 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVFHQ: A High-Quality Dataset and Benchmark for Video Face Super-Resolution
May 06, 2022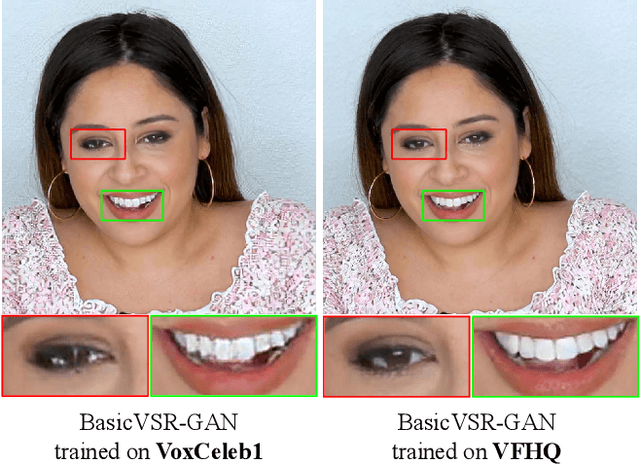
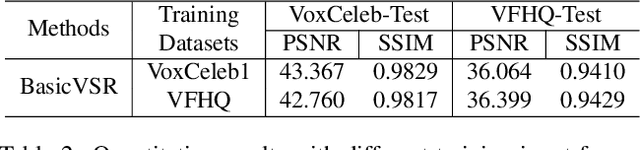


Most of the existing video face super-resolution (VFSR) methods are trained and evaluated on VoxCeleb1, which is designed specifically for speaker identification and the frames in this dataset are of low quality. As a consequence, the VFSR models trained on this dataset can not output visual-pleasing results. In this paper, we develop an automatic and scalable pipeline to collect a high-quality video face dataset (VFHQ), which contains over $16,000$ high-fidelity clips of diverse interview scenarios. To verify the necessity of VFHQ, we further conduct experiments and demonstrate that VFSR models trained on our VFHQ dataset can generate results with sharper edges and finer textures than those trained on VoxCeleb1. In addition, we show that the temporal information plays a pivotal role in eliminating video consistency issues as well as further improving visual performance. Based on VFHQ, by analyzing the benchmarking study of several state-of-the-art algorithms under bicubic and blind settings. See our project page: https://liangbinxie.github.io/projects/vfhq
Towards Vivid and Diverse Image Colorization with Generative Color Prior
Aug 19, 2021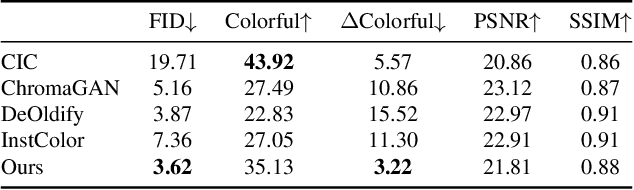
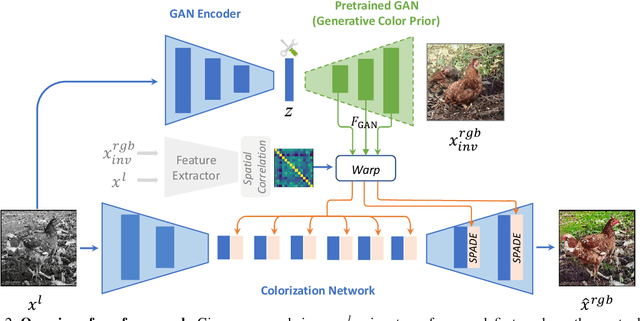


