 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMode-Assisted Unsupervised Learning of Restricted Boltzmann Machines
Jan 19, 2020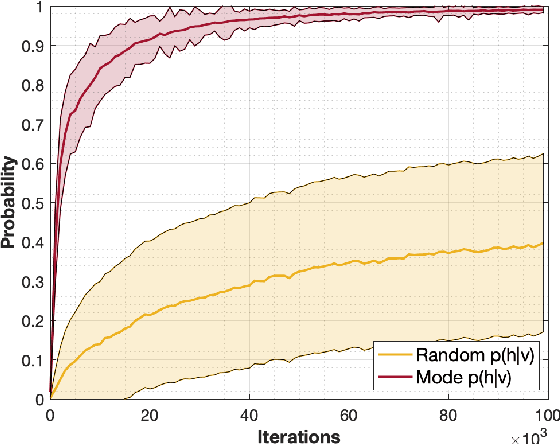
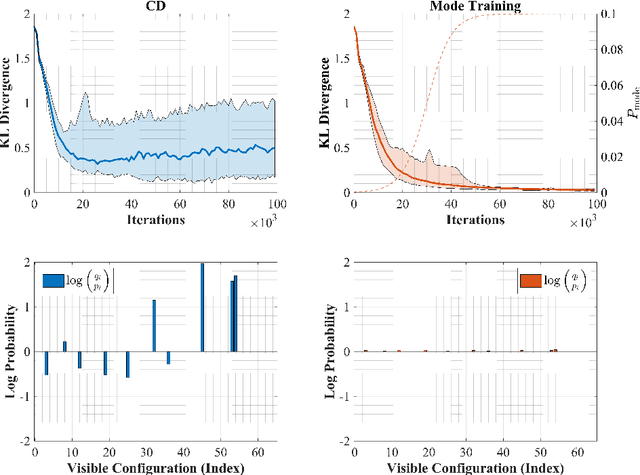
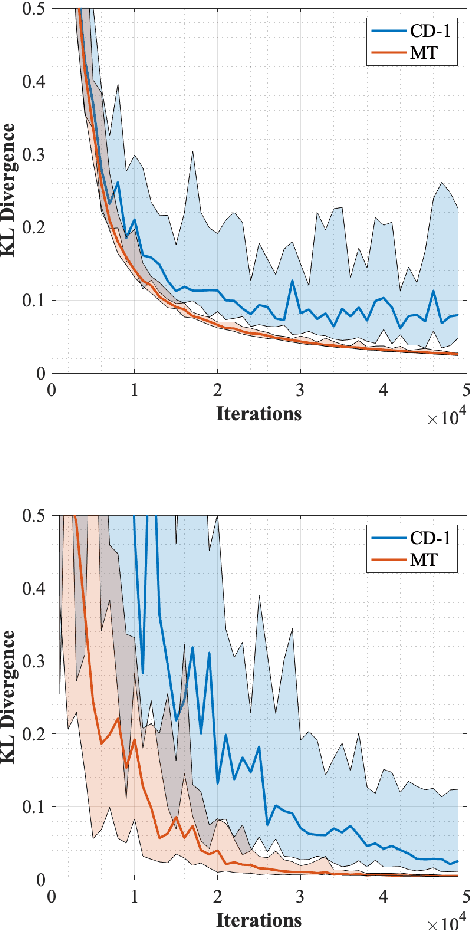
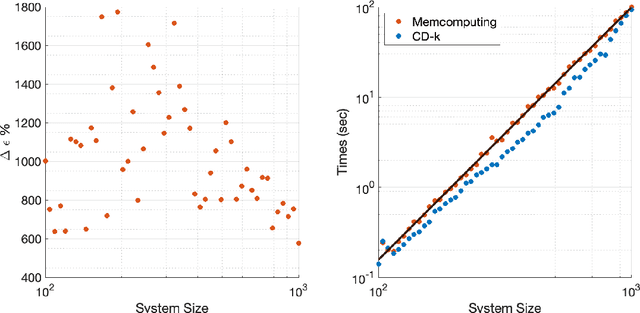
Restricted Boltzmann machines (RBMs) are a powerful class of generative models, but their training requires computing a gradient that, unlike supervised backpropagation on typical loss functions, is notoriously difficult even to approximate. Here, we show that properly combining standard gradient updates with an off-gradient direction, constructed from samples of the RBM ground state (mode), improves their training dramatically over traditional gradient methods. This approach, which we call mode training, promotes faster training and stability, in addition to lower converged relative entropy (KL divergence). Along with the proofs of stability and convergence of this method, we also demonstrate its efficacy on synthetic datasets where we can compute KL divergences exactly, as well as on a larger machine learning standard, MNIST. The mode training we suggest is quite versatile, as it can be applied in conjunction with any given gradient method, and is easily extended to more general energy-based neural network structures such as deep, convolutional and unrestricted Boltzmann machines.