 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNABERT-S: Learning Species-Aware DNA Embedding with Genome Foundation Models
Feb 15, 2024



Effective DNA embedding remains crucial in genomic analysis, particularly in scenarios lacking labeled data for model fine-tuning, despite the significant advancements in genome foundation models. A prime example is metagenomics binning, a critical process in microbiome research that aims to group DNA sequences by their species from a complex mixture of DNA sequences derived from potentially thousands of distinct, often uncharacterized species. To fill the lack of effective DNA embedding models, we introduce DNABERT-S, a genome foundation model that specializes in creating species-aware DNA embeddings. To encourage effective embeddings to error-prone long-read DNA sequences, we introduce Manifold Instance Mixup (MI-Mix), a contrastive objective that mixes the hidden representations of DNA sequences at randomly selected layers and trains the model to recognize and differentiate these mixed proportions at the output layer. We further enhance it with the proposed Curriculum Contrastive Learning (C$^2$LR) strategy. Empirical results on 18 diverse datasets showed DNABERT-S's remarkable performance. It outperforms the top baseline's performance in 10-shot species classification with just a 2-shot training while doubling the Adjusted Rand Index (ARI) in species clustering and substantially increasing the number of correctly identified species in metagenomics binning. The code, data, and pre-trained model are publicly available at https://github.com/Zhihan1996/DNABERT_S.
Comparison and Benchmark of Graph Clustering Algorithms
May 10, 2020
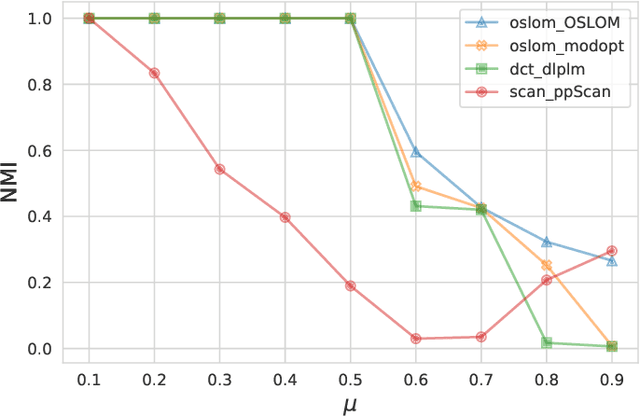
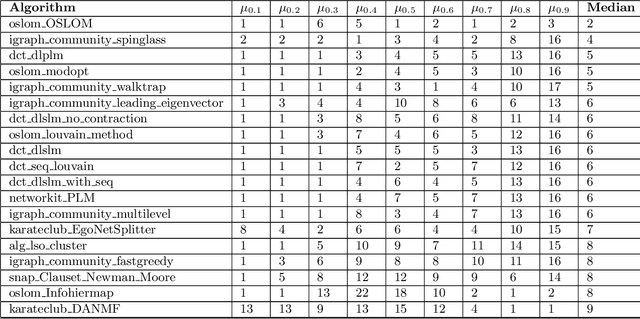
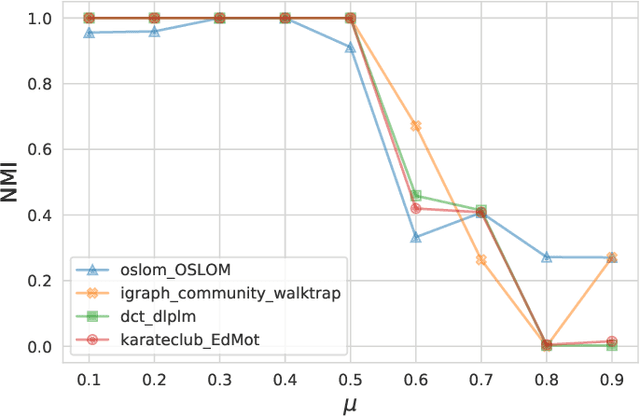
Graph clustering is widely used in analysis of biological networks, social networks and etc. For over a decade many graph clustering algorithms have been published, however a comprehensive and consistent performance comparison is not available. In this paper we benchmarked more than 70 graph clustering programs to evaluate their runtime and quality performance for both weighted and unweighted graphs. We also analyzed the characteristics of ground truth that affects the performance. Our work is capable to not only supply a start point for engineers to select clustering algorithms but also could provide a viewpoint for researchers to design new algorithms.