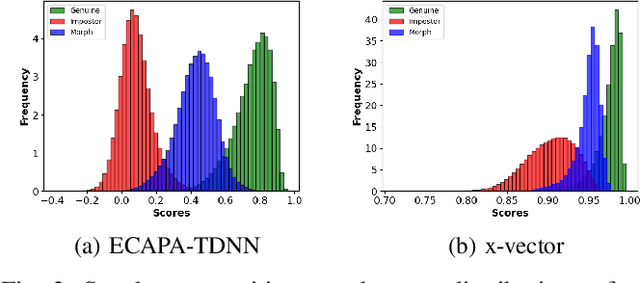
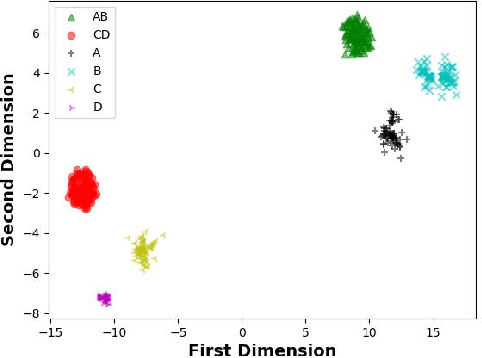
In a biometric system, each biometric sample or template is typically associated with a single identity. However, recent research has demonstrated the possibility of generating "morph" biometric samples that can successfully match more than a single identity. Morph attacks are now recognized as a potential security threat to biometric systems. However, most morph attacks have been studied on biometric modalities operating in the image domain, such as face, fingerprint, and iris. In this preliminary work, we introduce Voice Identity Morphing (VIM) - a voice-based morph attack that can synthesize speech samples that impersonate the voice characteristics of a pair of individuals. Our experiments evaluate the vulnerabilities of two popular speaker recognition systems, ECAPA-TDNN and x-vector, to VIM, with a success rate (MMPMR) of over 80% at a false match rate of 1% on the Librispeech dataset.
Vocal Style Factorization for Effective Speaker Recognition in Affective Scenarios
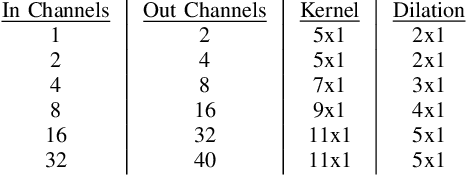
May 13, 2023The accuracy of automated speaker recognition is negatively impacted by change in emotions in a person's speech. In this paper, we hypothesize that speaker identity is composed of various vocal style factors that may be learned from unlabeled data and re-combined using a neural network architecture to generate holistic speaker identity representations for affective scenarios. In this regard we propose the E-Vector architecture, composed of a 1-D CNN for learning speaker identity features and a vocal style factorization technique for determining vocal styles. Experiments conducted on the MSP-Podcast dataset demonstrate that the proposed architecture improves state-of-the-art speaker recognition accuracy in the affective domain over baseline ECAPA-TDNN speaker recognition models. For instance, the true match rate at a false match rate of 1% improves from 27.6% to 46.2%.
Is Style All You Need? Dependencies Between Emotion and GST-based Speaker Recognition
Nov 15, 2022In this work, we study the hypothesis that speaker identity embeddings extracted from speech samples may be used for detection and classification of emotion. In particular, we show that emotions can be effectively identified by learning speaker identities by use of a 1-D Triplet Convolutional Neural Network (CNN) & Global Style Token (GST) scheme (e.g., DeepTalk Network) and reusing the trained speaker recognition model weights to generate features in the emotion classification domain. The automatic speaker recognition (ASR) network is trained with VoxCeleb1, VoxCeleb2, and Librispeech datasets with a triplet training loss function using speaker identity labels. Using an Support Vector Machine (SVM) classifier, we map speaker identity embeddings into discrete emotion categories from the CREMA-D, IEMOCAP, and MSP-Podcast datasets. On the task of speech emotion detection, we obtain 80.8% ACC with acted emotion samples from CREMA-D, 81.2% ACC with semi-natural emotion samples in IEMOCAP, and 66.9% ACC with natural emotion samples in MSP-Podcast. We also propose a novel two-stage hierarchical classifier (HC) approach which demonstrates +2% ACC improvement on CREMA-D emotion samples. Through this work, we seek to convey the importance of holistically modeling intra-user variation within audio samples