Colorization has attracted increasing interest in recent years. Classic reference-based methods usually rely on external color images for plausible results. A large image database or online search engine is inevitably required for retrieving such exemplars. Recent deep-learning-based methods could automatically colorize images at a low cost. However, unsatisfactory artifacts and incoherent colors are always accompanied. In this work, we aim at recovering vivid colors by leveraging the rich and diverse color priors encapsulated in a pretrained Generative Adversarial Networks (GAN). Specifically, we first "retrieve" matched features (similar to exemplars) via a GAN encoder and then incorporate these features into the colorization process with feature modulations. Thanks to the powerful generative color prior and delicate designs, our method could produce vivid colors with a single forward pass. Moreover, it is highly convenient to obtain diverse results by modifying GAN latent codes. Our method also inherits the merit of interpretable controls of GANs and could attain controllable and smooth transitions by walking through GAN latent space. Extensive experiments and user studies demonstrate that our method achieves superior performance than previous works.
Towards Real-World Blind Face Restoration with Generative Facial Prior
Jan 11, 2021
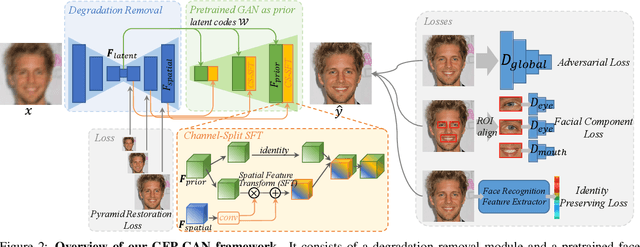


Blind face restoration usually relies on facial priors, such as facial geometry prior or reference prior, to restore realistic and faithful details. However, very low-quality inputs cannot offer accurate geometric prior while high-quality references are inaccessible, limiting the applicability in real-world scenarios. In this work, we propose GFP-GAN that leverages rich and diverse priors encapsulated in a pretrained face GAN for blind face restoration. This Generative Facial Prior (GFP) is incorporated into the face restoration process via novel channel-split spatial feature transform layers, which allow our method to achieve a good balance of realness and fidelity. Thanks to the powerful generative facial prior and delicate designs, our GFP-GAN could jointly restore facial details and enhance colors with just a single forward pass, while GAN inversion methods require expensive image-specific optimization at inference. Extensive experiments show that our method achieves superior performance to prior art on both synthetic and real-world datasets.
Dual Semantic Fusion Network for Video Object Detection
Sep 16, 2020
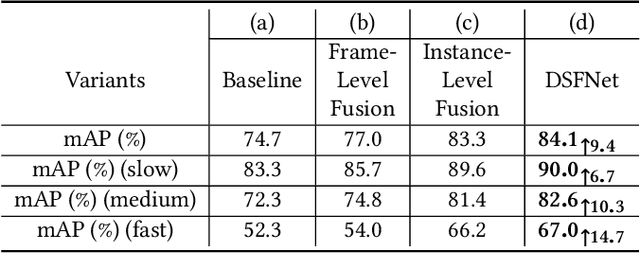
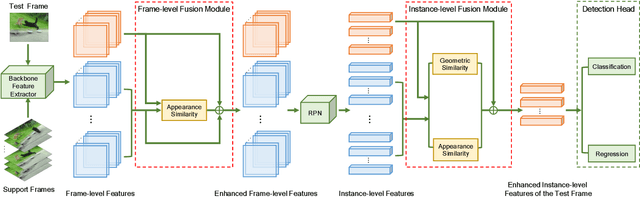
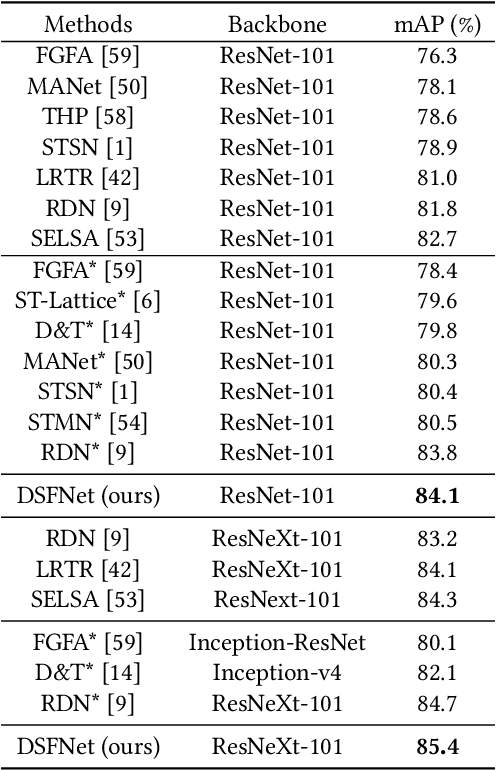
Video object detection is a tough task due to the deteriorated quality of video sequences captured under complex environments. Currently, this area is dominated by a series of feature enhancement based methods, which distill beneficial semantic information from multiple frames and generate enhanced features through fusing the distilled information. However, the distillation and fusion operations are usually performed at either frame level or instance level with external guidance using additional information, such as optical flow and feature memory. In this work, we propose a dual semantic fusion network (abbreviated as DSFNet) to fully exploit both frame-level and instance-level semantics in a unified fusion framework without external guidance. Moreover, we introduce a geometric similarity measure into the fusion process to alleviate the influence of information distortion caused by noise. As a result, the proposed DSFNet can generate more robust features through the multi-granularity fusion and avoid being affected by the instability of external guidance. To evaluate the proposed DSFNet, we conduct extensive experiments on the ImageNet VID dataset. Notably, the proposed dual semantic fusion network achieves, to the best of our knowledge, the best performance of 84.1\% mAP among the current state-of-the-art video object detectors with ResNet-101 and 85.4\% mAP with ResNeXt-101 without using any post-processing steps.
* 9 pages,6 figures
Disentangled Makeup Transfer with Generative Adversarial Network
Jul 02, 2019



