 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Utterance: An Empirical Study of Very Long Context Speech Recognition
Feb 04, 2026Automatic speech recognition (ASR) models are normally trained to operate over single utterances, with a short duration of less than 30 seconds. This choice has been made in part due to computational constraints, but also reflects a common, but often inaccurate, modelling assumption that treats utterances as independent and identically distributed samples. When long-format audio recordings are available, to work with such systems, these recordings must first be segmented into short utterances and processed independently. In this work, we show that due to recent algorithmic and hardware advances, this is no longer necessary, and current attention-based approaches can be used to train ASR systems that operate on sequences of over an hour in length. Therefore, to gain a better understanding of the relationship between the training/evaluation sequence length and performance, we train ASR models on large-scale data using 10 different sequence lengths from 10 seconds up to 1 hour. The results show a benefit from using up to 21.8 minutes of context, with up to a 14.2% relative improvement from a short context baseline in our primary experiments. Through modifying various architectural components, we find that the method of encoding positional information and the model's width/depth are important factors when working with long sequences. Finally, a series of evaluations using synthetic data are constructed to help analyse the model's use of context. From these results, it is clear that both linguistic and acoustic aspects of the distant context are being used by the model.
Self-Train Before You Transcribe
Jun 17, 2024



When there is a mismatch between the training and test domains, current speech recognition systems show significant performance degradation. Self-training methods, such as noisy student teacher training, can help address this and enable the adaptation of models under such domain shifts. However, self-training typically requires a collection of unlabelled target domain data. For settings where this is not practical, we investigate the benefit of performing noisy student teacher training on recordings in the test set as a test-time adaptation approach. Similarly to the dynamic evaluation approach in language modelling, this enables the transfer of information across utterance boundaries and functions as a method of domain adaptation. A range of in-domain and out-of-domain datasets are used for experiments demonstrating large relative gains of up to 32.2%. Interestingly, our method showed larger gains than the typical self-training setup that utilises separate adaptation data.
How Much Context Does My Attention-Based ASR System Need?
Oct 24, 2023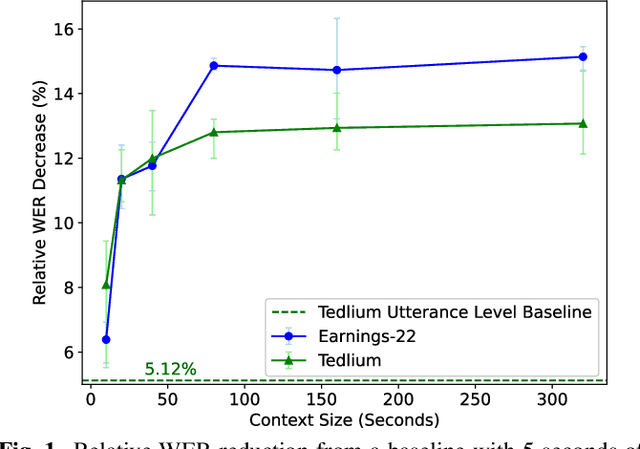

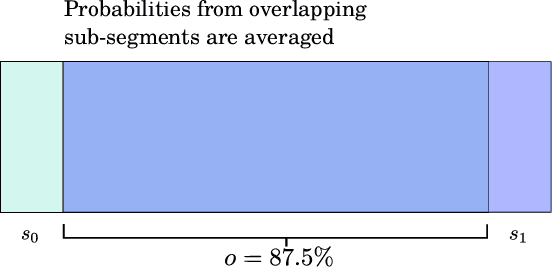

For the task of speech recognition, the use of more than 30 seconds of acoustic context during training is uncommon, and under-investigated in literature. In this work, we examine the effect of scaling the sequence length used to train/evaluate (dense-attention based) acoustic and language models on speech recognition performance. For these experiments a dataset of roughly 100,000 pseudo-labelled Spotify podcasts is used, with context lengths of 5 seconds to 1 hour being explored. Zero-shot evaluations on long-format datasets Earnings-22 and Tedlium demonstrate a benefit from training with around 80 seconds of acoustic context, showing up to a 14.9% relative improvement from a limited context baseline. Furthermore, we perform a system combination with long-context transformer language models via beam search for a fully long-context ASR system, with results that are competitive with the current state-of-the-art.
Leveraging Cross-Utterance Context For ASR Decoding
Jun 29, 2023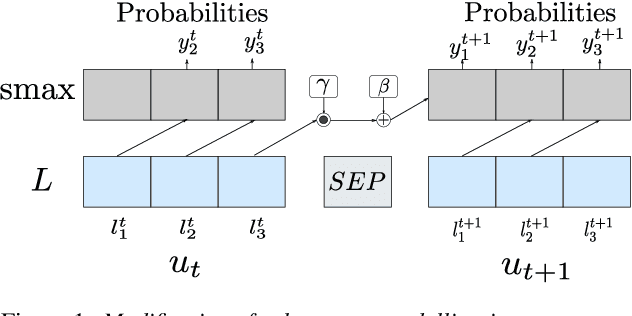
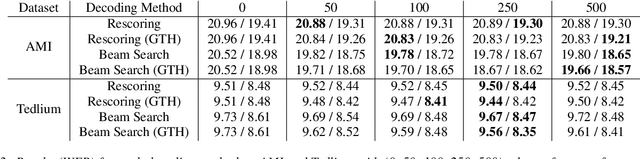
While external language models (LMs) are often incorporated into the decoding stage of automated speech recognition systems, these models usually operate with limited context. Cross utterance information has been shown to be beneficial during second pass re-scoring, however this limits the hypothesis space based on the local information available to the first pass LM. In this work, we investigate the incorporation of long-context transformer LMs for cross-utterance decoding of acoustic models via beam search, and compare against results from n-best rescoring. Results demonstrate that beam search allows for an improved use of cross-utterance context. When evaluating on the long-format dataset AMI, results show a 0.7\% and 0.3\% absolute reduction on dev and test sets compared to the single-utterance setting, with improvements when including up to 500 tokens of prior context. Evaluations are also provided for Tedlium-1 with less significant improvements of around 0.1\% absolute.
MTCue: Learning Zero-Shot Control of Extra-Textual Attributes by Leveraging Unstructured Context in Neural Machine Translation
May 25, 2023



Efficient utilisation of both intra- and extra-textual context remains one of the critical gaps between machine and human translation. Existing research has primarily focused on providing individual, well-defined types of context in translation, such as the surrounding text or discrete external variables like the speaker's gender. This work introduces MTCue, a novel neural machine translation (NMT) framework that interprets all context (including discrete variables) as text. MTCue learns an abstract representation of context, enabling transferability across different data settings and leveraging similar attributes in low-resource scenarios. With a focus on a dialogue domain with access to document and metadata context, we extensively evaluate MTCue in four language pairs in both translation directions. Our framework demonstrates significant improvements in translation quality over a parameter-matched non-contextual baseline, as measured by BLEU (+0.88) and Comet (+1.58). Moreover, MTCue significantly outperforms a "tagging" baseline at translating English text. Analysis reveals that the context encoder of MTCue learns a representation space that organises context based on specific attributes, such as formality, enabling effective zero-shot control. Pre-training on context embeddings also improves MTCue's few-shot performance compared to the "tagging" baseline. Finally, an ablation study conducted on model components and contextual variables further supports the robustness of MTCue for context-based NMT.