 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Study of Neighbor-based Methods for Local Outlier Detection
May 29, 2024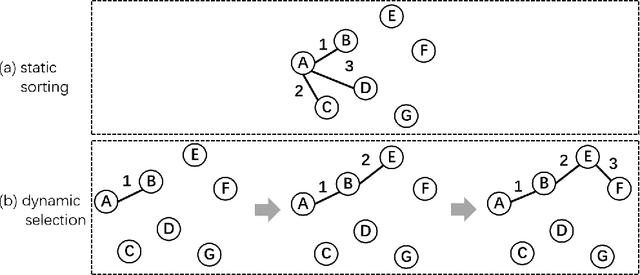


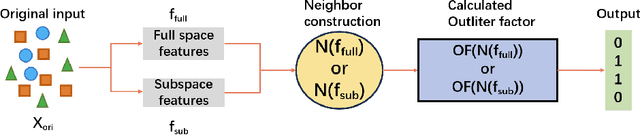
The neighbor-based method has become a powerful tool to handle the outlier detection problem, which aims to infer the abnormal degree of the sample based on the compactness of the sample and its neighbors. However, the existing methods commonly focus on designing different processes to locate outliers in the dataset, while the contributions of different types neighbors to outlier detection has not been well discussed. To this end, this paper studies the neighbor in the existing outlier detection algorithms and a taxonomy is introduced, which uses the three-level components of information, neighbor and methodology to define hybrid methods. This taxonomy can serve as a paradigm where a novel neighbor-based outlier detection method can be proposed by combining different components in this taxonomy. A large number of comparative experiments were conducted on synthetic and real-world datasets in terms of performance comparison and case study, and the results show that reverse K-nearest neighbor based methods achieve promising performance and dynamic selection method is suitable for working in high-dimensional space. Notably, it is verified that rationally selecting components from this taxonomy may create an algorithms superior to existing methods.
OMNIRank: Risk Quantification for P2P Platforms with Deep Learning
Apr 27, 2017

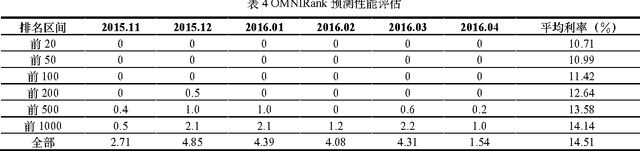
P2P lending presents as an innovative and flexible alternative for conventional lending institutions like banks, where lenders and borrowers directly make transactions and benefit each other without complicated verifications. However, due to lack of specialized laws, delegated monitoring and effective managements, P2P platforms may spawn potential risks, such as withdraw failures, investigation involvements and even runaway bosses, which cause great losses to lenders and are especially serious and notorious in China. Although there are abundant public information and data available on the Internet related to P2P platforms, challenges of multi-sourcing and heterogeneity matter. In this paper, we promote a novel deep learning model, OMNIRank, which comprehends multi-dimensional features of P2P platforms for risk quantification and produces scores for ranking. We first construct a large-scale flexible crawling framework and obtain great amounts of multi-source heterogeneous data of domestic P2P platforms since 2007 from the Internet. Purifications like duplication and noise removal, null handing, format unification and fusion are applied to improve data qualities. Then we extract deep features of P2P platforms via text comprehension, topic modeling, knowledge graph and sentiment analysis, which are delivered as inputs to OMNIRank, a deep learning model for risk quantification of P2P platforms. Finally, according to rankings generated by OMNIRank, we conduct flourish data visualizations and interactions, providing lenders with comprehensive information supports, decision suggestions and safety guarantees.