 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much Context Does My Attention-Based ASR System Need?
Paper and Code
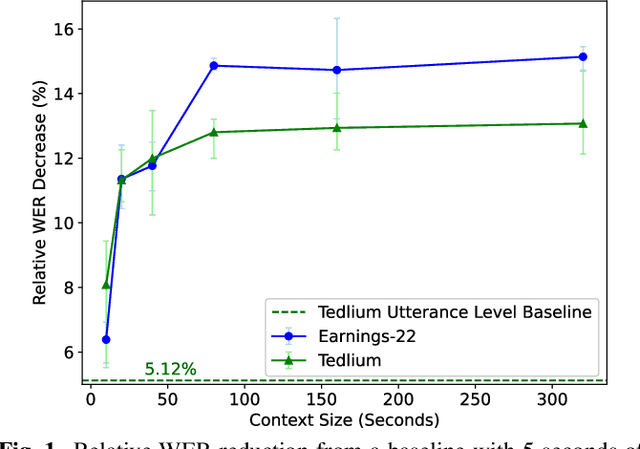


For the task of speech recognition, the use of more than 30 seconds of acoustic context during training is uncommon, and under-investigated in literature. In this work, we examine the effect of scaling the sequence length used to train/evaluate (dense-attention based) acoustic and language models on speech recognition performance. For these experiments a dataset of roughly 100,000 pseudo-labelled Spotify podcasts is used, with context lengths of 5 seconds to 1 hour being explored. Zero-shot evaluations on long-format datasets Earnings-22 and Tedlium demonstrate a benefit from training with around 80 seconds of acoustic context, showing up to a 14.9% relative improvement from a limited context baseline. Furthermore, we perform a system combination with long-context transformer language models via beam search for a fully long-context ASR system, with results that are competitive with the current state-of-the-art.