Facial makeup transfer is a widely-used technology that aims to transfer the makeup style from a reference face image to a non-makeup face. Existing literature leverage the adversarial loss so that the generated faces are of high quality and realistic as real ones, but are only able to produce fixed outputs. Inspired by recent advances in disentangled representation, in this paper we propose DMT (Disentangled Makeup Transfer), a unified generative adversarial network to achieve different scenarios of makeup transfer. Our model contains an identity encoder as well as a makeup encoder to disentangle the personal identity and the makeup style for arbitrary face images. Based on the outputs of the two encoders, a decoder is employed to reconstruct the original faces. We also apply a discriminator to distinguish real faces from fake ones. As a result, our model can not only transfer the makeup styles from one or more reference face images to a non-makeup face with controllable strength, but also produce various outputs with styles sampled from a prior distribution. Extensive experiments demonstrate that our model is superior to existing literature by generating high-quality results for different scenarios of makeup transfer.
Show, Attend and Translate: Unpaired Multi-Domain Image-to-Image Translation with Visual Attention
Nov 19, 2018

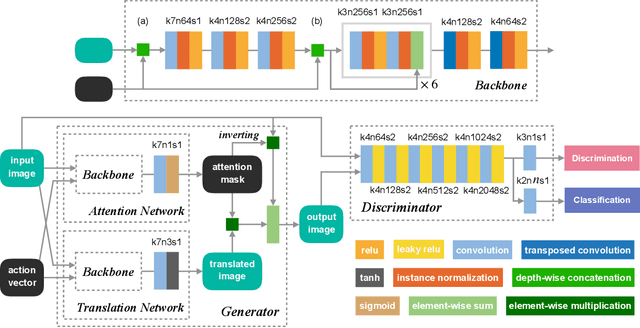

Recently unpaired multi-domain image-to-image translation has attracted great interests and obtained remarkable progress, where a label vector is utilized to indicate multi-domain information. In this paper, we propose SAT (Show, Attend and Translate), an unified and explainable generative adversarial network equipped with visual attention that can perform unpaired image-to-image translation for multiple domains. By introducing an action