 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaRVL-QA: A Benchmark for Mathematical Reasoning over Visual Landscapes
Aug 24, 2025A key frontier for Multimodal Large Language Models (MLLMs) is the ability to perform deep mathematical and spatial reasoning directly from images, moving beyond their established success in semantic description. Mathematical surface plots provide a rigorous testbed for this capability, as they isolate the task of reasoning from the semantic noise common in natural images. To measure progress on this frontier, we introduce MaRVL-QA (Mathematical Reasoning over Visual Landscapes), a new benchmark designed to quantitatively evaluate these core reasoning skills. The benchmark comprises two novel tasks: Topological Counting, identifying and enumerating features like local maxima; and Transformation Recognition, recognizing applied geometric transformations. Generated from a curated library of functions with rigorous ambiguity filtering, our evaluation on MaRVL-QA reveals that even state-of-the-art MLLMs struggle significantly, often resorting to superficial heuristics instead of robust spatial reasoning. MaRVL-QA provides a challenging new tool for the research community to measure progress, expose model limitations, and guide the development of MLLMs with more profound reasoning abilities.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
A Community-Centric Perspective for Characterizing and Detecting Anti-Asian Violence-Provoking Speech
Jul 21, 2024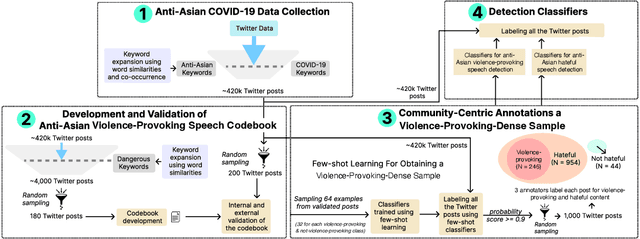



Violence-provoking speech -- speech that implicitly or explicitly promotes violence against the members of the targeted community, contributed to a massive surge in anti-Asian crimes during the pandemic. While previous works have characterized and built tools for detecting other forms of harmful speech, like fear speech and hate speech, our work takes a community-centric approach to studying anti-Asian violence-provoking speech. Using data from ~420k Twitter posts spanning a 3-year duration (January 1, 2020 to February 1, 2023), we develop a codebook to characterize anti-Asian violence-provoking speech and collect a community-crowdsourced dataset to facilitate its large-scale detection using state-of-the-art classifiers. We contrast the capabilities of natural language processing classifiers, ranging from BERT-based to LLM-based classifiers, in detecting violence-provoking speech with their capabilities to detect anti-Asian hateful speech. In contrast to prior work that has demonstrated the effectiveness of such classifiers in detecting hateful speech ($F_1 = 0.89$), our work shows that accurate and reliable detection of violence-provoking speech is a challenging task ($F_1 = 0.69$). We discuss the implications of our findings, particularly the need for proactive interventions to support Asian communities during public health crises. The resources related to the study are available at https://claws-lab.github.io/violence-provoking-speech/.