 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat happens to diffusion model likelihood when your model is conditional?
Sep 10, 2024



Diffusion Models (DMs) iteratively denoise random samples to produce high-quality data. The iterative sampling process is derived from Stochastic Differential Equations (SDEs), allowing a speed-quality trade-off chosen at inference. Another advantage of sampling with differential equations is exact likelihood computation. These likelihoods have been used to rank unconditional DMs and for out-of-domain classification. Despite the many existing and possible uses of DM likelihoods, the distinct properties captured are unknown, especially in conditional contexts such as Text-To-Image (TTI) or Text-To-Speech synthesis (TTS). Surprisingly, we find that TTS DM likelihoods are agnostic to the text input. TTI likelihood is more expressive but cannot discern confounding prompts. Our results show that applying DMs to conditional tasks reveals inconsistencies and strengthens claims that the properties of DM likelihood are unknown. This impact sheds light on the previously unknown nature of DM likelihoods. Although conditional DMs maximise likelihood, the likelihood in question is not as sensitive to the conditioning input as one expects. This investigation provides a new point-of-view on diffusion likelihoods.
Training Data Augmentation for Dysarthric Automatic Speech Recognition by Text-to-Dysarthric-Speech Synthesis
Jun 12, 2024
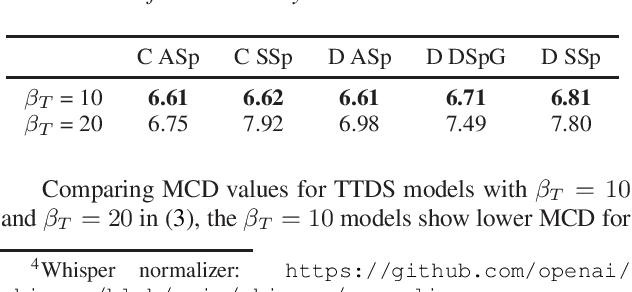
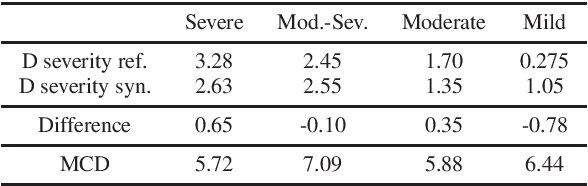
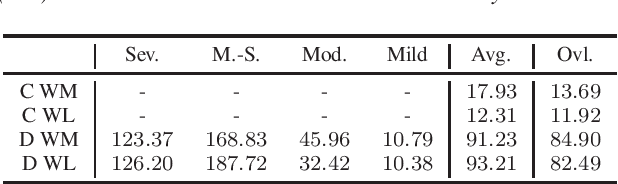
Automatic speech recognition (ASR) research has achieved impressive performance in recent years and has significant potential for enabling access for people with dysarthria (PwD) in augmentative and alternative communication (AAC) and home environment systems. However, progress in dysarthric ASR (DASR) has been limited by high variability in dysarthric speech and limited public availability of dysarthric training data. This paper demonstrates that data augmentation using text-to-dysarthic-speech (TTDS) synthesis for finetuning large ASR models is effective for DASR. Specifically, diffusion-based text-to-speech (TTS) models can produce speech samples similar to dysarthric speech that can be used as additional training data for fine-tuning ASR foundation models, in this case Whisper. Results show improved synthesis metrics and ASR performance for the proposed multi-speaker diffusion-based TTDS data augmentation for ASR fine-tuning compared to current DASR baselines.