vector, we treat the original translation tasks as problems of arithmetic addition and subtraction. Visual attention is applied to guarantee that only the regions relevant to the target domains are translated. Extensive experiments on a facial attribute dataset demonstrate the superiority of our approach and the generated attention masks better explain what SAT attends when translating images.
Multi-Task Label Embedding for Text Classification
Oct 17, 2017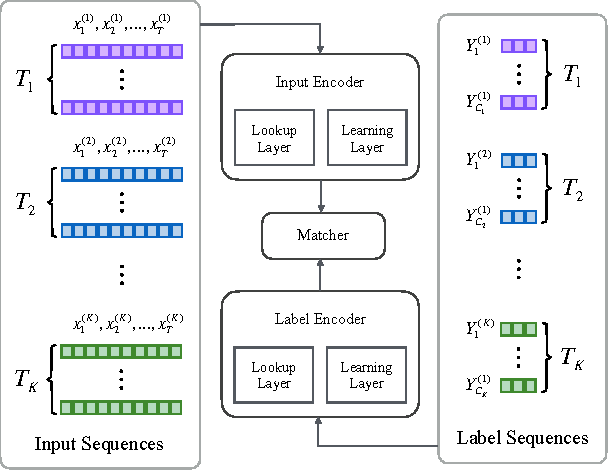
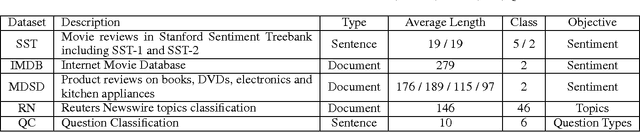
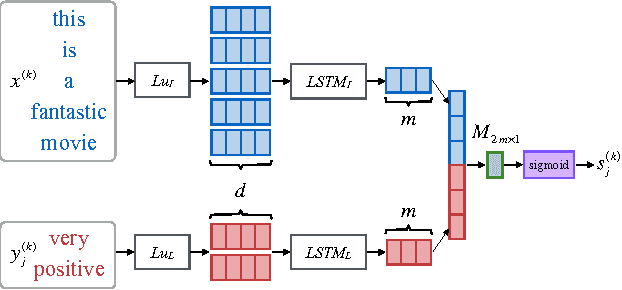

Multi-task learning in text classification leverages implicit correlations among related tasks to extract common features and yield performance gains. However, most previous works treat labels of each task as independent and meaningless one-hot vectors, which cause a loss of potential information and makes it difficult for these models to jointly learn three or more tasks. In this paper, we propose Multi-Task Label Embedding to convert labels in text classification into semantic vectors, thereby turning the original tasks into vector matching tasks. We implement unsupervised, supervised and semi-supervised models of Multi-Task Label Embedding, all utilizing semantic correlations among tasks and making it particularly convenient to scale and transfer as more tasks are involved. Extensive experiments on five benchmark datasets for text classification show that our models can effectively improve performances of related tasks with semantic representations of labels and additional information from each other.
A Generalized Recurrent Neural Architecture for Text Classification with Multi-Task Learning
Jul 10, 2017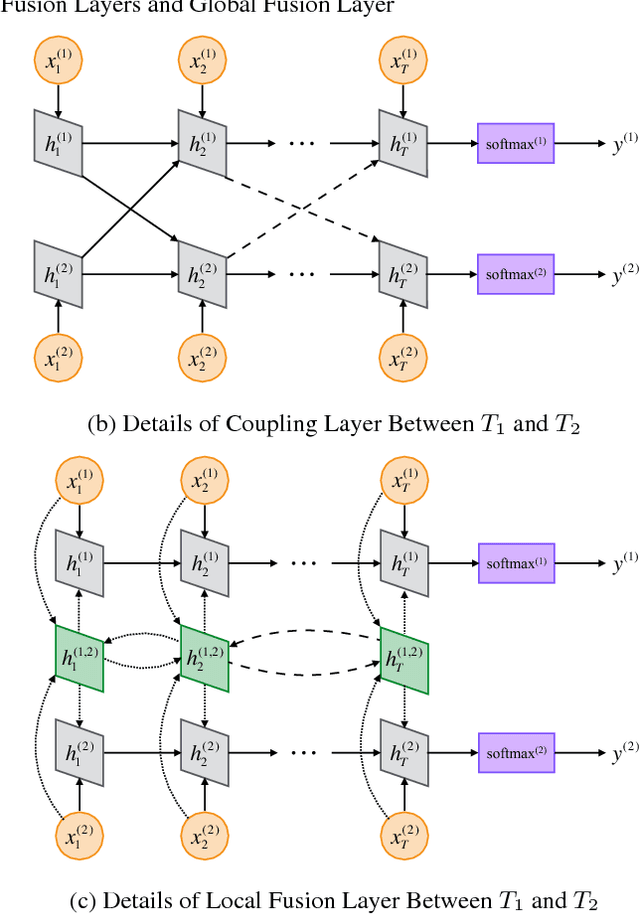
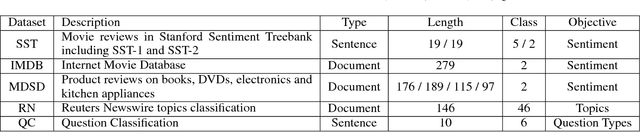
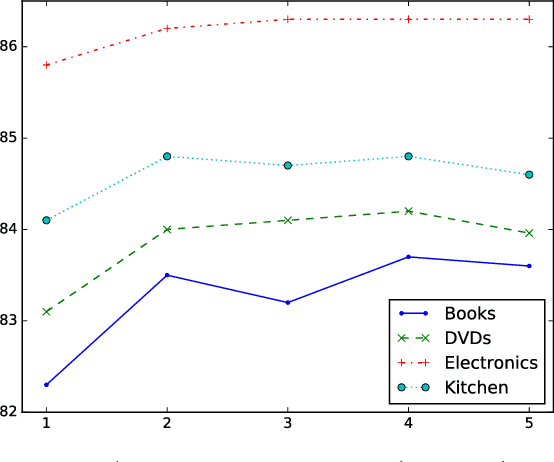

