 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Study of Neighbor-based Methods for Local Outlier Detection
Paper and Code
May 29, 2024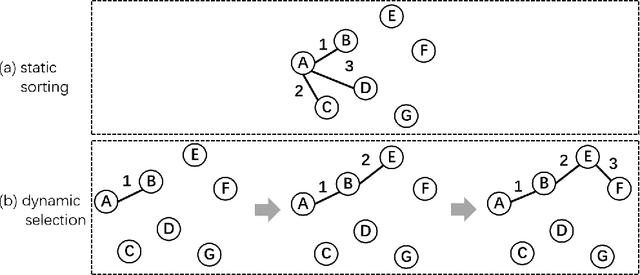


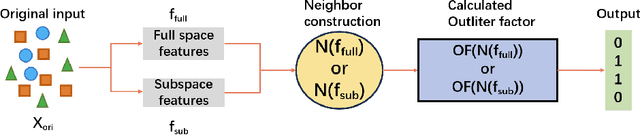
The neighbor-based method has become a powerful tool to handle the outlier detection problem, which aims to infer the abnormal degree of the sample based on the compactness of the sample and its neighbors. However, the existing methods commonly focus on designing different processes to locate outliers in the dataset, while the contributions of different types neighbors to outlier detection has not been well discussed. To this end, this paper studies the neighbor in the existing outlier detection algorithms and a taxonomy is introduced, which uses the three-level components of information, neighbor and methodology to define hybrid methods. This taxonomy can serve as a paradigm where a novel neighbor-based outlier detection method can be proposed by combining different components in this taxonomy. A large number of comparative experiments were conducted on synthetic and real-world datasets in terms of performance comparison and case study, and the results show that reverse K-nearest neighbor based methods achieve promising performance and dynamic selection method is suitable for working in high-dimensional space. Notably, it is verified that rationally selecting components from this taxonomy may create an algorithms superior to existing methods.