Multi-task learning leverages potential correlations among related tasks to extract common features and yield performance gains. However, most previous works only consider simple or weak interactions, thereby failing to model complex correlations among three or more tasks. In this paper, we propose a multi-task learning architecture with four types of recurrent neural layers to fuse information across multiple related tasks. The architecture is structurally flexible and considers various interactions among tasks, which can be regarded as a generalized case of many previous works. Extensive experiments on five benchmark datasets for text classification show that our model can significantly improve performances of related tasks with additional information from others.
OMNIRank: Risk Quantification for P2P Platforms with Deep Learning
Apr 27, 2017

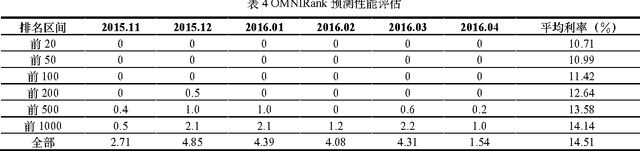
P2P lending presents as an innovative and flexible alternative for conventional lending institutions like banks, where lenders and borrowers directly make transactions and benefit each other without complicated verifications. However, due to lack of specialized laws, delegated monitoring and effective managements, P2P platforms may spawn potential risks, such as withdraw failures, investigation involvements and even runaway bosses, which cause great losses to lenders and are especially serious and notorious in China. Although there are abundant public information and data available on the Internet related to P2P platforms, challenges of multi-sourcing and heterogeneity matter. In this paper, we promote a novel deep learning model, OMNIRank, which comprehends multi-dimensional features of P2P platforms for risk quantification and produces scores for ranking. We first construct a large-scale flexible crawling framework and obtain great amounts of multi-source heterogeneous data of domestic P2P platforms since 2007 from the Internet. Purifications like duplication and noise removal, null handing, format unification and fusion are applied to improve data qualities. Then we extract deep features of P2P platforms via text comprehension, topic modeling, knowledge graph and sentiment analysis, which are delivered as inputs to OMNIRank, a deep learning model for risk quantification of P2P platforms. Finally, according to rankings generated by OMNIRank, we conduct flourish data visualizations and interactions, providing lenders with comprehensive information supports, decision suggestions and safety guarantees.